> 2021年08月28日信息消化 ### One (Simple) Hack to Get More Website Traffic FastOver the last 3 months, I've generated 8.63 million visits from Google by just using one simple trick. 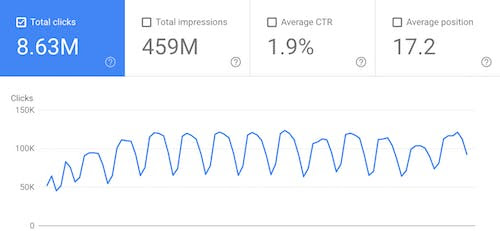 Best of all, I didn’t have to spend any money on ads. Do you want to know how I generated all of those visitors? *It was through a simple hack that I’ve been using for years.* The cool part about it is that it works for any type of website. Here’s what you need to do. **Step #1** - [Head over to Ubersuggest](https://click.convertkit-mail.com/wvullk5w9qs6uw5m05bq/7qh7h8hmwz4gllsz/aHR0cHM6Ly9uZWlscGF0ZWwuY29tL3ViZXJzdWdnZXN0Lw==) and type in your biggest competitor's domain name and hit "search". **Step #2** - On the left-hand navigation click on “top pages”. This will take you to a report that looks something… What this report shows you are all of the top pages on your competition's site. The pages that Google ranks high and drives tons of traffic to. Now, what if that traffic would be going to your website? **Step #3** - Pick one of the top pages on your competition's website that you wish was on your website. I want you to look at the keywords that drive traffic to that page. You'll do this by clicking on the "view all" button under "Estimated Visits (EST Visits)". Once you do that, you’ll see a big list of keywords that drive traffic to that specific page. .jpg) I want you to go through all of the keywords. Even the small ones that drive very little traffic because most of the small ones are easier to rank for and when you combine them it adds up to thousands of visitors. **Step #4** - Export the keywords and create a master list of keywords you want to go after. Keep in mind that all of the keywords your competition ranks for may not be relevant to your business. Hence you want to create a master list. **Step #5** - To get the traffic from your competition you’ll have to produce better content than them. You can either write the content yourself or hire someone to do it for you. Just make sure your content is better than theirs. By creating something that is more in-depth and contains the keywords they are also ranking for, you’ll start seeing your Google traffic go up over time. **Bonus tip** - If you really want to get tons of traffic like me, go through the top 100 pages for each of your competitors and follow the process above. All you are really doing is writing more in-depth content that contains the keywords that your competition is using. ### Here's a tactical approach to learning anything origin: [Here's a tactical approach to learning anything](https://twitter.com/SahilBloom/status/1431586204961677313) The learning framework involves six steps: (1) Identify & Establish (2) Research (3) Skin in the Game (4) Engage Community (5) Teach (6) Reflect & Review The general structure is fixed, but its application is intended to be dynamic & iterative. Let's walk through the steps... ##### Identify & Establish Identify the topic and write down everything you know about it. Put the topic at the top of the page and drop in the extent of your current knowledge below it. I use Notion—I like being able to pull in other links and resources—but anything works. Paradoxically, starting by writing what you do know is the best way to highlight what you don't know. This first action highlights all of the gaps in your knowledge and understanding of the topic. The goal here is to set the stage—establish the holes before filling them. ##### Research This is where the fun begins. The most effective strategy for research: start horizontal, then go vertical. Horizontal = Breadth Vertical = Depth I'll elaborate: When you start horizontal, you gather information across the full breadth of the topic. This gives you the capacity to "see the entire field”—it draws a surface-level map of the topic. With horizontal research, keep it simple: Google and Wikipedia (gasp!) are both great tools. Use your note-taking workspace to document the horizontal information. Note the underlying sources that provided the horizontal information (i.e. look at the Wikipedia footnotes), which come in handy as guideposts to focus your journey when you go vertical. Vertical researchresearch was historically much more challenging—hours of finding and reading long, dense on a topic. But in the Information Age, we have a diverse array of tools that provide much higher timetiempo leverage. Reddit Twitter Newsletters Podcasts Expert Networks Books A few notes on how to use each (which I will expand on in my newsletter): Reddit: Search your topic, find subreddits and threads, read the commentary, click through to the links. Twitter: Find the authority figures, read their writing or comments; DM them if you want more. Newsletters: Thought leaders on the topic are writing one, so read it. Also read what they are consuming (I use Faves for this). Podcasts: Focus on primary sources (discussions with founders, leaders, etc.); listen on 1.25x or 1.5x speed to cut through. https://web.faves.media/signup.html?r=sahil Expert Networks: You can often get free trial periods or read/listen to expert call transcripts cost-effectively. **Books: Don't read the old way (cover to cover); find sections or chapters that grab you, dive in there.** These six vertical research tools will take you a long way. ##### Skin in the Game If you want to accelerate your learning curve, put some skin in the game. Skin in the game raises the stakes of your learning. It is a behavioral trick to build deeper incentives. "Skin" can be literal (money) or metaphorical (personal public commitment). Want to learn more about a specific company? Buy a few shares of the stock. **Want to learn about Web 3.0? Buy an NFT, post it as your photo, join the Discord community.** Want to write an article on X? Commit to it publicly (I do this all the time to force myself to write!). In addition to raising the stakes, skin in the game gets you "in it" from a community perspective. You'll never learn as much from the outside looking in. You need to get inside. Skin in the game is your ticket to join the community. Now that you're in, it's time to engage. ##### Engage Community Learning is communal, not individual. Engage with the community to accelerate learning. As anyone who has ever learned a new language knows—immersion is an incredibly powerful force. Two pieces of tactical advice: (1) Talk to authorities (2) Phone friends Find a few authorities on the topic—DM, email, call them, ask questions. Call 3-5 friends and talk about what you are learning. They will ask questions that expose holes in your knowledge and point out opinions that will force you to think more deeply. Community is the key. ##### Teach If you want to learn, teach. The `@ProfFeynman` Technique: Use simple language (no jargon or acronyms!) to explain what you've learned to a few people. If you can't explain it to a 5-year-old, you probably don't understand it well enough (yet). ##### Reflect & Review The learning process is iterative and fluid. Reflect on the gaps in your knowledge that were exposed—dive deeper to fill them in. Review your note-taking workspace. Zoom out to get a full picture of your new learnings. ### UNDERSTANDING IS A POOR SUBSTITUTE FOR CONVEXITY (ANTIFRAGILITY) origin: [UNDERSTANDING IS A POOR SUBSTITUTE FOR CONVEXITY (ANTIFRAGILITY)](https://www.edge.org/conversation/nassim_nicholas_taleb-understanding-is-a-poor-substitute-for-convexity-antifragility) The point we will be making here is that logically, neither trial and error nor "chance" and serendipity can be behind the gains in technology and empirical science attributed to them. By definition chance cannot lead to long term gains (it would no longer be chance); trial and error cannot be unconditionally effective: errors cause planes to crash, buildings to collapse, and knowledge to regress. 我们在这里要说明的是,从逻辑上讲,无论是试错还是 "机会 "和偶然性,都不可能是归功于技术和经验科学的成果的背后。根据定义,机会不可能导致长期的收益(它将不再是机会);试错不可能无条件地有效:错误导致飞机坠毁,建筑物倒塌,知识倒退。 NASSIM NICHOLAS TALEB, essayist and former mathematical trader, is Distinguished Professor of Risk Engineering at NYU’s Polytechnic Institute. He is the author the international bestseller The Black Swan and the recently published Antifragile: Things That Gain from Disorder. (US: Random House; UK: Penguin Press) UNDERSTANDING IS A POOR SUBSTITUTE FOR CONVEXITY (ANTIFRAGILITY) Something central, very central, is missing in historical accounts of scientific and technological discovery. The discourse and controversies focus on the role of luck as opposed to teleological programs (from *telos,* "aim"), that is, ones that rely on pre-set direction from formal science. This is a faux-debate: luck cannot lead to formal research policies; one cannot systematize, formalize, and program randomness. The driver is neither luck nor direction, but must be in the asymmetry (or convexity) of payoffs, a simple mathematical property that has lied hidden from the discourse, and the understanding of which can lead to precise research principles and protocols. 在科学和技术发现的历史叙述中,缺少一些核心的、非常核心的东西。论述和争论的焦点是运气的作用,而不是目的论的方案(来自*telos,*"目的"),也就是说,那些依靠正规科学预先设定的方向的方案。这是一场虚假的争论:运气不能导致正式的研究政策;人们不能将随机性系统化、正规化和程序化。驱动力既不是运气,也不是方向,而必须是回报的不对称性(或凸性),这是一个简单的数学属性,一直被隐藏在话语中,而对它的理解可以导致精确的研究原则和协议。 **MISSING THE ASYMMETRY** The luck versus knowledge story is as follows. Ironically, we have vastly more evidence for results linked to luck than to those coming from the teleological, outside physics—even after discounting for the sensationalism. In some opaque and nonlinear fields, like medicine or engineering, the teleological exceptions are in the minority, such as a small number of designer drugs. This makes us live in the contradiction that we largely got here to where we are thanks to undirected chance, but we build research programs going forward based on direction and narratives. And, what is worse, we are fully conscious of the inconsistency. 运气与知识的故事如下。具有讽刺意味的是,我们有更多的证据证明与运气有关的结果,而不是那些来自目的论的外部物理学的结果--即使在扣除了耸人听闻的因素之后。在一些不透明和非线性的领域,如医学或工程,目的论的例外是少数,如少量的设计药物。这使我们生活在这样的矛盾中:我们在很大程度上是由于不定向的机会才走到今天的,但我们却根据方向和叙述来建立前进的研究计划。而且,更糟糕的是,我们完全意识到了这种不一致。 The point we will be making here is that logically, neither trial and error nor "chance" and serendipity can be behind the gains in technology and empirical science attributed to them. By definition chance cannot lead to long term gains (it would no longer be chance); trial and *error* cannot be unconditionally effective: errors cause planes to crash, buildings to collapse, and knowledge to regress. 我们在这里要说明的是,从逻辑上讲,无论是试验和错误,还是 "机会 "和偶然性,都不可能是归功于技术和经验科学的成果背后。根据定义,偶然性不可能导致长期的收益(它将不再是偶然性);试错和*错误不可能无条件地有效:错误导致飞机坠毁,建筑物倒塌,知识倒退。 The beneficial properties have to reside in the type of exposure, that is, the payoff function and not in the "luck" part: there needs to be a significant asymmetry between the gains (as they need to be large) and the errors (small or harmless), and it is from such asymmetry that luck and trial and error can produce results. The general mathematical property of this asymmetry is convexity (which is explained in Figure 1); functions with larger gains than losses are nonlinear-convex and resemble financial options. Critically, convex payoffs benefit from uncertainty and disorder. The nonlinear properties of the payoff function, that is, convexity, allow us to formulate rational and rigorous research policies, and ones that allow the harvesting of randomness. 有益的特性必须存在于暴露的类型中,即回报函数,而不是 "运气 "部分:在收益(因为它们需要大)和错误(小或无害)之间需要有明显的不对称性,正是从这种不对称性中,运气和试错可以产生结果。这种不对称性的一般数学属性是凸性(在图1中解释);收益大于损失的函数是非线性凸性的,类似于金融期权。最关键的是,凸形报酬率从不确定性和无序性中获益。报酬函数的非线性特性,即凸性,使我们能够制定合理和严格的研究政策,以及允许收获随机性的政策。 **OPAQUE SYSTEMS AND OPTIONALITY** Further, it is in complex systems, ones in which we have little visibility of the chains of cause-consequences, that tinkering, bricolage, or similar variations of trial and error have been shown to vastly outperform the teleological—it is nature's modus operandi. But tinkering needs to be convex; it is imperative. Take the most opaque of all, cooking, which relies entirely on the heuristics of trial and error, as it has not been possible for us to design a dish directly from chemical equations or reverse-engineer a taste from nutritional labels. We take hummus, add an ingredient, say a spice, taste to see if there is an improvement from the complex interaction, and retain if we like the addition or discard the rest. Critically we have the option, not the obligation to keep the result, which allows us to retain the upper bound and be unaffected by adverse outcomes. 此外,正是在复杂的系统中,在我们对因果链几乎一无所知的情况下,修修补补、杂乱无章或类似的试错变化已被证明大大超过了目的论--这是大自然的操作方式。但修修补补必须是凸的;它是必须的。以最不透明的烹饪为例,它完全依赖于试错的启发式方法,因为我们不可能直接从化学方程式中设计出一道菜,也不可能从营养标签中反向设计出一种味道。我们拿着鹰嘴豆泥,添加一种成分,比如说一种香料,品尝一下,看看这种复杂的互动是否有改善,如果我们喜欢这种添加物,就保留,否则就抛弃其他的。关键是我们有选择权,而不是保留结果的义务,这使我们能够保留上限,不受不利结果的影响。 This "optionality" is what is behind the convexity of research outcomes. An option allows its user to get more upside than downside as he can select among the results what fits him and forget about the rest (he has the option, not the obligation). Hence our understanding of optionality can be extended to research programs — this discussion is motivated by the fact that the author spent most of his adult life as an option trader. If we translate François Jacob's idea into these terms, evolution is a convex function of stressors and errors —genetic mutations come at no cost and are retained only if they are an improvement. So are the ancestral heuristics and rules of thumbs embedded in society; formed like recipes by continuously taking the upper-bound of "what works". But unlike nature where choices are made in an automatic way via survival, human optionality requires the exercise of rational choice to ratchet up to something better than what precedes it —and, alas, humans have mental biases and cultural hindrances that nature doesn't have. Optionality frees us from the straightjacket of direction, predictions, plans, and narratives. (To use a metaphor from information theory, if you are going to a vacation resort offering you more options, you can predict your activities by asking a smaller number of questions ahead of time.) 这种 "可选择性 "是研究成果凸性的背后原因。选择权允许其使用者获得更多的好处而不是坏处,因为他可以在结果中选择适合自己的,而忘记其他的(他有选择权而不是义务)。因此,我们对期权性的理解可以扩展到研究项目上--这个讨论的动机是,作者成年后的大部分时间都是在做期权交易员。如果我们把弗朗索瓦-雅各布的想法翻译成这些术语,进化是压力源和错误的凸函数--基因突变是没有成本的,只有当它们是一种改进时才会保留。嵌入社会的祖先启发式方法和拇指规则也是如此;就像食谱一样,通过不断采取 "可行的东西 "的上限而形成。但与自然界不同的是,自然界的选择是通过生存的方式自动做出的,而人类的选择权需要行使理性的选择来提升到比之前更好的东西--唉,人类有自然界所没有的心理偏见和文化障碍。选择性将我们从方向、预测、计划和叙述的束缚中解放出来。(用信息论的一个比喻来说,如果你要去一个为你提供更多选择的度假胜地,你可以通过提前问较少的问题来预测你的活动)。) While getting a better recipe for hummus will not change the world, some results offer abnormally large benefits from discovery; consider penicillin or chemotherapy or potential clean technologies and similar high impact events ("Black Swans"). The discovery of the first antimicrobial drugs came at the heel of hundreds of systematic (convex) trials in the 1920s by such people as Domagk whose research program consisted in trying out dyes without much understanding of the biological process behind the results. And unlike an explicit financial option for which the buyer pays a fee to a seller, hence tend to trade in a way to prevent undue profits, benefits from research are not zero-sum. 虽然得到一个更好的鹰嘴豆泥的配方不会改变世界,但有些结果提供了异常大的发现利益;考虑青霉素或化疗或潜在的清洁技术和类似的高影响事件("黑天鹅")。第一批抗菌药物的发现是在20世纪20年代由多马格克等人进行的数百次系统(凸面)试验的基础上发现的,其研究计划包括尝试染料,但对结果背后的生物过程没有太多的了解。而且,与明确的金融期权不同,买方要向卖方支付费用,因此倾向于以防止不正当利润的方式进行交易,研究带来的利益不是零和的。 **THINGS LOVE UNCERTAINTY** What allows us to map a research funding and investment methodology is a collection of mathematical properties that we have known heuristically since at least the 1700s and explicitly since around 1900 (with the results of Johan Jensen and Louis Bachelier). These properties identify the inevitability of gains from convexity and the counterintuitive benefit of uncertainty ii iii. Let us call the "convexity bias" the difference between the results of trial and error in which gains and harm are equal (linear), and one in which gains and harm are asymmetric ( to repeat, a convex payoff function). The central and useful properties are that a) The more convex the payoff function, expressed in difference between potential benefits and harm, the larger the bias. b) The more volatile the environment, the larger the bias. This last property is missed as humans have a propensity to hate uncertainty. 让我们能够描绘出研究资金和投资方法的是一组数学属性,我们至少从1700年起就以启发式的方式知道这些属性,并从1900年左右开始明确知道这些属性(Johan Jensen和Louis Bachelier的成果)。这些属性确定了凸性收益的必然性和不确定性的反直觉收益②③。让我们把 "凸性偏差 "称为收益和损害相等(线性)的试错结果与收益和损害不对称的试错结果之间的差异(重复,凸性报酬函数)。核心和有用的属性是:a) 报酬函数越凸,用潜在的利益和伤害之间的差异表示,偏差越大;b) 环境越不稳定,偏差越大。最后一个属性被忽略了,因为人类有讨厌不确定性的倾向。 *Antifragile* is the name this author gave (for lack of a better one) to the broad class of phenomena endowed with such a convexity bias, as they gain from the "disorder cluster", namely volatility, uncertainty, disturbances, randomness, and stressors. The antifragile is the exact opposite of the fragile which can be defined as hating disorder. A coffee cup is fragile because it wants tranquility and a low volatility environment, the antifragile wants the opposite: high volatility increases its welfare. This latter attribute, gaining from uncertainty, favors optionality over the teleological in an opaque system, as it can be shown that the teleological is hurt under increased uncertainty. The point can be made clear with the following. When you inject uncertainty and errors into airplane ride (the fragile or concave case) the result is worsened, as errors invariably lead to plane delays and increased costs —not counting a potential plane crash. The same with bank portfolios and fragile constructs. But it you inject uncertainty into a convex exposure such as some types of research, the result improves, since uncertainty increases the upside but not the downside. This differential maps the way. The convexity bias, unlike serendipity et al., can be defined, formalized, identified, even on the occasion measured scientifically, and can lead to a formal policy of decision making under uncertainty, and classify strategies based on their *ex ante* predicted efficiency and projected success, as we will do next with the following 7 rules. 反脆弱是这位作者给被赋予这种凸性偏差的一大类现象起的名字(因为缺乏更好的名字),因为它们从 "无序群 "中获得了好处,即波动性、不确定性、干扰、随机性和压力源。反脆弱的人与脆弱的人正好相反,脆弱的人可以被定义为讨厌无序。一个咖啡杯是脆弱的,因为它想要宁静和低波动的环境,反脆弱的人想要相反的东西:高波动性增加它的福利。后一种属性,即从不确定性中获得的属性,在一个不透明的系统中有利于选择权而不是目的论,因为可以证明目的论在不确定性增加的情况下会受到伤害。这一点可以用下面的例子来说明。当你把不确定性和错误注入到飞机驾驶中(脆弱或凹陷的情况),结果就会恶化,因为错误总是导致飞机延误和成本增加--还不算潜在的飞机坠毁。银行投资组合和脆弱的结构也是如此。但如果你把不确定性注入凸形风险,如某些类型的研究,结果就会改善,因为不确定性会增加上升空间,但不会增加下降空间。这种差异映射出的方式。凸性偏差,与偶然性等不同,可以被定义,正式化,识别,甚至在场合上被科学地测量,并可以导致在不确定性下的决策的正式政策,并根据其事先预测的效率和预测的成功对战略进行分类,正如我们接下来要做的7条规则。  *Figure 2 The Antifragility Edge (Convexity Bias). A random simulation shows the difference between a) the process with convex trial and error (antifragile) b) a process of pure knowledge devoid of convex tinkering (knowledge based), c) the process of nonconvex trial and error; where errors are equal in harm and gains (pure chance). As we can see there are domains in which rational and convex tinkering dwarfs the effect of pure knowledge iv.* 图2 反脆弱的边缘(凸性偏差)。一个随机模拟显示了a)有凸性试错的过程(反脆弱性)b)没有凸性修补的纯知识过程(基于知识),c)非凸性试错的过程;其中错误的危害和收益相等(纯偶然)。我们可以看到,在一些领域,理性和凸形修补的效果使纯知识的效果相形见绌 iv. 1) Convexity is easier to attain than knowledge (in the technical jargon, the "long-gamma" property) 凸性比知识更容易达到(用技术术语说,就是 "长伽马 "属性)。 2) A "1/N" strategy is almost always best with convex strategies (the dispersion property) 一个 "1/N "的策略几乎总是凸的策略最好(分散属性 3) Serial optionality (the cliquet property) 串行选择权(cliquet属性) 4) Nonnarrative Research (the optionality property) 非叙述性研究(期权性属性 5) Theory is born from (convex) practice more often than the reverse (the nonteleological property) 理论诞生于(凸)实践,而不是相反(非特洛伊特性)。 6) Premium for simplicity (the less-is-more property) 简单性的好处(少即是多的特性 7) Better cataloguing of negative results (the via negativa property) 对负面结果进行更好的编目(通过否定属性)。 ## Misc - [the perfect emojis for ratings](https://www.reddit.com/r/Notion/comments/pcss42/finally_found_the_perfect_emojis_for_ratings/) <img src="https://raw.githubusercontent.com/Phalacrocorax/memo-image-host/master/PicGo/7mctpdtlyxj71.png" alt="r/Notion - Finally found the perfect emojis for ratings ????????????????????" style="zoom: 50%;" /> - GitHub 仓库页面按下小数点键 `.` 就可以自动使用VS Code的Web版打开仓库。编辑完成后可以推送回GitHub。`twitter@ruanf`