> 一份2021年03月04日~03月05日的信息流提炼 ### 每天学点AI #### 用Alteryx学习多元回归分析 原文:[[ド素人]Alteryxで重回帰分析を勉強してみた #Alteryx](https://dev.classmethod.jp/articles/alteryx-multiple-linear-regression-super-beginner/) 多元回归分析:解释变量复数存在的回归分析。单一回归分析考察的是客观变量和解释变量之间的一对一关系,而多元回归分析考察的是哪些变量可以解释客观变量。 我认为多元回归分析是探索哪些变量可以解释目标变量的一种方法。 Sample数据: - 用户调查问卷: 性别,年龄,住所,第几次购入,商品说明是否清晰,服务满意度(1~5),对价格是否满意,对发送速度是否满意.... - 用户累计购买额 分析目的 - 影响购买额变化的因素 ##### Alteryx流程  Input工具: 选择Excel文件 ↓ JOIN工具: 根据用户ID结合调查问卷与购买数据 ↓ SELECT工具: 数据类型转换 ↓ 预测工具: 选择线性回归模型,目标数据设置为购买数据 输出报告(输出标记为**R**的是分析完成后的模型数据) 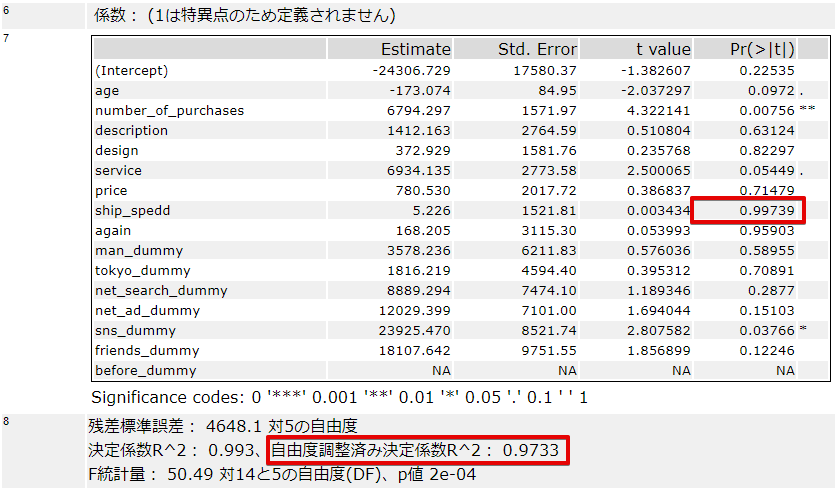 为了进一步看懂报告,并且根据结构进一步优化分析模型,需要掌握其他回归模型相关的知识... 例如下面的参考资料。 > 如何解读低R方和低P值的回归模型?([How to Interpret a Regression Model with Low R-squared and Low P values](https://blog.minitab.com/blog/adventures-in-statistics-2/how-to-interpret-a-regression-model-with-low-r-squared-and-low-p-values)) > 在回归分析中,你希望你的回归模型有显著的变量,并产生一个高R平方值。这种**低P值/高R2**的组合表明,预测因素的变化与响应变量的变化有关,你的模型可以解释很多响应的变异性。 因此实际调试的时候,首先可以去掉`Pr`很高的`ship_spedd`(发货速度)项目,因为即使继续优化这方面可能对购买额也不会有太大影响。 另外`R2`很接近1,当R2 > 0.7时说明数据较为准确,R2>0.9时是比较准确。 (当R2较低时,解决方法可以是给数据加更多的变量 。在其他情况下,数据中包含了固有的较多的不可解释的变异性。例如,许多心理学研究的R平方值都小于50%,因为人是相当不可预测的。) 最后通过相关系数的`t value` 也可以看出,哪些项目是正相关,哪些项目是负相关。 ### 每天学点前端 #### vue性能优化 原文:[揭秘 Vue.js 九个性能优化技巧](https://juejin.cn/post/6922641008106668045) 1. **使用函数式组件替代对象类型组件**。函数式组件也不会有状态,不会有响应式数据,生命周期钩子函数这些东西。 2. **子组件拆分**。Vue 的更新是组件粒度的,当数据修改导致了父组件的重新渲染时,子组件不会重新渲染从而节省开销。 3. **使用局部变量**。每次访问 `this.var` 的时候,由于 `this.var` 是一个响应式对象,所以会触发它的 `getter`,进而会执行依赖收集相关逻辑代码。类似的逻辑执行多了,像示例这样,几百次循环更新几百个组件,每个组件触发 `computed` 重新计算,然后又多次执行依赖收集相关逻辑,性能自然就下降了。 - `method(){ cmd this.var...cmd this.var } ` →`method({ var }){ cmd var...cmd var }` 4. **使用 `v-show` 复用 DOM**。`v-if` 不断删除和创建函数新的 DOM,`v-show` 仅仅是在更新现有 DOM 的显隐值,所以 `v-show` 的开销要比 `v-if` 小的多,当其内部 DOM 结构越复杂,性能的差异就会越大。 5. **使用 `KeepAlive` 组件缓存 DOM** ←在保持PWA应用历史页缓存的需求时有用到过这个 6. **使用 `Deferred` 组件延时分批渲染组件**。当有渲染耗时的组件,使用 `Deferred` 做渐进式渲染是不错的注意,它能避免一次 `render` 由于 JS 执行时间过长导致渲染卡住的现象。 7. **使用 `Time slicing` 时间片切割技术**。分时间片提交数据,当一次性提交数据过多,JS 一直长时间运行会阻塞 UI 线程, loading 动画无法展示。 8. **使用 Non-reactive data 非响应式数据**。把新提交的数据中的属性 `data.configurable` 设置为 `false`,这样内部在 `walk` 时通过 `Object.keys(obj)` 获取对象属性数组会忽略 `data`,也就不会为 `data` 这个属性 `defineReactive`,由于 `data` 指向的是一个对象,这样也就会减少递归响应式的逻辑,相当于减少了这部分的性能损耗。数据量越大,这种优化的效果就会更明显。 9. **使用 `Virtual scrolling` 虚拟滚动组件**。虚拟滚动的实现方式,是只渲染视口内的 DOM,这样总共渲染的 DOM 数量就比较少。 ### 今日收获 - 关于去中心化社交网络的HN评论 - discord最初为游戏玩家而存在。Hipchat是为了做代码,Slack是为了管理人。Reddit是为了分享另类/新兴文化......简言之,我们不需要去中心化的社交网络,**我们需要的是产生网络的新文化,以及创造这种文化的勇气**。Gamers made discord a thing because it was for playing games. Hipchat was about making code, and Slack was a way to manage people. Reddit was for sharing alternative/emerging culture...Short version is, we don't need a decentralized social network, we need new culture that produces networks, and courage to create that culture. | [My personal wishlist for a decentralized social network](https://news.ycombinator.com/item?id=25731419) - 网络框架的便利性的另一面是在使用它们时可能会遇到的限制和风格上的不匹配。[REST Servers in Go: Part 3 - using a web framework](https://eli.thegreenplace.net/2021/rest-servers-in-go-part-3-using-a-web-framework/) ### 其他值得阅读 - [构建终身学习体系进行自我提升](https://www.bmpi.dev/self/build-personal-knowledge-system/) - 获取信息 → 知识内化 → 认知提高(输出&应用) → 智慧(时间) - [和菜头:碎片化生存](https://www.notion.so/5366f442d442467fa347634f9169d567) - 碎片化阅读(微博):反应胜过一切,表态高于一切 - 读书:持续专注在书页上,集中全部精力 - 恢复性训练:暂时屏蔽SNS,恢复长文本的阅读。 - > 这样停下来,才发现周围的世界已经发生了很大的改变。现在这世界基本上已经是一个由信息碎片所构成的大型显示屏,完整的信息已经非常少见。你所能知道的,只是此时此地此事的一瞬间。 > > 我观察到网络上的信息发布发生有以下规律: 1、信息的碎片程度加剧,人们倾向于消费越来越短的文字。 2、对于富媒体的消费需求增加,尤其是对图片、音频、视频的需求增长惊人。 3、信息达到用户的方式,Push和通知机制已经占据主流。 > > 碎片信息得以维系的机制是什么?这次答案变得很简单:一个巴普洛夫条件式的触发器---通知机制,加一个基于人性弱点建立的社交网络。