> 一份2021年03月09日的信息流提炼 ### 每天学点python #### 构建丰富的终端仪表盘 原文:[Building Rich Terminal Dashboards](https://news.ycombinator.com/item?id=26149488) ##### Rich库 [Rich](https://github.com/willmcgugan/rich)已经成为一种流行的美化CLI的方式。 安装:`pip install rich` ##### 布局API 示例:`python -m rich.layout` - 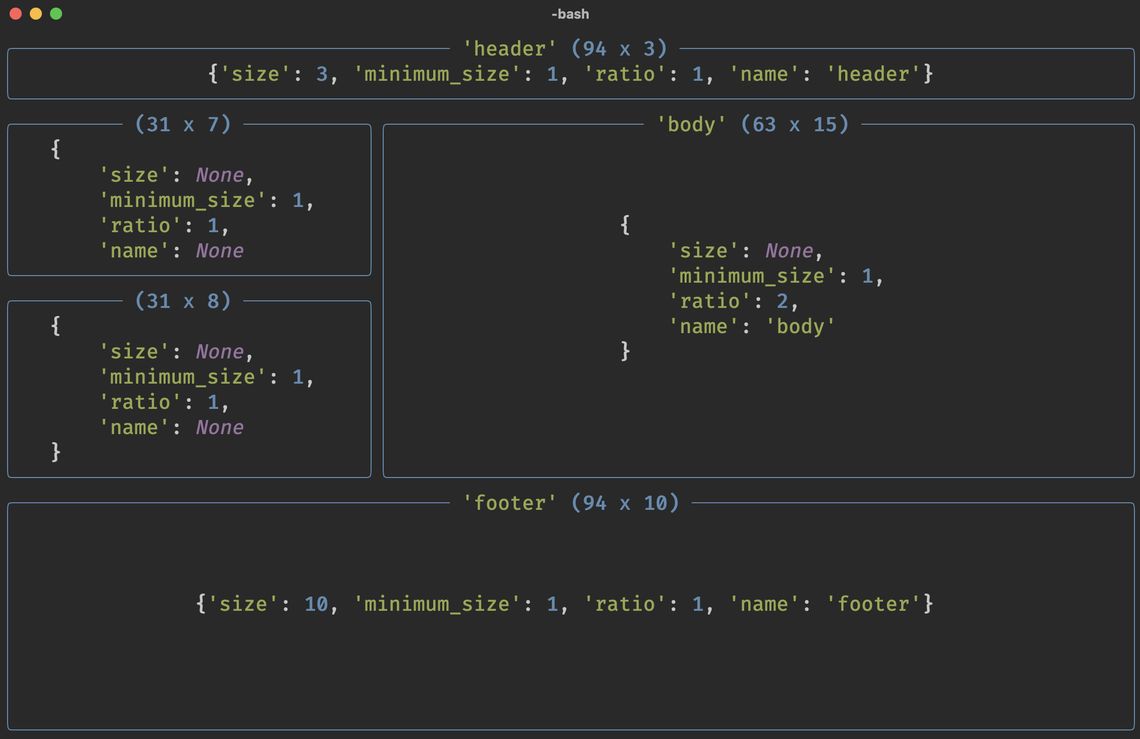 ※代码示例参照附录。 #### Python Web爬虫101 原文:[Web Scraping 101 with Python](https://news.ycombinator.com/item?id=26090243) HN评论的小技巧,用`pandas`直接获取网页的任意table标签内容: ```pyhon import pandas as pd dfs = pd.read_html(url) ``` ##### 基础 - 超文本传送协议HTTP。可以用`socket`手动实现HTTP的请求,另外还有专门的`urllib3`可以帮助实现。 - XPath: XPath是一种使用路径表达式来选择XML文档(或HTML文档)中的节点或节点集的技术。`pip install lxml` - `Requests` & `BeautifulSoup` 两个强大的库可以用来进行HTTP请求与解析 - `grequest`: 当请求数量过多时可以利用`grequest`进行异步请求。 ##### Web爬虫框架 - **Scrapy**:提供了许多异步下载网页、处理网页和保存网页的功能。它可以处理多线程、抓取(从一个链接到另一个链接找到网站中的每个URL的过程)、网站地图抓取等。 ##### Headless浏览器: Selenium Scrapy对于大规模的网页抓取任务来说是非常好的。然而,如果对象时一个用Javascript框架编写的单页应用程序,它是不够的,因为它无法渲染Javascript代码。 在某些情况下,涉及的异步HTTP调用太多,无法获得你想要的数据,在Headless浏览器中渲染页面可能会更容易。 ##### RoboBrowser RoboBrowser可以通过`Requests`和`BeautifulSoup`包装在一个易于使用的界面中来浏览网页。 它本身并不是一个Headless浏览器, 而是提供"类浏览器 "的执行环境。 ##### 总结 | Name | socket | urllib3 | requests | scrapy | selenium | | ---------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | | 易用性 | - - - | + + | + + + | + + | + | | 灵活性 | + + + | + + + | + + | + + + | + + + | | 执行速度 | + + + | + + | + + | + + + | + | | 常见用例 | 编写低级编程接口 | 需要对HTTP进行精细控制的高级应用(pip、aws客户端、请求、流媒体)。 | 调用API -简单的应用(就HTTP需求而言)。 | 抓取一个重要的网站列表 - 过滤、提取和加载抓取的数据。 | JS渲染-爬SPA -自动测试 -程序截图 | | Learn more | - [Official documentation](https://docs.python.org/3/library/socket.html) - [Great tutorial](https://realpython.com/python-sockets/) ???? | - [Official documentation](https://urllib3.readthedocs.io/en/latest/) - [PIP usage of urllib3](https://github.com/pypa/pip/search?q=urllib3&unscoped_q=urllib3), very interesting | - [Official documentation](https://github.com/psf/requests) - [Requests usage of urllib3](https://github.com/psf/requests/search?q=urllib3&unscoped_q=urllib3) | - [Official documentation](https://scrapy.org/) - [Scrapy overview](https://www.datacamp.com/community/tutorials/making-web-crawlers-scrapy-python) | - [Official documentation](https://www.seleniumhq.org/) - [Scraping SPA](https://www.scrapingbee.com/blog/scraping-single-page-applications/) | ### 每天学点算法 原文:(0) [数学,离一个程序员有多近?](https://juejin.cn/post/6918907811741040653#heading-9) (1)[【hash】哈希算法、哈希碰撞、一致性哈希]( https://blog.csdn.net/loulanyue_/article/details/96016393) (2) [Fibonacci Hashing & Fastest Hashtable](https://www.gohired.in/2018/07/31/fibonacci-hashing-fastest-hashtable/) #### Java算法运用 - **HashMap的扰动函数**: 当你有需要把数据散列分散到不同格子或者空间时,又不希望有太严重的碰撞,那么使用扰动函数就非常有必要了。比如你做的一个数据库路由,在分库分表时也是尽可能的要做到散列的。 - **斐波那契(Fibonacci)散列法**: 如果你的代码逻辑中需要存储类似 ThreadLocal 的数据结构,又不想有严重哈希碰撞,那么就可以使用 斐波那契(Fibonacci)散列法。其实除此之外还有,`除法散列法`、`平方散列法`、`随机数法`等。 - **梅森旋转算法(Mersenne twister)**: 梅森旋转算法是R、Python、Ruby、IDL、Free Pascal、PHP、Maple、Matlab、GNU多重精度运算库和GSL的默认伪随机数产生器。从C++11开始,C++也可以使用这种算法。在Boost C++,Glib和NAG数值库中,作为插件提供。 #### 哈希算法、哈希碰撞、一致性哈希 Hash,一般翻译做“散列”,也有直接音译为“哈希”的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。 简单的说就是**一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。** 哈希(Hash)算法,即散列函数。它是一种单向密码体制,即它是一个从明文到密文的不可逆的映射,只有加密过程,没有解密过程。同时,哈希函数可以将任意长度的输入经过变化以后得到固定长度的输出。哈希函数的这种单向特征和输出数据长度固定的特征使得它可以生成消息或者数据。 常用hash算法:MD4,MD5,SHA-1及其他 如果不同的输入得到了同一个哈希值,就发生了**"哈希碰撞**"(collision)。 ##### 斐波那契数列与斐波那契散列 斐波那契数列(Fibonacci sequence),又称[黄金分割](https://baike.baidu.com/item/黄金分割/115896)数列,因数学家莱昂纳多·斐波那契(Leonardoda Fibonacci)以兔子繁殖为例子而引入,故又称为“[兔子数列](https://baike.baidu.com/item/兔子数列/6849441)”。 在数学上,斐波那契数列以如下被以递推的方法定义:`*F*(0)=0,*F*(1)=1, *F*(n)=*F*(n - 1)+*F*(n - 2)(*n* ≥ 2,*n* ∈ N*)` 数列:0、1、1、2、3、5、8、13、21、34、55…… 越往后的每一个斐波那契数列都遵循黄金比率Φ=1.6180。 例如8/5=1.6,34/21=1.61,随着数字的增长,它的精度越来越高。 假设我们的哈希表是1024槽大,我们想把一个任意大的哈希值映射到这个范围内。我们要做的第一件事就是我们用上面的技巧把它映射到完整的64位数字范围。所以我们将传入的哈希值乘以 2^64 / Φ ≈ 11400714819323198485 ```c // 实现 ulong fibhash (ulong n, ulong mul = 11400714819323198485UL, ulong shift = 61UL) { return ( n * mul ) >> shift; } // 传入一些数字作为哈希值 fibhash(0) == 0 fibhash(8) == 7 fibhash(1) == 4 fibhash(9) == 4 fibhash(2) == 1 fibhash(10) == 1 fibhash(3) == 6 fibhash(11) == 6 fibhash(4) == 3 fibhash(12) == 3 fibhash(5) == 0 fibhash(13) == 0 fibhash(6) == 5 fibhash(14) == 5 fibhash(7) == 2 fibhash(15) == 2 fibhash(16) == 7 ``` 这给出了一个非常均匀的分布。数字0出现了三次 其他数字出现了两次 而且每一个数字都与上一个数字和下一个数字相去甚远。如果我们增加一个输入,输出就会有相当大的跳动。所以这开始看起来是一个很好的哈希函数。而且也是一个很好的方法,可以把一个较大范围的数字映射到0到7的范围内。 #### 实用Cython - DFA去趋势化分析 原文:[Practical Cython — Music Retrieval: Detrended Fluctuation Analysis (DFA)](https://towardsdatascience.com/practical-cython-music-retrieval-detrended-fluctuation-analysis-dfa-7935aa84e289) DFA也叫去趋势化方法,是一种广泛应用于时间序列分析的技术,从音乐到金融都有应用。 > 对于这种方法可以简单理解为,信号本身具有内在的某种联系,而由于采集到的信号存在外部的噪声使得信号内部的联系函数之上叠加了多项式趋势信号,使得信号内部联系无法明确找到,DFA方法通过滤去序列中的各阶趋势成分,有效避免由于噪声和信号的不稳定而表现出来的伪关联的干扰。 > > 去趋势化的原理便是通过对原数据的点状图图像减去一条拟合直线从而消去数据呈现出的趋势变化,这种方法可以呈现出数据的特征。具体实现的方法如下: > 利用最小二乘法得到图像趋势的拟合曲线,因为是点状图所构成的,因此用相应点的纵坐标值减去所得拟合曲线对应横坐标下的纵坐标值,即为去趋势化后的图像。 > > 参考:[脑电信号预处理(一)——去趋势化(Detrended fluctuation analysis)](https://blog.csdn.net/weixin_43361652/article/details/103180421) 数学上DFA可以分解和定义为四个步骤。 1. 计算由N个样本组成的信号x(t)的平均累积和Xt。 2. 将平均累积和Xt再划分为n个样本,对每个子样本计算一个最小平方线性拟合Yt。在不同的尺度上重复这个过程,即从把信号分成n个小样本到n个大样本。 3. 由此计算去趋势波动,作为平均累积总和Xt和拟合Yt之间的均方根偏差,在每个尺度上: Eq.1 以平均累积总和Xt和拟合Yt之间的均方根偏差计算的去趋势波动。 $$ F(n)=\sqrt{\frac{1}{N} \sum_{t=1}^{N}(Xt - Yt)^{2} } $$ 4. 将F(n)表示为n个样本数的对数函数,并找出指数行为(DFA-Hurst指数) ### 每天学点UIUX #### 如何成为一名自学成才的UI/UX设计师(2021) 原文:[How to become a self‑taught UI/UX designer (2021)](https://dribbble.com/stories/2021/02/04/how-to-become-ui-ux-designer) ##### 学习用户体验设计的基础知识 用户体验设计的重点是通过满足用户的需求和愿望,以及通过用户心理学来创造一个令人愉快的体验。 推荐Steve Krug的《Don't Make Me Think 》。Krug被广泛认为是用户体验设计的教父。 - **色彩理论** ([色とUI](https://www.infoq.com/jp/articles/Colors-UI/)) - 色彩感知是通过三种类型的锥体实现的。 - 色彩对比度 - 对比效果会对用户体验造成损害,下面重点介绍两个重要的例子。 一般来说,视野的任何范围都会倾向于在相邻区域产生互补色。 例如,一个灰色的正方形在被红色包围时,往往呈现绿色,而被绿色包围时,则呈现红色。 这种效果被称为同步色彩对比。 - 另外一个问题,对比度效应也就是色差。不同颜色的刺激不会投射到视网膜上的同一个点。 这种效果在紫红和蓝红的组合中最为明显。所以应该避开这些组合。 - **UI模式** [Design patterns](http://ui-patterns.com/patterns) - 用户输入 - 表单:密码强度显示,WYSIWYG,日历选择日期,输入反馈,自动保存,拖拽,行内说明帮助,剩余步骤,快捷键.... - 社区驱动:投票,标记&报告,评价,付费推广,wiki - 导航,菜单,内容展示(列表,卡片,幻灯片,日历,分类,分野,标签...) - **了解用户需求** ### 其他值得阅读 - 大脑最珍贵的资源: [The Brain’s Most Precious Resource](https://towardsdatascience.com/the-brains-most-precious-resource-7341b9fb6369) - 大型强子对撞机(LHC)是人类有史以来最复杂的机器之一。当它运行时,每秒钟都有大约10亿个粒子以接近光速的速度相互撞击,探测超越当前粒子物理学标准模型边缘的物理学。现在的计算设备都无法记录全部的数据。因此,在对数据进行任何分析之前,大量的数据都必须实时抛出。我们的大脑每天都面临着类似的挑战:认知处理和存储和计算时间一样,是大脑最宝贵的资源,对于通过进化而来的认知系统来说,简约地使用资源是生存的关键之一。 - 我们的注意力系统可以被认为是由**自下而上**和**自上而下**的控制构成的 - 自上而下的机制试图通过引导我们的注意力来落实我们的高层目标。 - 自下而上的机制会自动将你的注意力拉向一些在我们漫长的进化史上,值得注意的东西。无论是当街道上有一声巨大的爆炸声,黑暗中一个看起来像美洲豹的形状,还是在你旁边的桌子上有人叫你的名字。 - 在现代高科技社会,我们不断被注意力的争夺轰炸。正如《The Distracted Mind》中所阐述的那样,当古老的大脑不断尝试在指数级增长的信息环境中实现信息的最大化时,过多的任务切换机会就会成为一个巨大的问题,从而导致不断的分心、多任务尝试失败、贪得无厌的感觉、睡眠不足等等。由于复杂的任务通常分布在多个脑区,这种切换过程也相对缓慢,这也是为什么在不同的任务之间切换需要花费大量时间的原因,使得我们都在不断进行的多任务处理变得非常低效。 - 为什么软件项目需要的时间比你想象的要长: [ Why software projects take longer than you think: a statistical model (2019)](https://news.ycombinator.com/item?id=26366112) - > 人们能很好地估计出完成时间的中位数,但不能估计出平均值。 > 由于分布偏斜(对数-正态),平均数的结果比中位数差很多。 > > People estimate the median completion time well, but not the mean. > The mean turns out to be substantially worse than the median, due to the distribution being skewed (log-normally). > > 具有最大不确定性的任务(而是最大的规模)往往可以主导完成所有任务所需的平均时间。 > > Tasks with the most uncertainty (rather the biggest size) can often dominate the mean time it takes to complete all tasks. > > 完成一个我们一无所知的任务的平均时间实际上是无限的。 > > The mean time to complete a task we know nothing about is actually infinite. - 深度学习的数学工程: [The Mathematical Engineering of Deep Learning](https://deeplearningmath.org/) - 通往未来的道路。谷歌Brain的一年: [Paths to the Future: A Year at Google Brain](https://www.debugmind.com/2020/01/04/paths-to-the-future-a-year-at-google-brain/) - I’m interested in in **convex optimization**, a branch of computational mathematics concerned with making optimal choices. Convex optimization has many real-world applications—SpaceX uses it to land rockets, self-driving cars use it to track trajectories, financial companies use it to design investment portfolios, and, yes, machine learning engineers use it to train models. - 一周内创建SaaS:我是如何创建OnlineOrNot的。[Building a SaaS in one week: How I built OnlineOrNot](https://onlineornot.com/building-saas-in-one-week-how-built-onlineornot#docs) - 去中心化系统**IPFS**(存储文件、网站、应用、数据):[What is IPFS?](https://docs.ipfs.io/concepts/what-is-ipfs/) - 去中心化 - 支持弹性互联网。 - 使得审查内容变得更加困难。 - 本地联网或断网时利用。 - 内容定位:哈希值作为内容标识符。(可以防止篡改) - 访问示例:`/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Aardvark.html` ### 今日收获 - 亚里士多德曾经说过,好的艺术必须包含两个特点:出人意料和不可避免。 > Aristotle once said that **good art has to contain two features: it has to be surprising and inevitable**. In the moment, you want the audience to say, “wow.” But in retrospect, you want them to say, “of course, how could it have gone any other way?” Writing works in the same way. A good article is insightful because it presents a fresh way to think about the world. Then it sticks with the reader because in retrospect, the ideas feel as inevitable as a law of nature ### 附录:snippets - python rich ```python from rich import box from rich.console import Console, RenderGroup from rich.layout import Layout from rich.text import Text from rich.panel import Panel from rich.align import Align from rich.table import Table console = Console() layout = Layout() # Divide the "screen" in to three parts layout.split( Layout(name="header", size=3), Layout(ratio=1, name="main"), Layout(size=10, name="footer"), ) # Divide the "main" layout in to "side" and "body" layout["main"].split( Layout(name="side"), Layout(name="body", ratio=2), direction="horizontal" ) # update header contents text = Text("Hello, World!") text.stylize("bold magenta", 0, 6) # Divide the "side" layout in to two layout["side"].split(Layout(Panel("Hello, [b red]World", title="Side 1")), Layout(Panel("nothing", title="Side 2"))) # update body contents # https://github.com/willmcgugan/rich/blob/master/examples/fullscreen.py def make_sponsor_message() -> Panel: sponsor_message = Table.grid(padding=1) sponsor_message.add_column(style="green", justify="right") sponsor_message.add_column(no_wrap=True) sponsor_message.add_row( "Sponsor me", "[u blue link=https://github.com/sponsors/willmcgugan]https://github.com/sponsors/willmcgugan", ) intro_message = Text.from_markup( """Consider supporting my work via Github Sponsors (ask your company / organization), or buy me a coffee to say thanks. - Will McGugan""" ) message = Table.grid(padding=1) message.add_column() message.add_column(no_wrap=True) message.add_row(intro_message, sponsor_message) message_panel = Panel( Align.center( RenderGroup(intro_message, "\n", Align.center(sponsor_message)), vertical="middle", ), box=box.ROUNDED, padding=(1, 2), title="Body Block", border_style="bright_blue", ) return message_panel layout["body"].update(make_sponsor_message()) console.print(layout) ```