> 2021年07月08日信息消化 ### 一文了解预训练语言模型! [一文了解预训练语言模型!](https://mp.weixin.qq.com/s/YadLBWarQ7Hcft0ezxRdYA) 预训练属于迁移学习的范畴。 现有的神经网络在进行训练时,一般基于后向传播(Back Propagation,BP)算法,先对网络中的参数进行随机初始化,再利用随机梯度下降(Stochastic Gradient Descent,SGD)等优化算法不断优化模型参数。 而**预训练的思想是**,模型参数不再是随机初始化的,而是通过一些任务进行预先训练,得到一套模型参数,然后用这套参数对模型进行初始化,再进行训练。 ##### 自然语言表示 语言是离散的符号,自然语言的表示学习,就是将人类的语言表示成更易于计算机理解的方式。 最早期的`n-gram` 模型,是基于统计的语言模型,通过前*n*个词来预测第*n*+1个词。 分布式理论(Distributional Hypothesis)在20世纪50年代被提出,这也是近10年,从word2vec到BERT 等一系列预训练语言模型的自然语言表示的基础思想。 早期的词袋模型,虽然能够方便计算机快速处理,却无法衡量单词间的语义相似度。 到了1986 年,分布式表示(Distributed Representation)被提出。虽然分布式理论和分布式表示同样都有“分布式”这个词,但其英文表述是不一样的,含义也不尽相同。 **分布式理论的核心思想是**:上下文相似的词,其语义也相似,是一种统计意义上的分布;而在分布式表示中,并没有统计意义上的分布。 分布式表示是指文本的一种表示方式。相比于独热表示,分布式表示将文本在更低的维度进行表示。 随着word2vec和GloVe等基于分布式表示的方法被提出,判断语义的相似度成为可能。 2013 年之后,基于大规模的文本数据训练得到的分布式表示,逐渐成了自然语言表示的主流方法。 在这种方式下,每个单词都有了一个固定的词向量表示,语义相近的单词,其向量也是相似的。 我们都知道,多义词是自然语言中的常见现象,也体现了语言的灵活性和高效性。 例如,单词play 可以表示玩游戏,可以表示播放,可以表示做某项运动,还可以表示演奏某个乐器。但在以word2vec 为代表的第一代预训练语言模型中,一个单词的词向量是固定不变的,也就是说,在对单词play 进行向量表示的过程中,不会区分单词的不同含义,这就导致无法区分多义词的不同语义。 英国语言学家John Rupert Firth 在1957 年的*A synopsis of linguistic theory* 中提到:“你可以通过单词的上下文知道其含义”(You shall know a word by the company it keeps)。 EMLo 论文的原始标题是*Deep contextualized word representation*,从“contextualized”一词可以看出,ELMo 考虑了上下文的词向量表示方法,以双向LSTM 作为特征提取器,同时考虑了上下文的信息,从而较好地解决了多义词的表示问题,后续章节会详细介绍。 ELMo 开启了第二代预训练语言模型的时代,即“预训练+ 微调”的范式。 自ELMo 后,Transformer[11] 作为更强大的特征提取器,被应用到后续的各种预训练语言模型中(如GPT、BERT 等),不断刷新自然语言处理领域任务的SOTA(State Of The Art,当前最优结果)表现。 Transformer 是由谷歌在2017 年提出的,其创新性地使用了Self-Attention(自注意力),更善于捕捉长距离的特征,同时其并行能力也非常强大,逐步取代了RNN,成了最主要的自然语言处理特征提取工具。 ##### 预训练语言模型发展史及分类  可以看到,2013 年,word2vec 开启了自然语言预训练的序章。 随后,Attention的出现使得模型可以关注更重要的信息,之后的几年,基于上下文的动态词向量表示ELMo,以及使用Self-Attention 机制的特征提取器Transformer的提出,将预训练语言模型的效果提升到了新的高度。 随后,BERT、RoBERTa、XLNet、T5、ALBERT、GPT-3 等模型,从自然语言理解及自然语言生成等角度,不断刷新自然语言处理领域任务的SOTA 表现。 《预训练语言模型》一书的后面章节会详细介绍典型的预训练语言模型。这里,我们简单区分自回归(Autoregressive)和自编码(Autoencoder)两种不同的模型。 简单来讲,**自回归模型**可以类比为早期的统计语言模型(Statistical Language Model),也就是根据上文预测下一个单词,或者根据下文预测前面的单词。例如,ELMo 是将两个方向(从左至右和从右至左)的自回归模型进行了拼接,实现了双向语言模型,但本质上仍然属于自回归模型。 **自编码模型**(如BERT),通常被称为是降噪自编码(Denosing Autoencoder)模型,可以在输入中随机掩盖一个单词(相当于加入噪声),在预训练过程中,根据上下文预测被掩码词,因此可以认为是一个降噪(denosing)的过程。 这种模型的好处是可以同时利用被预测单词的上下文信息,劣势是在下游的微调阶段不会出现掩码词,因此[MASK] 标记会导致预训练和微调阶段不一致的问题。 BERT 的应对策略是针对掩码词,以80% 的概率对这个单词进行掩码操作,10% 的概率使用一个随机单词,而10% 的概率使用原始单词(即不进行任何操作),这样就可以增强对上下文的依赖,进而提升纠错能力。 XLNet 改进了预训练阶段的掩码模式,使用了自回归的模式,因此XLNet 被看作广义的自回归模型。 国际计算语言学协会(The Association for Computational Linguistics)主席、微软亚洲研究院前副院长周明曾给出了一个关于自回归和自编码模型的示例,如图5所示。  自回归模型,就是根据句子中前面的单词,预测下一个单词。 例如,通过“LM is a typical task in natural language ____”预测单词“processing”;而自编码模型,则是通过覆盖句中的单词,或者对句子做结构调整,让模型复原单词和词序,从而调节网络参数。 在图5 (a) 所示的单词级别的例子中,句子中的“natural”被覆盖,而在图5 (b) 所示的句子级别的例子中,不仅有单词的覆盖,还有词序的改变。 可以看出,ELMo、GPT 系列和XLNet 属于自回归模型,而BERT、ERINE、RoBERTa 等属于自编码模型。 图6 给出了针对BERTLARGE提取语义和语法信息的结果,其中,语法信息(Syntactic Information),如词性(Part-Of-Speech,POS)、成分(Constituents)、依存(Dependencies)更早出现在BERTLARGE 的浅层,而语义信息(Semantic Information),如共指消解(Coreference)、语义原型角色(Sementic Proto-Roles,SPR)等则出现在BERTLARGE 的深层。 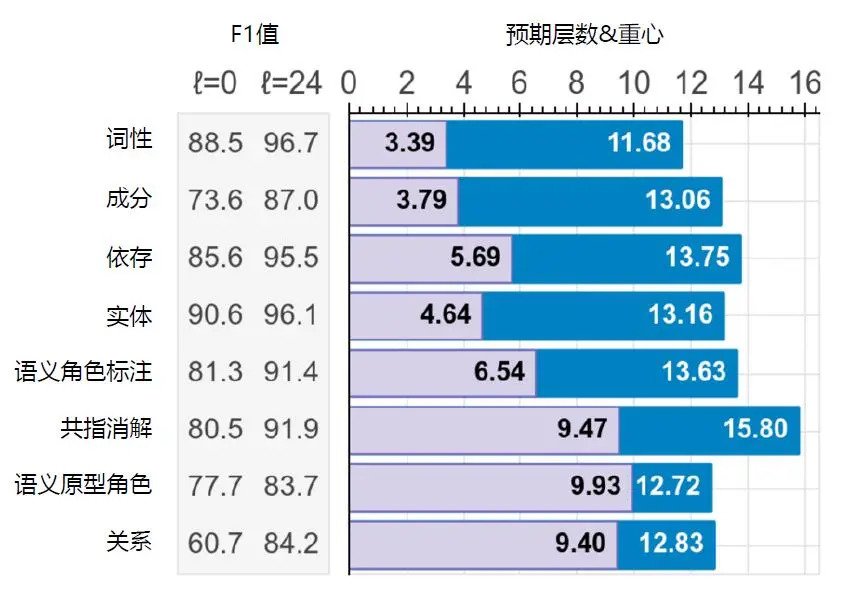 目前,预训练语言模型的通用范式是: > (1)基于大规模文本,预训练得出通用的语言表示。 > > (2)通过微调的方式,将学习到的知识传递到不同的下游任务中。 在微调的过程中,每种预训练语言模型的用法不尽相同,《预训练语言模型》一书的后面章节将对典型的模型进行详细阐述。 这里以GPT为例,简单介绍在预训练之后,在下游,不同的自然语言处理任务的具体用法如图7所示。 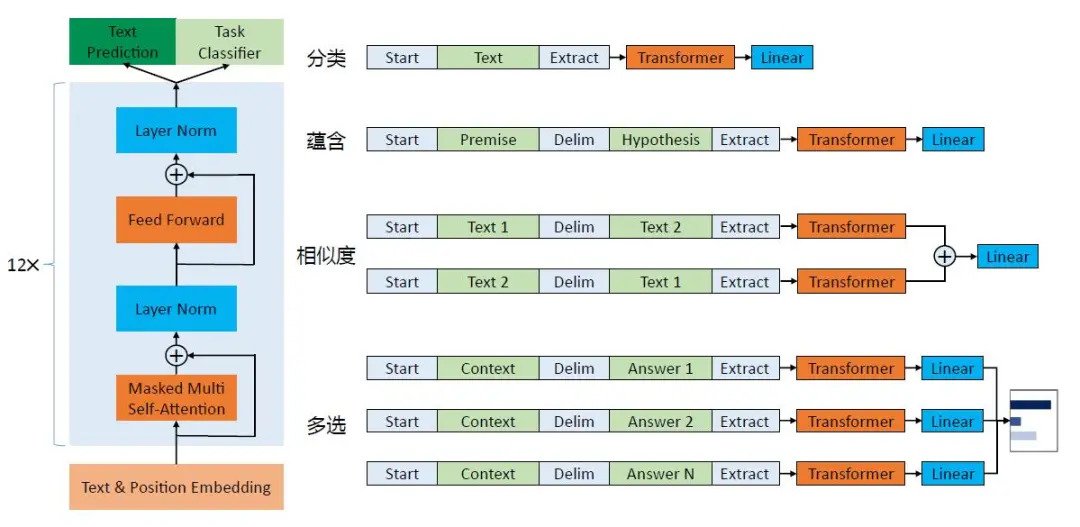 图7的左边,是基于Transformer 的GPT 的基本框架,而图7的右边则展示了如何将不同的自然语言处理任务调整至适应GPT 框架的形式。 以分类任务为例,在一段文本的开头和结尾分别加上“Start”和“Extract”标示符对其进行改造,然后使用Transformer 进行处理,最后通过线性层(Linear)完成监督学习任务,并输出分类结果。 类似地,对于多选(Multiple Choice)任务,需要根据上下文(Context)选择正确答案(Answer)。 具体来说,如图7所示,将答案“Answer”,与其上下文“Context”通过添加首尾标示符及中间分隔符的方式进行改造,对其他答案进行相同的操作,然后分别经过Transformer,再经过线性层,得到每一个选项的可能性概率值。 由于不同的预训练语言模型的结构不同、优势不同,在实际应用中,需要根据具体的任务选择不同的模型。例如,BERT 系列模型更适用于理解任务,而GPT 系列模型更适用于生成任务。 预训练语言模型在近两年得到了蓬勃发展,复旦大学的邱锡鹏教授在*Pretrained models for natural language processing: A survey*这篇综述论文中整理了一张预训练语言模型分类体系图,图8为笔者翻译后的版本。 ![[webp-to-jpg output image]](https://raw.githubusercontent.com/Phalacrocorax/memo-image-host/master/uPic/ezgif-2-134c1f6031e0.jpg) 依据四种不同的分类标准,对主流预训练语言模型进行了分类整理。 **第一个标准是语言表示是否上下文相关。**正如前文提到的,早期的预训练语言模型(如word2vec、GloVe)都是上下文无关的,而ELMo 之后的大多数预训练语言模型都是上下文相关的。 **第二个标准是模型的核心结构。**例如,ELMo 使用的是双向LSTM 结构,而BERT 的核心结构是Transformer Encoder,GPT 的核心结构是Transformer Decoder。 **第三个标准是任务类型,可以分为有监督模型和无监督/自监督模型两类。**例如,机器翻译模型(训练数据通常是句对)属于有监督模型,如CoVe等,而大多数预训练语言模型都属于无监督/自监督模型,如ELMo、BERT等。 **第四个标准是模型扩展。**随着预训练语言模型的发展,出现了不同的扩展方向,如模型结构的扩展、领域的扩展、任务的扩展和模态的扩展等。 每个模型的细节,在《预训练语言模型》一书的后面章节会有更详细的介绍。 周明曾提到:“大数据预训练+ 小数据微调,标志着自然语言处理进入了大工业化的时代。”但GPT-3 的“大力出奇迹”(有1750 亿参数量)是否真正标志着人工智能从感知智能到认知智能的跨越?预训练语言模型的缺陷在哪里?未来的发展趋势如何?《预训练语言模型》一书的第8章对这些问题进行了探讨,感兴趣的同学可以阅读《预训练语言模型》一书! ### How to Remember What You Read [How to Remember What You Read](https://fs.blog/2017/10/how-to-remember-what-you-read/) > “I cannot remember the books I have read any more than the meals I have eaten; even so, they have made me.” > > — Ralph Waldo Emerson The more that active readers read, the better they get. They develop a latticework of [mental models](https://fs.blog/mental-models/) to hang ideas on, further increasing retention. Active readers learn to differentiate good argument`sargumentos` and structures`estructuras` from bad ones. Active readers [make better decisions](https://fs.blog/smart-decisions/) because they know how to [get the world to do the bulk of the work](https://www.fs.blog/2016/02/joseph-tussman/) for them. Active readers avoid problems. Active readers have another advantage: **The more they read the faster they read.** ##### Effective Reading Habits Having a deliberate strategy to get better at anything we spend a lot of time `tiempo` on is a sensible approach. While we might spend a lot of time reading and consuming information, few of us consciously improve the effectiveness of our reading. > “Every time I read a great book I felt I was reading a kind of map, a treasure map, and the treasure I was being directed to was in actual fact myself. But each map was incomplete, and I would only locate the treasure if I read all the books, and so the process of finding my best self was an endless quest. And books themselves seemed to reflect this idea. Which is why the plot of every book ever can be boiled down to ‘someone is looking for something’.” > > — Matt Haig, Reasons to Stay Alive ##### **Get Some Context ** A good place to start is by doing some preliminary research on the book. Some books – for example, [*A Confederacy of Dunces*](https://www.amazon.com/gp/product/0802130208/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=0802130208&linkId=cd7325bc79847670c2fe4245b1486a34) and [*The Palm Wine Drinkard*](https://www.amazon.com/gp/product/0802133630/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=0802133630&linkId=c64b625b2a795b0dc7eab15fc3e8ccec) – have a very different meaning once we know a bit about the life of the author. For older books, try to understand the historical context. For books written in an unfamiliar country, try to understand the cultural context. Some helpful questions to ask include: - Why did the author write this? (Did they have an agenda?) - What is their background? - What else have they written? - Where was it written? - What was the political, economic, and cultural situation at the time of writing? - Has the book been translated or reprinted? - Did any important events — a war, an economic depression, a change of leadership, the emergence of new technology — happen during the writing of the book? ##### Match the Book to Your Environment For example: - **Traveling or on holiday?** Match your book to the location — Jack Kerouac or John Muir for America; Machiavelli for Italy; Montaigne’s *Essays*, Ernest Hemingway, or Georges Perec for France; and so on. Going nowhere in particular? Read Vladimir Nabokov or Henry Thoreau. - **Dealing with grief?** Read [*When Breath Becomes Air* ](https://www.amazon.com/gp/product/081298840X/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=081298840X&linkId=b0d3c6940249d5771ffcc61a8e6190cd)by Paul Kalanithi, [*Torch* ](https://www.amazon.com/gp/product/0345805615/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=0345805615&linkId=09f25744b006e41a7d87d222235d4437)by Cheryl Strayed*,* or anything by Tarah Brach. - **Having a crisis about your own mortality?** (It happens to us all.) Read [Seneca](https://www.farnamstreetblog.com/seneca/)’s [*On the Shortness of Life* ](https://www.amazon.com/gp/product/1941129420/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=1941129420&linkId=4d55776353bcc62157a58c8277c7c37e)or Theodore Zeldin’s *[The Hidden Pleasures of Life](https://www.amazon.com/gp/product/0857053698/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=0857053698&linkId=8c2413aa8c1fd4434066ff4a994120cf).* - **Dealing with adversity?** Lose your job? Read Marcus Aurelius’ [*Meditations*](https://www.amazon.com/gp/product/B000FC1JAI/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=B000FC1JAI&linkId=691f1088ce1d7eea19ec0ff530062cbe) or Ryan Holiday’s *[The Obstacle Is the Way](https://www.amazon.com/gp/product/1591846358/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=1591846358&linkId=6b04fd262df0f3e9c5d9eca325809ce8).* - **Dissatisfied with your work?** Read [*Linchpin* ](https://www.amazon.com/gp/product/1591844096/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=1591844096&linkId=cd7bfabff52f39a1a8112d3641586347)by Seth Godin, [*Mastery* ](https://www.amazon.com/gp/product/014312417X/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=014312417X&linkId=d5e2791994a1e34f9c92a129cf1d6679)by Robert Greene, or [*Finding Flow* ](https://www.amazon.com/gp/product/0061339202/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&tag=farnamstreet-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=0061339202&linkId=55dd04f0eb787000454735182779953d)by Mihaly Csikszentmihalyi. ##### Write your chapter summary As you are reading a book, write your chapter summary right at the end of the chapter. If your reading session is over, this helps synthesize what you just read. When you pick up the book tomorrow start by reading the previous two chapter summaries to help prime your mind to where you are in the book. ##### **Stay Focused** Referring to the time before the internet, Nicholas Carr writes in The Shallows: “In the quiet spaces opened up by the prolonged, undistracted reading of a book, people made their own associations, drew their own inferences and analogies, fostered their own ideas. They thought deeply as they read deeply.” If you’re struggling to stay focused on a particularly difficult or lengthy book, decide to read a mere [25 pages of it a day](https://www.farnamstreetblog.com/2015/12/twenty-five-pages-a-day/). It takes only a few minutes to nibble away at a challenging text. Completing a long book in this manner might take months, but at least you will have read it without getting overwhelmed or bored. ##### **Build a Vivid Mental Picture** Building vivid mental pictures is one of the most effective techniques for remembering anything, not least what we read. When you come across an important passage or concept, pause and visualize it. Make the picture as salient and distinctive as possible. ### We may now know what life is 原文: [We may now know what life is](https://medium.com/the-infinite-universe/we-may-now-know-what-life-is-9326d34a14e8) Medium Comment > **@Chris Benesch** > > would argue that life is actually a state of increased entropy. From a classical point of view, a black hole being a point in spacetime is as ordered as you can get, yet it is actually the opposite because a formal definition of entropy is the number of initial states that lead to the same end result. No matter where, how fast, or how big infalling matter comes into a black hole, it all ends up in the same place. The only variable is total mass. Likewise with life, with a seemingly random set of environmental factors, ie what type of food is present, what side of your mouth you choose to chew on, the positions of the oxygen molecules in the air, all yields the same result more or less. More complex organisms and especially sentient ones make the configuration of the environment even less relevant, and even so our belief and apparent seduction of concepts like destiny, medicine and therapy show how we are looking every day to reach the point where our outside environment has little if any effect on our outcomes. I tend to view life more from a Feyman point of view. We may all take different paths, but by and large we all end up at the same spot, and most of us follow a very similar path to get there. > > 生命实际上是一种熵增加的状态。从经典的角度来看,黑洞是时空中的一个点,是你可以得到的有序状态,然而它实际上是相反的,因为熵的正式定义是导致相同最终结果的初始状态的数量。无论在哪里、以多快的速度、以多大的速度进入黑洞,它最终都会在同一个地方结束。唯一的变量是总质量。同样,对于生命来说,一组看似随机的环境因素,即什么类型的食物,你选择用哪一边的嘴咀嚼,空气中氧分子的位置,都会产生或多或少的相同结果。更复杂的生物体,尤其是有生命的生物体,使环境的配置变得更不相关,即使如此,我们对命运、医学和治疗等概念的信念和明显的诱惑,表明我们每天都在寻求达到这样的地步,即我们的外部环境对我们的结果几乎没有任何影响。我更倾向于从费曼的角度来看待生活。我们可能都走不同的路,但大体上我们都会在同一个地方结束,而且我们大多数人都遵循非常相似的路径到达那里。 --- In 1943, one of the fathers of quantum mechanics, famous for his equation and his cat, Erwin Schrödinger, turned his attention to a problem that was seemingly simple but defied an easy answer. As World War 2 raged, he published a book titled *What is Life?* 1943年,量子力学之父之一、以他的方程和他的猫而闻名的埃尔温-薛定谔,将注意力转向了一个看似简单却无法轻易回答的问题。在第二次世界大战肆虐之际,他出版了一本名为*什么是生命的书。 Based on a series of lectures given in Dublin, the book’s theme was to answer the question: “how can the events in space and time which take place within the spatial boundary of a living organism be accounted for by physics and chemistry?” In other words: What is Life? Or, from a physicist’s point of view, how can life arise from inanimate matter. Schrödinger’s primary insight is that life creates order from disorder. In a universe governed by the 2nd law of thermodynamics, that all things tend to maximal disorder, living things maintain small enclaves of order within themselves. Moreover, if you look down to the atomic level, you find that the interiors of living things are extremely chaotic. Heat and molecules diffuse through rapid motion. Everything seems random. Yet the living thing persists, turning all that small scale chaos into large scale order. 薛定谔的主要见解是,生命从无序中创造秩序。在一个受热力学第二定律支配的宇宙中,所有事物都趋向于最大的无序状态,生物体在自身内部保持着小范围的秩序。此外,如果你往下看到原子水平,你会发现生物的内部是极其混乱的。热量和分子在快速运动中扩散。一切似乎都是随机的。然而,生物体却坚持不懈,把所有这些小规模的混乱变成大规模的秩序。 Medium Comment > **@ MXM** > > Like a lot of things, this observation depends on the scope and scale you are looking at. What comes into a body as fairly ordered food goes out as fairly disordered (broken down) waste. A living thing is an entropy machine over time. It is worth remembering that food calories are actually kilocalories (1 food calorie is 1,000 regular calories). A regular calorie is defined as the energy required to heat 1 gram of water 1 degree Celsius. A food calorie is the energy required to heat 1 kilogram of water 1 degree Celsius. The average person with a 2,500 food calorie diet is using something like 2.5 million regular calories a day. Our bodies are shockingly efficient if you look at how little we eat to produce that much energy. We have taken that much energy in chemical bonds out of our food. > > 像很多事情一样,这种观察取决于你所关注的范围和规模。进入身体的是相当有序的食物,出去的是相当无序的(分解)废物。随着时间的推移,一个生命体是一个熵机。值得记住的是,食物卡路里实际上是千卡路里(1个食物卡路里是1,000个普通卡路里)。一个普通卡路里被定义为将1克水加热1摄氏度所需的能量。一个食物卡路里是将1公斤水加热1摄氏度所需的能量。普通人以2,500食物卡路里的饮食方式,每天要消耗大约250万普通卡路里。如果你看一下我们吃得这么少就能产生这么多的能量,我们的身体的效率是令人震惊的。我们从食物中提取了那么多化学键的能量。 Human built machines, by contrast, attempt to maintain order down to the smallest relevant levels. Microchips, for example, depend on orderly transfer of data down to nanometers. Precision machine tools, likewise, function because they have an exact specification at nearly the molecular level. The result is that human tools require careful protection and maintenance and break easily when subjected to the elements. Life, on the other hand, has withstood the elements for billions of years precisely because it is able to build order out of chaos. 相比之下,人类制造的机器试图维持秩序,直到最小的相关水平。例如,微芯片依赖于数据的有序传输,精确到纳米级。同样地,精密机床的运作也是因为它们有一个几乎是分子水平的精确规格。其结果是,人类的工具需要仔细的保护和维护,并且在受到各种因素的影响时容易损坏。 另一方面,生命之所以能经受住几十亿年的考验,正是因为它能够从混沌中建立秩序。 What life needs is a clear mathematical definition, and statistical mechanics, the science dedicated to explaining macroscopic behavior from microscopic constituents, may be best suited science for the task. Indeed, statistical mechanics already provides a clear connection between chaos at the molecular level and persistent, orderly phenomena at the macroscopic level. Measurements like temperature and pressure are emergent phenomena that, however precise and persistent they are, arise from the random motion of molecules. Yet, this is insufficient for a true understanding of life because these macroscopic observations arise from gases and fluids that are in equilibrium. They do not change or if they do it is only from one equilibrium to another. 生命需要的是一个明确的数学定义,而统计力学,这门致力于从微观成分中解释宏观行为的科学,可能是最适合这项任务的科学。 事实上,统计力学已经在分子层面的混乱和宏观层面的持续有序现象之间提供了明确的联系。像温度和压力这样的测量是突发现象,无论它们多么精确和持久,都是由分子的随机运动产生的。 然而,这对于真正理解生命来说是不够的,因为这些宏观观察是由处于平衡状态的气体和液体产生的。它们不会发生变化,或者即使发生变化,也只是从一个平衡状态到另一个平衡状态。 Life is different. It is not just order from chaos but order from chaos in motion. It is inherently not in equilibrium. For as soon as life reaches some equilibrium, it is dead. Non-equilibrium statistical mechanics, which I will abbreviate NESM, however, can give a better answer. The key feature of NESM is to measure and quantify the probability of paths in phase space. 生命是不同的。它不仅是混乱中的秩序,而且是运动中的混乱的秩序。它本来就不处于平衡状态。因为一旦生命达到某种平衡状态,它就会死亡。 然而,非平衡统计力学,我将缩写为NESM,可以给出一个更好的答案。NESM的关键特征是测量和量化相空间中路径的概率。 Most statistical systems have phase spaces in the millions of dimensions or more. We can even talk about infinite dimensional spaces where the measureable quantity is modeled as a smooth function or field. For example, an ocean or a river is made of so many particles that we might as well treat them as infinite and model the fluid using what is called a velocity field — basically a function that gives the velocity of a fluid for every position at the infinitesimal level. 大多数统计系统的相空间都有数百万维或更多。我们甚至可以谈论无限维度的空间,其中可测量的数量被建模为一个平滑的函数或场。例如,海洋或河流是由如此多的粒子组成的,我们不妨把它们当作无限的,并使用所谓的速度场来模拟流体--基本上是一个函数,给出流体在无限小的每个位置上的速度。 Using either a Master or Langevin equation it becomes possible to measure the probability of not only transitioning from one point to an adjacent point in phase space but to understand the probability of following a path in phase space from one point to another. This is called “trajectory” statistical mechanics. This trajectory and the probability associated with it is theorized to distinguish life from non-life. The reason is that a living thing, by maintaining its internal order, is able to travel from one orderly point to another orderly one with a much higher probability than a non-living being in the same phase space. Likewise, it travels from an orderly point to a more disordered one with a much lower probability. 使用Master方程或Langevin方程,不仅可以测量相空间中从一点过渡到相邻点的概率,而且可以了解相空间中从一点到另一点的路径的概率。这被称为 "轨迹 "统计力学。 这种轨迹和与之相关的概率被理论化,以区分生命和非生命。原因是,一个生物,通过保持其内部秩序,能够从一个有序的点到另一个有序的点,其概率比在同一相空间的非生物要高得多。同样,它从一个有序的点到一个更无序的点的概率要低得多。 Moreover, living things can travel from point to point to point all while maintaining internal order because of the high probability that they maintain. Non-living things, on the other hand, travel from order to disorder to order in cycles. They will not do anything to break out of the cycle in order to persist. Thus, a living thing follows a more complex path in phase space than a non-living thing, avoiding paths to disorder if possible and also avoiding either static or cyclical equilibria. 此外,生物体可以从一个点到另一个点,同时保持内部秩序,因为它们保持着高概率。另一方面,非生物体则是在循环中从秩序到无序再到秩序。它们为了坚持下去,不会做任何事情来打破这个循环。因此,与非生物相比,生物在相空间中遵循更复杂的路径,尽可能避免走向无序,也避免静态或周期性的平衡。 Yet, non-equilibrium phenomena abound in the non-living world as well from snowflakes to stripes in the atmospheres of gas giants to hurricanes and tornadoes. All of these are ordered phenomena that persist for a time in a non-equilibrium state and then die out. Inside a cell, all kinds of non-equilibrium phenomena are occurring such as DNA transcription, molecular motors, protein formation, and signaling. None of these in itself is alive yet together they maintain order within the cell and enable it to pass on its encoding. It is this ability to pass on an encoding and enable the life form to copy itself and thereby perpetuate that encoding that makes life truly unique. No tornado or salt crystal can do that. 然而,非平衡现象在非生物世界中也比比皆是,从雪花到气态巨行星大气层中的条纹,到飓风和龙卷风。所有这些都是有序的现象,在非平衡状态下持续一段时间,然后消亡。 在一个细胞内,各种非平衡现象都在发生,如DNA转录、分子马达、蛋白质形成和信号传递。这些本身都没有生命,但它们共同维持着细胞内的秩序,并使其能够传递其编码。正是这种传递编码的能力,使生命形式能够自我复制,从而延续这种编码,使生命真正独特。没有龙卷风或盐晶体可以做到这一点。 One of the clear indicators of non-equilibrium processes that scientists have studied in single celled organisms is a loss of what is called detailed balance. Detailed balance is simply the sense that time is neither running forwards or backwards. In other words, a process is just as likely to move from one state in phase space to another as back again. Thus, the trajectories through phase space that exemplify non-equilibria are those that are distinctly future oriented. They have a memory of past, and they are irreversible or nearly so. And these are also what life depends upon. Life is able to keep non-equilibrium processes in check however. When it gets out of control, you get cancer, unconstrained growth and out of control metabolic properties. It is as if life is trying to ride a bike down a steep path and cancer is when the bike starts to careen out of control down the slope. Because an out of control process will lead to complete disorder eventually, a tangled mess at the bottom where equilibrium, i.e., death, occurs, life must maintain itself at the brink between chaos and order, between a fast decent to one equilibrium and a stand still at another. 科学家们在单细胞生物体中研究的非平衡过程的明确指标之一是失去了所谓的详细平衡。详细平衡是指时间既不向前也不向后运行的感觉。换句话说,一个过程从相空间的一个状态移动到另一个状态的可能性和返回的可能性一样大。 因此,体现非平衡的相空间的轨迹是那些明显面向未来的轨迹。它们有对过去的记忆,而且是不可逆的,或几乎是这样。而这些也是生命所依赖的。 然而,生命能够将非平衡过程控制住。当它失去控制时,你会得到癌症、不受约束的增长和失控的代谢特性。这就好比生命试图骑着自行车在陡峭的道路上行驶,而癌症就是当自行车开始失去控制地冲下斜坡时。因为一个失控的过程最终会导致完全的无序,在平衡,即死亡发生的底部出现一个纠结的混乱,所以生命必须在混乱和秩序之间的边缘维持自己,在一个平衡的快速体面和另一个平衡的停滞之间维持自己。 ### Work In A Flow State For 2+ Hours Per Day Using The ‘3C Method’ 原文: [Work In A Flow State For 2+ Hours Per Day Using The ‘3C Method’](https://medium.com/better-advice/work-in-a-flow-state-for-2-hours-per-day-using-the-3c-method-3ffab28ee9e1) A 10-year [McKinsey study](https://www.mckinsey.com/business-functions/organization/our-insights/increasing-the-meaning-quotient-of-work) on flow and productivity found that top executives are five times more productive during flow. **That’s a 500% increase in productivity.** Therefore, my personal rule is that **the morning is for making, and the afternoon is for managing**. Every morning, I protect 2–3 hours for deep, flow state work on my highest-priority task of the day *(writing, working on products, marketing).* As this is my peak productivity time, I protect it at all costs. Then, I use the afternoon for managing-type tasks such as email, meetings, and other administrative work that requires less mental energy and focus. This rule has been a game-changer to my productivity. ##### The 3C Method For ‘Hacking’ The Flow State - **C**reate a Distraction-Free Environment - **C**ontrol The ‘Monkey’ Mind - **C**ognitive Optimization ### 一点收获 - [All public GitHub code was used in training Copilot](https://twitter.com/NoraDotCodes/status/1412741339771461635) HN Comment @fleddr > To me, the particular use case and whether it is fair use or not, is of minor interest. A far more pressing matter is at hand: AI centralization and monopolization.Take Google as an example, running Google Photos for free for several years. And now that this has sucked in a trillion photos, the AI job is done, and they likely have the best image recognition AI in existence.Which is of course still peanuts compared to training a super AI on the entire web.My point here is that only companies the size of Google and Microsoft have the resources to do this type of planetary scale AI. They can afford the super expensive AI engineers, have the computing power and own the data or will forcefully get access to it. We will even freely give it to them.Any "lesser" AI produced from smaller companies trying to compete are obsolete, and the better one accelerates away. There is no second-best in AI, only winners.If we predict that ultimately`final` AI will change virtually`práctico` every aspect of society, **these companies will become omnipresent,** "everything companies". God companies.As per usual, it will be packaged as an extra convenience for you. And you will embrace it and actively help realize this scenario. Twitter Comment @laurieontech > The law on all of this is basically non-existent. And there aren't enough people who really understand the nuances who are also lawyers. It's a whole mess which results in companies getting to decide for themselves. Not good. - "Prediction depends on events outside your control. Creation depends on events within your control. Don’t guess about the future. Shape it." -- `3-2-1` How to give advice - 非常棒的个人推特背景图。 - [Rules of Storytelling for Fundraising](https://www.nfx.com/post/23-rules-storytelling-fundraising/) - These are excellent points and can be summarized into: - Why are you here? - How did you get here? - Where are you going? - How do you plan to get there? - With that in mind, of all of the points they make, the most important`importante` one IMO is point`punto` #4.