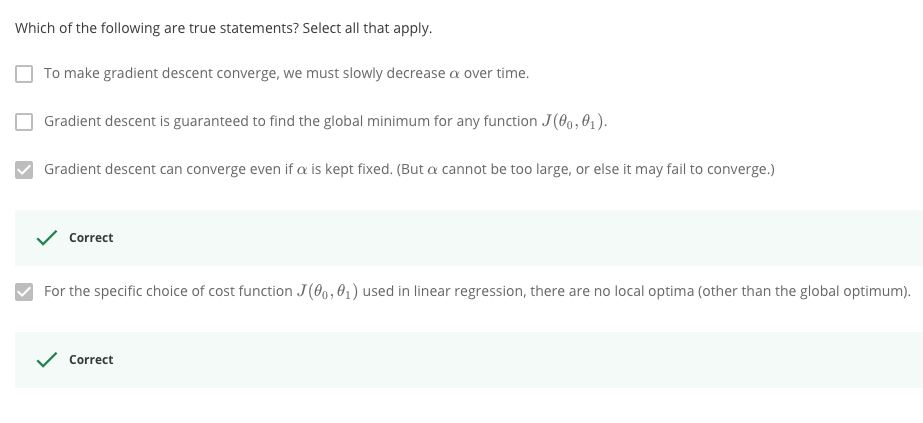
> 2021年04月01日信息消化 #### 每天学点机器学习 #### Gradient Descent 利用梯度下降简化代价函数。 假设有函数J(θ0,θ1....),并希望获得最小min J 这里为简化说明,限制只有θ0和θ1。 这时把代价函数想象成山丘,而自己站在山丘上的任意一点。需求是找到能最快能下山的方向。 <img src="https://i.loli.net/2021/04/01/9Ub2PGu1VckzydI.png" alt="image-20210401114143075" style="zoom: 30%;" /> ##### 梯度下降算法 我们的方法是取成本函数的导数(函数的切线)。切线的斜率就是该点的导数,它将为我们提供一个方向。我们沿着成本函数最陡峭的方向向下迈步。每一步的大小由参数α决定,它被称为学习率。 - α: learning rate 学习率 - $$\frac{\delta}{\delta\theta_j}$$: Derivative term导数 $$ repeat\ until\ convergence\ \{\theta_j := \theta_j - \alpha\frac{\delta}{\delta\theta_j}J(\theta_0,\theta_1)\} $$  例中越接近局部最小值效率越小,而α也自动取更小的步长。  ##### 随堂小测1 这里的重点就是每次迭代J时需要同时更新参数θ0和θ1 (simultaneously update)  ##### 随堂小测2 当θ1 为局部最优值(local optimum)时,切线水平导数为0,θ1 = θ1 + α * 0, 所以θ1不会变动。 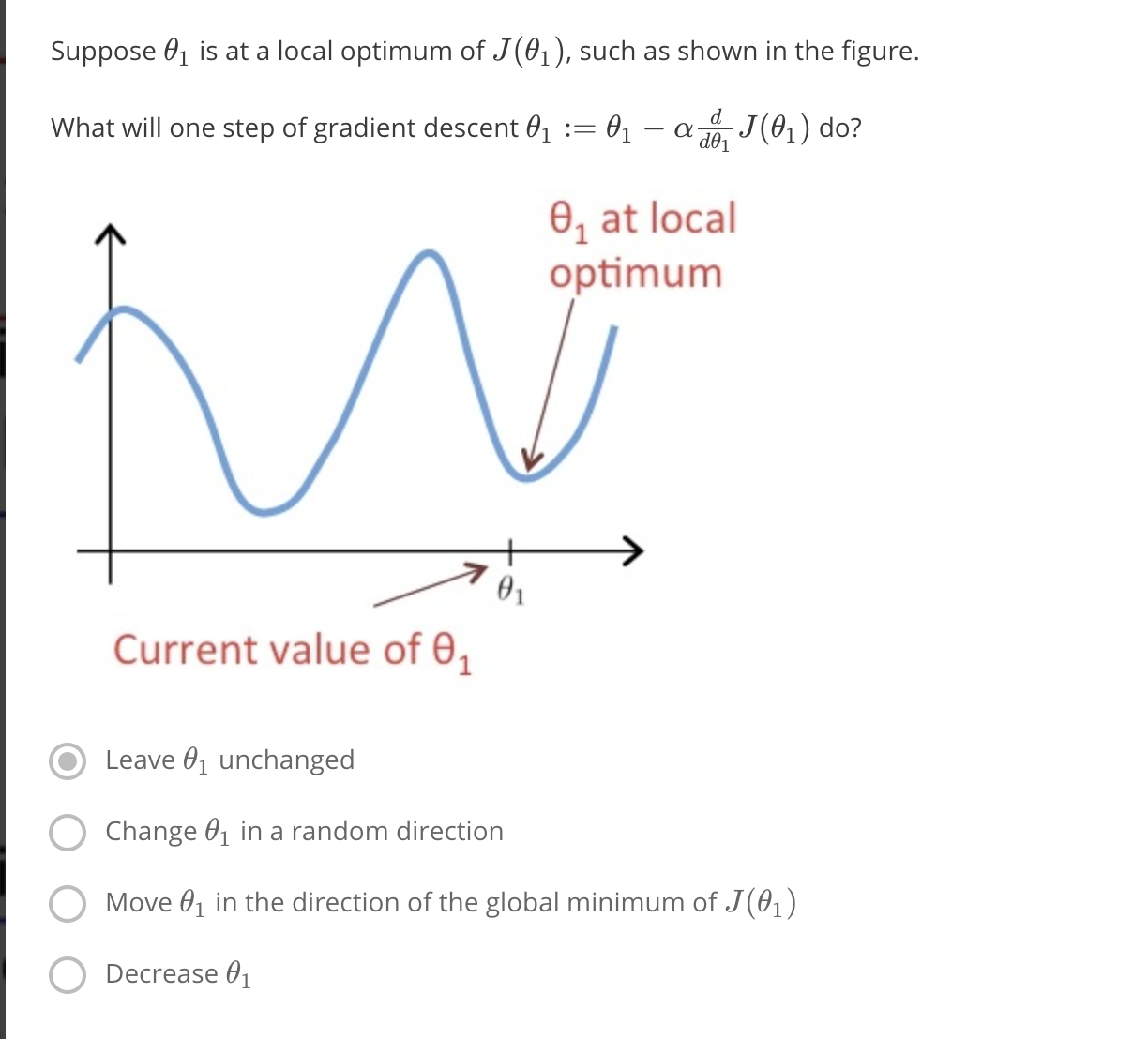 ##### 梯度下降在线性回归中的应用 梯度下降的一个问题是,它很容易受到局部最优值的影响。 当具体应用到线性回归的情况下,可以得出梯度下降方程的新形式。我们可以用我们的实际成本函数和实际假设函数代替,并将方程修改为 : repeat until convergence: { $$ θ_0:= θ_0−α\frac{1}{m}∑_{i=1}^m(h_θ(x_i)−y_i) $$ $$ θ_1:= θ_1−α\frac{1}{m}∑_{i=1}^m(h_θ(x_i)−y_i) $$ } 下面是一个推导的例子。 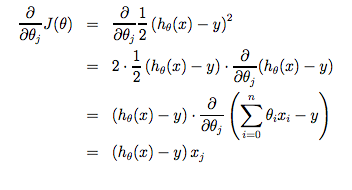 这一切的意义在于,如果我们从猜测我们的假设开始,然后反复应用这些梯度下降方程,我们的假设会变得越来越准确。 所以,这只是在原始成本函数J上的梯度下降,这种方法在每一步上都会查看整个训练数据的每一个例子,被称为批量梯度下降[**batch gradient descent]**。需要注意的是,虽然梯度下降法在一般情况下容易出现局部最小值,但我们在这里提出的线性回归优化问题只有一个全局最优值,没有其他局部最优值;因此梯度下降法总是收敛[**converges**](假设学习率α不是太大)到全局最小值。事实上,J是一个碗装二次函数[**convex quadratic function**]。下面是一个梯度下降的例子,它是为了最小化一个二次函数而运行的。 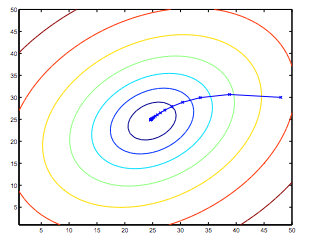 上面显示的椭圆是二次函数的轮廓。图中还显示了梯度下降的轨迹,初始化为(48,30)。图中的x(由直线连接)标志着梯度下降在收敛到最小值时所经历的θ的连续值。 ##### 随堂小测3