> 2021年07月18日信息消化 ### Wedges: How To Scope Your Initial Product 原文:[Wedges: How To Scope Your Initial Product](https://every.to/divinations/product-wedges-a-complete-guide) > How and why early-stage startups sacrifice power for growth The first is to double-down on marketing. Some swear by ads. Others will tell you to slap an “invite friends” button in your onboarding flow, or create FOMO with a waitlist. At my last startup, an investor suggested I hire someone to join hundreds of Facebook groups and post links to our product. Growth hacking! 首先是在营销方面加倍努力。有些人发誓要做广告。其他人会告诉你在你的入职流程中设置一个 "邀请朋友 "的按钮,或者用一个等待名单来创造FOMO。在我的上一家创业公司,一位投资者建议我雇人加入数以百计的Facebook群组并发布我们产品的链接。增长黑客! Which leads to the second approach to increase growth, changing the product. Now, you might think I’m talking about pivoting your entire company, but that’s not it. Just because your product isn’t organically taking off doesn’t mean your entire idea is bad. Maybe you just didn’t find the right starting point. So what can be done? Instead of pivoting, consider sharpening the leading edge of your initial product into the shape of a wedge. 这导致了增加增长的第二个方法,改变产品。现在,你可能认为我说的是对你的整个公司进行透视,但事实并非如此。只是因为你的产品没有有机地起飞,并不意味着你的整个想法是坏的。也许你只是没有找到正确的起点。那么,可以做什么呢?与其转向,不如考虑将你最初产品的前缘磨成楔形。 A wedge? Yes, a wedge! In the physical world, wedges are used to concentrate a lot of force into a narrow point, which creates a mechanical advantage that’s useful for breaking into dense surfaces that are ordinarily impenetrable. 楔子? 是的,一个楔子! 在物理世界中,楔子被用来将大量的力集中到一个狭窄的点上,这就产生了一种机械优势,对于打破通常无法穿透的密集表面非常有用。 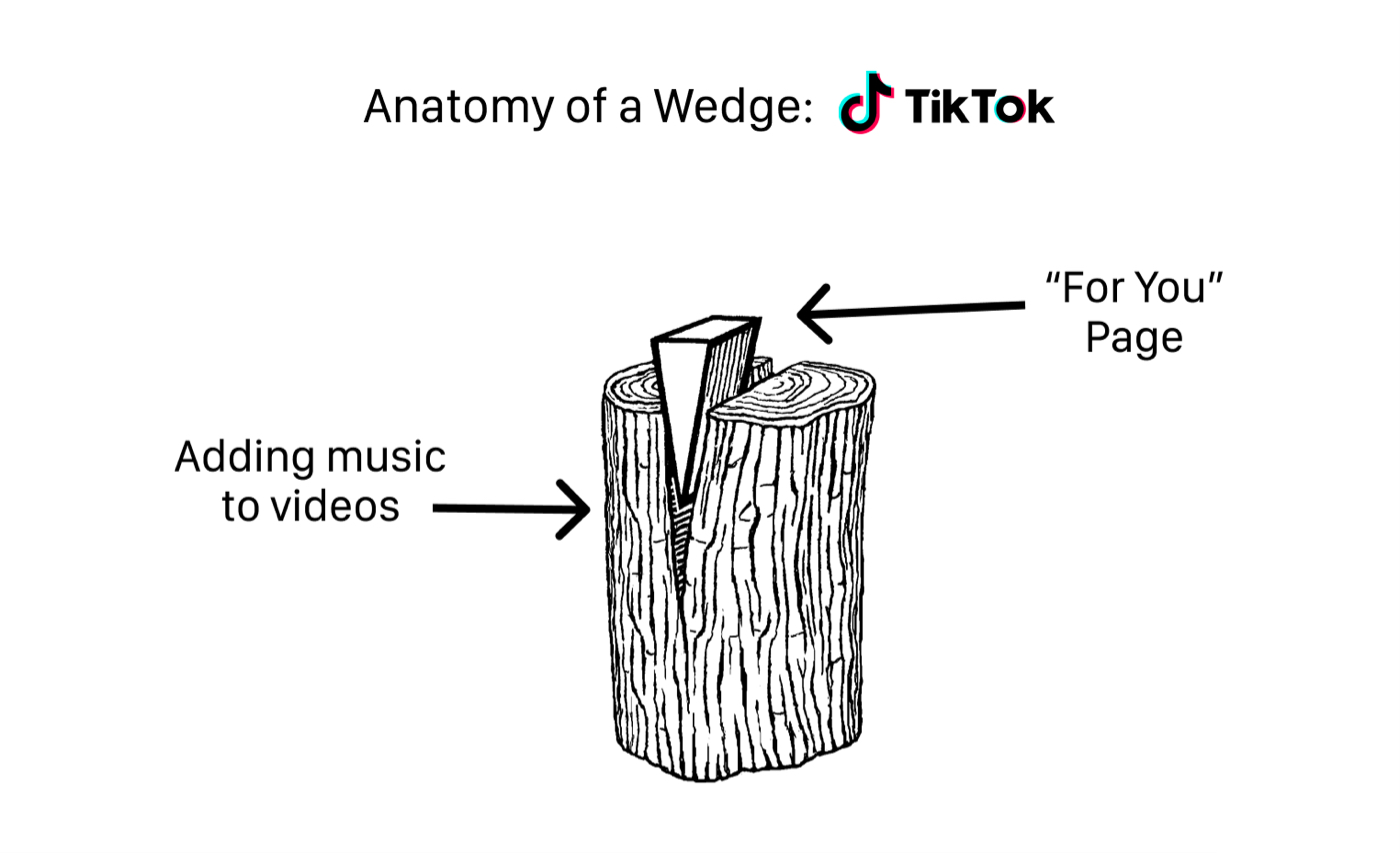 Before anyone cared about blowing up on the For You page, TikTok’s initial wedge into the market was they (and their precursor, Musically) were one of the first apps to make it easy to record a video on your phone that was set to music. Teenagers came for the tool, but then they ended up staying for the network—and brought us all along with them. 在有人关心 "为你而战 "页面上的信息之前,TikTok进入市场的最初楔子是他们(以及他们的前身Musically)是第一批让你在手机上轻松录制视频并设置成音乐的应用程序之一。青少年是为了这个工具而来,但他们最终还是为了网络而留下--并把我们都带了过去。 This example (just one of forty-ish that we cover in this post) perfectly reflects the two core principles that make wedges work: 1. **Some value propositions are easier for new customers to adopt than others.** To get someone to buy into the whole concept of a For You page, you need to educate people on what TikTok is and, realistically, they probably need to see several TikToks in the wild before they will be tempted to download the app. But if your friend used a tool to create a music video and sent it to you, you don’t need to learn anything. 对于新客户来说,有些价值主张比其他主张更容易被采纳。为了让别人接受 "给你 "页面的整个概念,你需要教育人们TikTok是什么,而且从现实的角度来看,他们可能需要在野外看到几个TikToks,然后才会被诱惑去下载这个应用。但如果你的朋友用一个工具制作了一个音乐视频并发给你,你就不需要学习任何东西。 2. **Some value propositions are easier for new companies to deliver than others.** Even if you could get people to easily buy into the idea of the For You page, how are you going to get all the videos and data and machine learning algorithms you need to create a good experience? It’s just not possible on day one. 对于新公司来说,有些价值主张比其他公司更容易实现。即使你能让人们轻松地接受 "为你服务 "页面的想法,你如何获得所有你需要的视频、数据和机器学习算法来创造一个好的体验?这在第一天就是不可能的。 *In the rest of the article, we cover the five types of product wedges:* 1. *Come for the tool, stay for the network* 2. *Come for the content, pay for the product* 3. *Come for the curation, stay for the exclusives* 4. *Come for low risk/reward, stay for high risk/reward* 5. *Come for the prestige, stay for the price* ### 程序员可能必读书单推荐(一) 原文:[程序员可能必读书单推荐(一)](https://draveness.me/books-1/) TL;DR 可能是因为大多数英文书籍的名字都很长,很多比较出名的书籍都有广为人知的缩写,今天要介绍的三本书籍也都有各自的缩写,SICP、CTMCP 和 DDIA,可能很多人都听过这三本书的名字,这三本书对作者都有很大的影响 ##### Structure and Interpretation of Computer Programs、SICP) Youtube SICP: https://www.youtube.com/watch?v=IcZSFewqr9k&list=PLkEwH_Z2WOlppy8oUfrGwFVlOuKyo3RO_&index=1 作为一本介绍计算机程序的书,它选择一门非常小众的编程语言 Scheme[2](https://draveness.me/books-1/#fn:2),Scheme 是 Lisp 的方言,作为 1970 年从 MIT 实验室中走出的语言,它却一开始就支持了函数式的编程范式。与今天复杂的编程语言相比,该语言中的概念和元素非常少,然而越是简单的工具越能揭示编写计算机程序时遇到的基本问题。 ##### Concepts, Techniques and Models of Programming Language、CTMCP 这本书通过统一的方式介绍主流的全部**编程范式**、它们之间的关系以及它们的具体应用。  ##### Designing Data-Intensive Applications、DDIA 该书的第一部分是围绕数据本身展开的,其中介绍了数据的模型、查询语言、存储和获取以及编码方式;第二部分介绍了分布式的数据应该如何处理,其中包括副本、分片、事务、一致性和共识等内容;最后一部分主要介绍的是衍生数据的处理,其中包括批处理、流处理和未来的数据系统,而真正与研究大数据开发方向的同学关系紧密也是这一部分。 ### Git Branches Tutorial https://www.youtube.com/watch?v=e2IbNHi4uCI ```bash gittower . #client git branch new-branch 2b504ee # start new branch from a commit git checkout/switch branch # rename branch git branch -m <better-name> # current git branch -m <old-name> <new-name> # track (connect with remote branch) git branch --track origin/<base-branch> # preview git log main..feature/<branch> git log origin/main..main ``` ### Cut Out the Middle Tier: Generating JSON Directly from Postgres origin: [Cut Out the Middle Tier: Generating JSON Directly from Postgres](https://blog.crunchydata.com/blog/generating-json-directly-from-postgres) ##### Easy JSON using row_to_json The simplest JSON generator is row_to_json() which takes in a tuple value and returns the equivalent JSON dictionary. 最简单的JSON生成器是row_to_json(),它接收一个元组值并返回等价的JSON字典。 ```sql SELECT row_to_json(employees) FROM employees WHERE employee_id = 1; ``` ##### Full result sets using json_agg ```sql SELECT json_agg(e) FROM ( SELECT employee_id, name FROM employees WHERE department_id = 1 ) e; ``` ##### Nested results using subqueries Using aggregation, and converting the results to JSON in stages, it's possible to build up nested JSON outputs that reflect table relationships. ```sql WITH -- strip down employees table employees AS ( SELECT department_id, name, start_date FROM employees ), -- join to departments table and aggregate departments AS ( SELECT d.name AS department_name, json_agg(e) AS employees FROM departments d JOIN employees e USING (department_id) GROUP BY d.name ) -- output as one json list SELECT json_agg(departments) FROM departments; ``` ##### All your tables in JSON Ever wanted to quickly extract a definition of your table structures from the database? With the JSON formatters and the PostgreSQL system tables, all that info is right at hand. ```sql WITH rows AS ( SELECT c.relname, a.attname, a.attnotnull, a.attnum, t.typname FROM pg_class c JOIN pg_attribute a ON c.oid = a.attrelid and a.attnum >= 0 JOIN pg_type t ON t.oid = a.atttypid JOIN pg_namespace n ON c.relnamespace = n.oid WHERE n.nspname = 'public' AND c.relkind = 'r' ), agg AS ( SELECT rows.relname, json_agg(rows ORDER BY attnum) AS attrs FROM rows GROUP BY rows.relname ) SELECT json_object_agg(agg.relname, agg.attrs) FROM agg; ``` ### Writing Good Documentation origin: [Writing Good Documentation](https://twinnation.org/articles/52/writing-good-documentation) There are two types of repositories: **those that run**, and **those that don't**. Those that run - applications and such - can target anybody, from a programmer, to a system administrator with very little experience writing code, or even your average Joe that just wants to try your application on his brand new NAS which he just found out has support for a thing called "containers". This means that they want to know how to use your application, not the code. 那些可以运行的--应用程序之类的--可以针对任何人,从程序员,到没有什么写代码经验的系统管理员,甚至是你的普通人,只是想在他的全新的NAS上试试你的应用程序,他刚刚发现这个NAS支持一个叫做 "容器 "的东西。这意味着,他们想知道如何使用你的应用程序,而不是代码。 Conversely, those that don't run - like libraries and frameworks - target programmers. In other words, unlike the previous type, they want to know how to use the code. 相反,那些不运行的--如库和框架--则针对程序员。换句话说,与前一种类型不同,他们想知道如何使用这些代码。 There are still things `cosas` that both types of repositories should have, like a brief description of the purpose of the project. Something as simple as the following would do just fine for a summary: > potato-peeler is a Java library for peeling potatoes asynchronously with support for customizable blade sharpness, peeler durability and rate limiting. ##### Those that run - Step-by-step guide (command(s) to start the application, e.g. `docker run -p 8080:8080 --name gatus twinproduction/gatus`) - Docker Compose file (Docker) - Helm chart or YAML files (Kubernetes) - Makefile - All of the above ##### Those that don't Unlike the previous type, libraries are not executed by just any end user, they're programmatically called by a developer. This means that you need to document the API of your library, namely, the core functions, but let's take it one step at a time. Much like applications, you do need to specify how to get started with your library, the only difference being that your focus is on the code this time, and depending on the language, the process to add a library. After your brief description, the first thing you want to have is the instructions for installing libraries followed by the minimum code required to use the library. - Installation - Usage ### An ex-Googler's guide to dev tools origin: [An ex-Googler's guide to dev tools](https://about.sourcegraph.com/blog/ex-googler-guide-dev-tools/) Many years `años` ago, I did a brief stint at Google. A lot has changed since then, but even that brief exposure to Google's internal developer tools left a lasting impression on me. In many ways, the dev tools inside Google are the most advanced in the world. Google has been a pioneer not only in scaling their own software systems but in figuring out how to build software effectively at scale. They've dealt with issues `temas` related to codebase volume, code`código` discoverability, organizational knowledge sharing, and multi-service deployment at a level `un nivel` of sophistication that most other companies have not yet reached. (For reference, see [Software Engineering at Google](https://www.amazon.com/Software-Engineering-Google-Lessons-Programming/dp/1492082791).) 许多年前,我曾在谷歌做过短暂的工作。从那时起,很多事情都发生了变化,但即使是对谷歌内部开发工具的短暂接触,也给我留下了深刻印象。在许多方面,谷歌内部的开发工具是世界上最先进的。谷歌不仅在扩展他们自己的软件系统方面是个先锋,而且在找出如何有效地大规模构建软件方面也是个先锋。他们已经处理了与代码库容量、编解码器可发现性、组织知识共享和多服务部署有关的问题,其复杂程度是其他大多数公司尚未达到的。 Both inside Google and out, software development lifecycle looks something like this: 1. You think of a feature you want to build or a bug you need to fix. 2. You read a bunch of code, design docs, and ask colleagues questions. You're building an understanding of the problem and how the solution will roughly fit into the existing system. 3. You start writing code. You aim first for something *just* working. Maybe you go back and look up docs or read some more code several times while you're doing this. 4. You have it working, but you're not ready to ship. You've broken some tests, which you now fix, you add some more tests, you refactor the code to make it cleaner and easier for the next person to understand. You push it up to a branch. You wait for CI to run and maybe you implement a couple of additional fixes and small improvements. 5. You submit the patch for review. Your teammates leave some comments. You make the changes. Maybe there are a few rounds of back-and-forth before the reviewer(s) approve the change. 6. You merge the patch and it gets deployed. 7. Monitoring systems that are in place will determine if there are any production issues. If it's your patch that caused an outage, you're on the hook for fixing it. | Software development stage | Inside Google | Outside Google | | -------------------------- | --------------------------------------- | ------------------------------------------------------------ | | Identify feature or bug | Issue Tracker | GitHub issues, Jira | | Read code | Code search | Your editor, [OpenGrok](https://oracle.github.io/opengrok/), [Hound](https://github.com/hound-search/hound), [Sourcegraph](https://about.sourcegraph.com/) | | Write code | Critique, IntelliJ, Emacs, Vim, VS Code | Everything except Critique | | Test code | Blaze | A bit of the Wild West, but [Bazel](https://bazel.build/) is gaining traction | | Review code | Critique | [GitHub](http://github.com/) PRs, [Gerrit](https://www.gerritcodereview.com/), [Phabricator](https://www.phacility.com/phabricator/), [Reviewable](https://reviewable.io/) | | Deployment | Borg | [Kubernetes](https://kubernetes.io/) | | Monitoring | Borgmon, Dapper, Viceroy | [Prometheus](https://prometheus.io/), [Grafana](https://grafana.com/), [Lightstep](https://lightstep.com/), [Honeycomb](https://www.honeycomb.io/), [Sentry](https://sentry.io/) | To improve your productivity, you need to find better tools. There's a useful GitHub repository that identifies nearly every single tool inside Google and its closest comparables outside of Google: https://github.com/jhuangtw/xg2xg. This list is comprehensive, but a bit overwhelming. So where do you start? I believe that code search is usually a great tool to start with. Yes, I am the cofounder of a code search company, so of course I would say that, but here are my reasons—if these don't resonate with you, then I recommend skipping to the next section! Here are the common code search engines we've seen in use: - [OpenGrok](https://oracle.github.io/opengrok/): a fairly old but persistent code search engine now maintained by Oracle - [Hound](https://github.com/hound-search/hound): a code search engine created and open-sourced by engineers at Etsy - [Livegrep](https://livegrep.com/search/linux): a code search engine created by Nelson Elhage at Stripe - And of course, [Sourcegraph](https://about.sourcegraph.com/get-started) ##### Get good monitoring - [Prometheus](https://prometheus.io/) is a time-series metrics tracker and visualizer that's similar to Borgmon. It lets you instrument your application to track metrics like CPU utilization, error rate, and p90 latency that change over time. - [Grafana](https://grafana.com/) is a dashboarding tool similar to Viceroy. A common situation is to connect Grafana with Prometheus, so you can construct a single-page view of a bunch of key metrics that indicate overall application health. - Google pioneered distributed tracing, an essential tool for increasingly common multi-service architectures, with Dapper. One of the creators of Dapper, Ben Sigelman, went on to start [Lightstep](https://lightstep.com/). Distributed tracing is now a feature of many monitoring systems, including paid offerings like [Honeycomb](https://www.honeycomb.io/) and [Sentry](https://sentry.io/) and open-source projects like [Jaeger](https://www.jaegertracing.io/), built by Uber engineers. ##### After you're in good standing: code review 1. It is not straightforward and sometimes not possible to view changes made since the last round of reviews. The easy path only lets you review the entire outstanding diff. 2. There is no support for stacked CRs. 3. The entire diff across all files in the changeset is displayed as one giant page, and it's hard to keep track of what hunks you've reviewed. 4. GitHub PRs are very unopinionated about how reviews should be done. Without adding additional third-party integrations, the review process can seem loosey-goosey, and even with third-party integrations, it still may lack the ability to enforce finer grained review and sign-off policies. 5. There is limited fuzzy jump-to-def or find-references for certain languages, but it is nowhere near the level that Critique supports inside of Google. When selling the benefits of Gerrit, Phabricator, or Reviewable to the rest of your team, it's important to identify the existing pains the team is feeling with their existing code review tool. Here are how some common pain points are addressed by switching from a GitHub-Pull-Request-like tool to a Gerrit-like tool: - Gerrit facilitates a more structured review process, with explicit sign-offs, which can be good if you've grown the team and want to enforce stricter review policies across the organization. - Gerrit makes reviewing larger diffs easier, because you can go file by file, view changes since the last round of review, and stack CRs. This enables faster, more thorough reviews. ### 一点收获 - Tackle big challenges -- #266: Give Me 20 [Ed Gandia](https://b2blauncher.com/author/ifa-admin/) - The first five to 10 ideas flow onto the page very quickly. These are the obvious solutions. - Ideas 11 to 15 take a bit more thinking. - But I HAVE to get to 20. So I push myself. - The best `bien` ideas are almost always in the 16 to 20 group. I’m not sure why that is. My hunch is that those ideas are the product of my subconscious mind, which needs time to do its thing.