> 2021年12月18日信息消化 ### 7 Code Patterns in Go I Can’t Live Without > MEMO > > 长见识,自己的话大概会准备 `url string` + `visited bool`, 但是map的话可以一个数据结构解决,并且go下用 `visited map[string]struct{}` 性能还要好于 `visited map[string]bool` origin: [7 Code Patterns in Go I Can’t Live Without](https://betterprogramming.pub/7-code-patterns-in-go-i-cant-live-without-f46f72f58c4b) #### Use Maps as a Set We often need to check the existence of something. For example, we might want to check if a file path/URL/ID has been visited before. In these cases, we can use `map[string]struct{}`. For example:  Using an empty struct, `struct{}`, means we don’t want the value part of the map to take up any space. Sometimes people use `map[string]bool`, but benchmarks have shown that `map[string]struct{}` perform better both in memory and time. It’s also worth mentioning that map operations are generally considered to have **O(1)** time complexity ([StackOverflow](https://stackoverflow.com/questions/29677670/what-is-the-big-o-performance-of-maps-in-golang)), but go runtime provides no such guarantee. #### Using chan struct{} to Synchronize Goroutines Channels can carry data, but they don’t have to. Sometimes, we just need them for synchronization purposes. In the following case, the channel carries a data type `struct{}`, which is an empty struct that takes up no space. This is the same trick as in the previous map example: 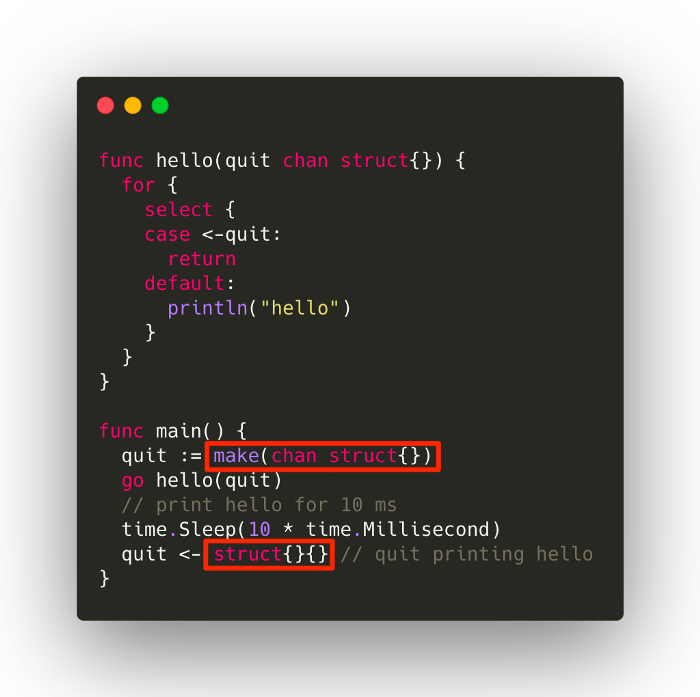 #### Use Close to Broadcast Continuing with the previous example, if we run multiple `go hello(quit)`, then instead of sending multiple `struct{}{}` to `quit`, we can just close the `quit `channel to broadcast the signal: 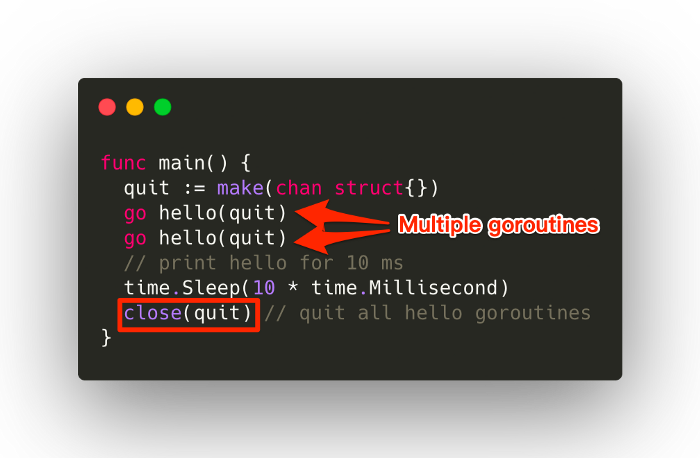 Note that closing a channel to broadcast a signal works with any number of goroutines, so `close(quit)` also applies in the previous example. #### Use a Nil Channel to Block a Select Case Sometimes we need to disable certain cases in the select statement, like in the following function, which reads from an event source and sends events to the dispatch channel. (This kind of function normally involves the processing of raw data to form an event objects, but let’s cut to the chase here).  Things we want to improve: - disable `case s.dispatchC` when `len(pending) == 0` so that the code won’t panic - disable `case s.eventSource` when `len(pending) >= maxPending` to avoid allocating too much memory 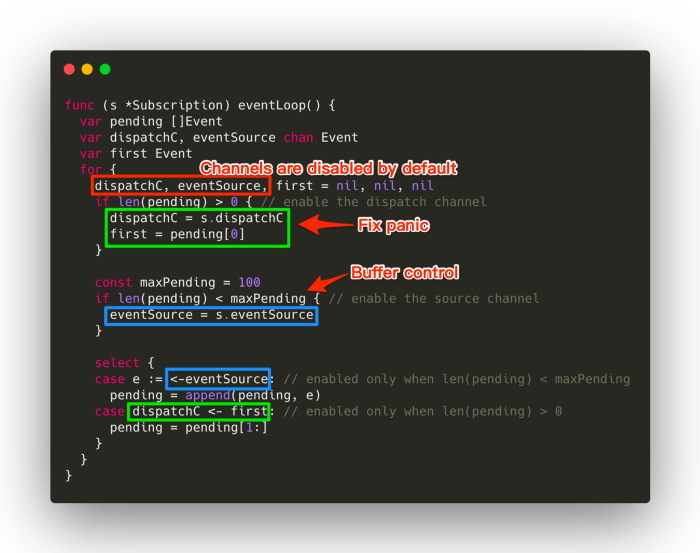 The trick here is to use an extra variable to turn on/off the original channel, and then put that variable to use in the select case. #### Non-blocking Read From a Channel Sometimes we want to offer services in the sense of “best-effort”. That is, we want the channel to be “lossy” on purpose. This makes sense when, for example, we have an excessive number of events to dispatch to receivers, and some of them might not be responsive. We can ignore those non-responsive receivers to: 1. Dispatch to other receivers in time 2. Avoid allocating too much memory for pending events  ### System design hack: Postgres is a great pub/sub & job server origin: [Postgres is a great pub/sub and job server (2019) (webapp.io)](https://news.ycombinator.com/item?id=29599132) #### Postgres is an amazing relational database It's possible to scale Postgres to storing a billion 1KB rows entirely in memory - This means you could quickly run queries against the full name of everyone on the planet on commodity hardware and with little fine-tuning. I'm not going to belabor the point that something called "PostgresSQL" is a good SQL database. I'll show you a more interesting use case for it where we combine a few features to turn Postgres into a powerful pubsub / job server #### Postgres makes a great persistent pubsub server If you do enough system design, you'll inevitably need to solve a problem with **publish/subscribe** architecture. We hit it quickly at webapp.io - we needed to keep the viewers of a test run's page and the github API notified about a run as it progressed. For your pub/sub server, you have a lot of options: - [Kafka](https://kafka.apache.org/) - [RabbitMQ](https://www.rabbitmq.com/) - [Redis PUB/SUB](https://redis.io/topics/pubsub) - A [vendor](https://aws.amazon.com/sqs/) [locked](https://cloud.google.com/pubsub/docs/overview) [cloud](https://docs.microsoft.com/en-us/azure/event-grid/) [provider](https://docs.microsoft.com/en-us/azure/event-grid/) [solution](https://docs.microsoft.com/en-us/azure/service-bus-messaging/) - Postgres? There are very few use cases where you'd need a dedicated pub/sub server like Kafka. Postgres can [easily handle 10,000 insertions per second](https://severalnines.com/blog/benchmarking-postgresql-performance), and it can be tuned to even higher numbers. It's rarely a mistake to start with Postgres and then switch out the most performance critical parts of your system when the time comes. #### Pub/sub + atomic operations ⇒ no job server necessary. In the list above, I skipped things similar to pub/sub servers called "job queues" - they only let one "subscriber" watch for new "events" at a time, and keep a queue of unprocessed events: - [Celery](http://www.celeryproject.org/) - [Gearman](http://gearman.org/) It turns out that Postgres generally supersedes job servers as well. You can have your workers "watch" the "new events" channel and try to claim a job whenever a new one is pushed. As a bonus, Postgres lets other services watch the status of the events with no added complexity. #### Our use case: CI runs processed by sequential workers At webapp.io, we run "test runs", which start by cloning a repository, and then running some user specified tests. There are microservices that do various initialization steps for the test run, and additional microservices (such as the websocket gateway) that need to listen to the status of the runs.  An instance of an API server creates a run by inserting a row into the "Runs" row of a Postgres table: ```sql CREATE TYPE ci_job_status AS ENUM ('new', 'initializing', 'initialized', 'running', 'success', 'error'); CREATE TABLE ci_jobs( id SERIAL, repository varchar(256), status ci_job_status, status_change_time timestamp ); /*on API call*/ INSERT INTO ci_job_status(repository, status, status_change_time) VALUES ('https://github.com/colinchartier/layerci-color-test', 'new', NOW()); ``` How do the workers worker "claim" a job? By setting the job status atomically: ```sql UPDATE ci_jobs SET status='initializing' WHERE id = ( SELECT id FROM ci_jobs WHERE status='new' ORDER BY id FOR UPDATE SKIP LOCKED LIMIT 1 ) RETURNING *; ``` Finally, we can use a trigger and a channel to notify the workers that there might be new work available: ```sql CREATE OR REPLACE FUNCTION ci_jobs_status_notify() RETURNS trigger AS $$ BEGIN PERFORM pg_notify('ci_jobs_status_channel', NEW.id::text); RETURN NEW; END; $$ LANGUAGE plpgsql; CREATE TRIGGER ci_jobs_status AFTER INSERT OR UPDATE OF status ON ci_jobs FOR EACH ROW EXECUTE PROCEDURE ci_jobs_status_notify(); ``` All the workers have to do is "listen" on this status channel and try to claim a job whenever a job's status changes: ```go tryPickupJob := make(chan interface{}) //equivalent to 'LISTEN ci_jobs_status_channel;' listener.Listen("ci_jobs_status_channel") go func() { for event := range listener.Notify { select { case tryPickupJob <- true: } } close(tryPickupJob) } for job := range tryPickupJob { //try to "claim" a job } ```  This architecture scales to many sequential workers processing the job in a row, all you need is a "processing" state and a "processed" state for each worker. For webapp.io that looks like: new, initializing, initialized, running, complete. It also allows other services to watch the `ci_jobs_status_channel` - Our websocket gateway for the /run page and github notification services simply watch the channel and notify any relevant parties of the published events. ### Hello IPv6: a minimal tutorial for IPv4 users origin: [Hello IPv6: a minimal tutorial for IPv4 users](https://metebalci.com/blog/hello-ipv6/) #### Introduction It might be a bit funny to call this post “Hello IPv6”, since the first draft of IPv6 was published in late 1998; however, it is ratified as a standard only in 2017. When I first heard about IPv6 many years ago, I thought it only provides a larger address space than IPv4. This is correct, but there is more. Even for a home network, or for a small network, there are some basic differences. Some of the terms, protocols etc. that was so much in use in IPv4, that most of us learned and maybe internalized, either radically changed or disappeared in IPv6. In this post, I explain how the well-known IPv4 concepts work in IPv6. **This post is aimed for home and small office networks**. So if you know about ARP, DHCP, and NAT, and if you wonder how these work in IPv6 networks, this post is perfect for you. If you already know about IPv6 addresses, NDP, RA, PD, SLAAC, and DHCPv6, there is nothing new here. All command examples are from Ubuntu 18.04.4 Linux. I am using a [Ubiquiti EdgeRouter 4](https://www.ui.com/edgemax/edgerouter-4/), an [HPE 1920](https://h20195.www2.hpe.com/v2/GetPDF.aspx/c04394247.pdf) Switch and an embedded Linux Computer [PC Engines apu4d4](https://pcengines.ch/apu4d4.htm) with 4 ethernet ports running Ubuntu 18.04.4 Linux and my ISP is [init7](https://www.init7.net/). The fiber cable from OTO is terminated at the SFP module plugged to HP 1920. This port is mirrored to another one which is connected to apu4d4. The SFP port is connected to the WAN port of the router. apu4d4 is also connected to LAN. That is how I use tcpdump both on WAN and on the LAN side. #### Summary Here is an extremely short summary. - IPv6 has a different Ethernet frame type. - IPv6 address is 128-bit with 64-bit (network) prefix and 64-bit interface id. - IPv6 does not use ARP but NDP. - IPv6 has no broadcast address concept; some multicast addresses play this function. - IPv6 addresses can be dynamically configured like DHCPv4 but also, and probably more often, they can be configured without keeping a state, using a combination of DHCPv6, RA, PD, and SLAAC. - NAT is not necessary for IPv6. - If needed, for privacy reasons, a random and temporary IPv6 address can be used. Here is a simple diagram of what is going on. 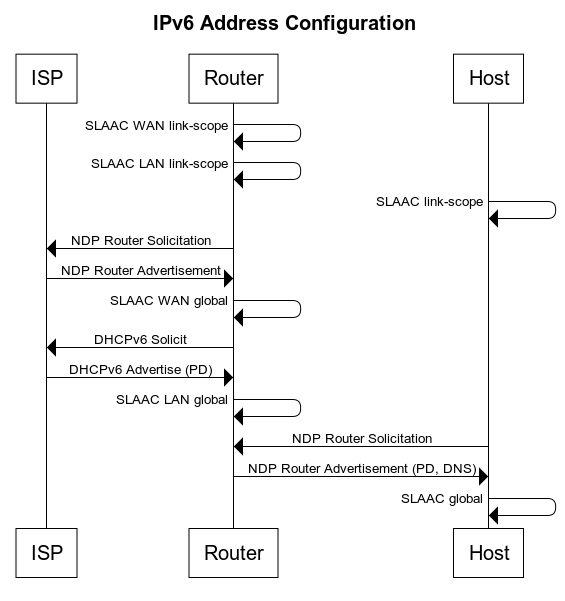 ##### Ethernet: different ethernet frame type *Both IPv4 and IPv6 can and do work with networking technologies other than Ethernet, such as FDDI, but Ethernet is the most relevant one for the purpose of this post.* IPv6 works over ethernet like IPv4, and since ethernet is designed to be agnostic to the higher level (Layer 3) protocol (such as IP) carried in its payload, there is no surprise here. The only difference is the type field in Ethernet frame is `0x0800` for IPv4, but `0x86DD` for IPv6. IPv6 像 IPv4 一样在以太网上工作,并且由于以太网被设计为与其有效载荷中承载的更高级别(第 3 层)协议(例如 IP)无关,因此这里并不奇怪。唯一的区别是以太网帧中的类型字段对于 IPv4 是 0x0800,对于 IPv6 是 0x86DD。 The output below is generated by `ping6 2001:4860:4860::8888`. This is one of Google’s public DNS servers (IPv6 address of 8.8.8.8). ```bash $ sudo tcpdump -vv -i enp1s0 -n -e icmp6 17:31:47.792214 00:0d:b9:55:66:08 > b4:fb:e4:8a:fa:de, ethertype IPv6 (0x86dd), length 118: (flowlabel 0x5640f, hlim 64, next-header ICMPv6 (58) payload length: 64) 2a02:168:91d5:1:20d:b9ff:fe55:6608 > 2001:4860:4860::8888: [icmp6 sum ok] ICMP6, echo request, seq 1 17:31:47.793637 b4:fb:e4:8a:fa:de > 00:0d:b9:55:66:08, ethertype IPv6 (0x86dd), length 118: (flowlabel 0x5640f, hlim 56, next-header ICMPv6 (58) payload length: 64) 2001:4860:4860::8888 > 2a02:168:91d5:1:20d:b9ff:fe55:6608: [icmp6 sum ok] ICMP6, echo reply, seq 1 ``` You can see ethertype is `0x86dd`. ##### IP addressing: from v4 to v6, from 4-bytes to 16-bytes, scope and lifetime IPv6 addresses are 128-bit or 16 bytes. They are written as `x:x:x:x:x:x:x:x`, where x is a 2-byte hexadecimal number written as one to four hexadecimal number. Examples: - `2a02:168:91d5:1:20d:b9ff:fe55:6608`, leading zeroes in fields can be omitted (e.g. 168 and 1, instead of 0168 and 0001), but there has to be at least one number, a zero field 0000 has to be written as single 0. - `2001:4860:4860::8888`, :: is a shortcut for a long string of zeroes from the left to the right, it may span multiple fields. There can be only one :: in an address. This address is actually `2001:4860:4860:0000:0000:0000:0000:8888`. - `::1`, means all zeroes with a single 1 at the right, `0000:0000:0000:0000:0000:0000:0000:0001`. IPv6 addresses consist of a subnet prefix and an interface identifier. IPv6 addressing is essentially classless, meaning some number of bits represents prefix (but for unicast addresses it is 64-bit, more on this soon). IPv6 地址由子网前缀和接口标识符组成。 IPv6 寻址本质上是无类别的,这意味着一些位代表前缀(但对于单播地址,它是 64 位,稍后会详细介绍)。 `subnet prefix [0-n]` | `interface id [n-128]` The subnet prefix is also represented similar to IPv4, in /x format, where x is the number of bits from the left. These are the important address types: - `::1/128`, loopback address (e.g. localhost) - `fe80::/10`, link-local unicast addresses (subnet prefix `fe8`) - `ff00::/8`, multicast addresses (subnet prefix `ff`) - all other addresses are global unicast addresses (with a few exceptions) All IPv6 addresses have a scope. The most common ones and the only two scopes used by unicast addresses are `link-local` and `global`. A link-local address is permitted to be used only in one LAN segment (subnet). A global address can be used on the internet. 所有 IPv6 地址都有一个范围。单播地址使用的最常见和仅有的两个范围是链路本地和全局。链路本地地址只允许在一个 LAN 段(子网)中使用。可以在 Internet 上使用全局地址。 An interface has to have at least one link-local address, and it can have many addresses. This is one of the things it looks strange for IPv4 users because we are used to seeing only one IP on one interface, whereas on IPv6, an interface usually has two (one link-local, one global) or more (more than one global) addresses. 一个接口必须至少有一个本地链路地址,它可以有多个地址。这是 IPv4 用户看起来很奇怪的事情之一,因为我们习惯于在一个接口上只看到一个 IP,而在 IPv6 上,一个接口通常有两个(一个本地链路,一个全局)或更多(多个全局) 地址。 The interface identifier naturally has to be unique within a subnet. For all unicast addresses, the interface identifier has to be 64-bit, that means prefix also has to be 64-bit. The most common method to generate an interface identifier is from the MAC address, but it can be generated also in different ways. There is a simple algorithm called [modified EUI-64](https://en.wikipedia.org/wiki/IPv6_address#Modified_EUI-64) to generate a 64-bit interface id from a 48-bit MAC address. 接口标识符在子网内自然必须是唯一的。对于所有单播地址,接口标识符必须是 64 位,这意味着前缀也必须是 64 位。生成接口标识符的最常用方法是从 MAC 地址生成,但也可以通过不同方式生成。有一个简单的算法叫做修改 EUI-64,可以从 48 位 MAC 地址生成 64 位接口 ID。 After configured, all addresses are checked in the subnet for potential duplicates. For global unicast addresses, subnet prefix is composed of a routing prefix and a subnet id. The routing prefix is typically something assigned to the link (meaning to your connection) by the ISP, and you can then freely choose different subnet ids. 对于全球单播地址,子网前缀由路由前缀和子网 id 组成。路由前缀通常是由 ISP 分配给链接(即您的连接)的东西,然后您可以自由选择不同的子网 ID。 `global routing prefix [0-n]` | `subnet id [n-64]` | `interface id [64-128]` The global routing prefix is, as far as I know, something between `/48` and `/64`, and this is decided by the ISP. If it is `/64`, it means you have only one subnet which is already given to you by the ISP. [My ISP gives `/48`](https://www.init7.net/en/support/faq/Fiber7-IPv6/), so I have a 16-bit subnet id, and I can have `2^16=65536` subnets. After IPv4, the vast size of IPv6 feels strange, in each of 65536 subnets, I can have `2^64=a really big 20-digit number` global IPv6 addresses. 全局路由前缀,据我所知,介于 /48 和 /64 之间,这是由 ISP 决定的。如果是/64,则意味着您只有一个ISP已经给您的子网。我的 ISP 提供 /48,所以我有一个 16 位的子网 ID,我可以有 2^16=65536 个子网。 IPv4之后,IPv6的庞大规模感觉很奇怪,在65536个子网中的每个子网中,我可以拥有2^64=一个非常大的20位数字全球IPv6地址。 For a link-local address, the prefix is fixed, `fe8` (10-bit) plus zeroes (54-bit) to fill 64-bit and then 64-bit interface id. So link-local addresses usually looks like `fe80::...` because of the zeroes. All IPv6 addresses (even the loopback one) have a lifetime, which can be infinite/forever. This is similar to DHCPv4, but it is enforced by the host itself independent of a DHCP service is used or not. 所有 IPv6 地址(甚至环回地址)都有一个生命周期,可以是无限的/永远的。这类似于 DHCPv4,但它是由主机本身强制执行的,与是否使用 DHCP 服务无关。 `ip` command in Linux with `-6` option shows only IPv6 related configuration. ```bash $ ip -6 address 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 state UNKNOWN qlen 1000 inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 state UP qlen 1000 inet6 2a02:168:91d5:1:20d:b9ff:fe55:6608/64 scope global dynamic mngtmpaddr noprefixroute valid_lft 3252sec preferred_lft 3252sec inet6 fe80::20d:b9ff:fe55:6608/64 scope link valid_lft forever preferred_lft forever ``` The interface `lo` is the loopback interface. The loopback address is always `::1/128`. It says scope=host above, but technically loopback address has link-local scope. This is 127.0.0.1 in IPv4. The interface `enp1s0` has two IPv6 addresses: - First is a global dynamically configured address. Pay attention to `scope global` and `dynamic` flags. The prefix of the global address is `2a02:168:91d5:1` and it is received from the routers, we cannot know the routing prefix and subnet id only from the address, more about this later. - Second is a link-local address. Pay attention to `scope link` flag. The link-local address is always in the `fe80::/10` network. You may have already realized that the last 64-bit (`20d:b9ff:fe55:6608`) of both global and link-local addresses is the same. This is because both of these addresses are autoconfigured and the autoconfiguration uses the same algorithm (modified EUI-64) deriving interface id from the MAC address. 您可能已经意识到全局地址和链接本地地址的最后 64 位 (20d:b9ff:fe55:6608) 是相同的。这是因为这两个地址都是自动配置的,并且自动配置使用相同的算法(修改的 EUI-64)从 MAC 地址派生接口 ID。 ##### Address resolution: from ARP to NDP IPv4 address to MAC address resolution is done using ARP in IPv4. There is a significant change here because there is no ARP for IPv6. IPv6 uses a new protocol, Neighbor Discovery Protocol (NDP), particularly Neighbor Solicitation (Type 135) and Neighbor Advertisement (136) packet types. IPv4 地址到 MAC 地址的解析是在 IPv4 中使用 ARP 完成的。这里有一个重大变化,因为 IPv6 没有 ARP。 IPv6 使用新协议,即邻居发现协议 (NDP),特别是邻居请求(类型 135)和邻居广告(136)数据包类型。 NDP Type 135 and Type 135 is functionally similar to ARP, one host asks all hosts for a link-address (MAC address) of an IPv6 address, and if a host has this IPv6 address, it replies with its link-address. A major difference is while ARP messages have their own ethertype (different than IPv4 ethertype), NDP is based on ICMPv6 (i.e. it defines new ICMP packet types), which are carried in an ethernet packet with IPv6 type. So ARP is an OSI Layer 2 (L2) protocol, whereas NDP is L3. NDP Type 135和Type 135在功能上与ARP类似,一台主机向所有主机询问一个IPv6地址的链路地址(MAC地址),如果一台主机有这个IPv6地址,它就会回复它的链路地址。一个主要的区别是 ARP 消息有自己的以太类型(不同于 IPv4 以太类型),而 NDP 基于 ICMPv6(即它定义了新的 ICMP 数据包类型),它们在具有 IPv6 类型的以太网数据包中携带。所以 ARP 是 OSI 第 2 层 (L2) 协议,而 NDP 是 L3。 The output below is generated by `ping6 2a02:168:91d5:1:b6fb:e4ff:fe8a:fade`. This is a host in my home network. ```bash $ sudo tcpdump -vv -i enp1s0 -n -e "(icmp6 && (ip6[40] >= 133 && ip6[40] <= 137))" 17:59:09.195679 00:0d:b9:55:66:08 > 33:33:ff:8a:fa:de, ethertype IPv6 (0x86dd), length 86: (hlim 255, next-header ICMPv6 (58) payload length: 32) 2a02:168:91d5:1:20d:b9ff:fe55:6608 > ff02::1:ff8a:fade: [icmp6 sum ok] ICMP6, neighbor solicitation, length 32, who has 2a02:168:91d5:1:b6fb:e4ff:fe8a:fade source link-address option (1), length 8 (1): 00:0d:b9:55:66:08 0x0000: 000d b955 6608 17:59:09.195925 b4:fb:e4:8a:fa:de > 00:0d:b9:55:66:08, ethertype IPv6 (0x86dd), length 86: (hlim 255, next-header ICMPv6 (58) payload length: 32) 2a02:168:91d5:1:b6fb:e4ff:fe8a:fade > 2a02:168:91d5:1:20d:b9ff:fe55:6608: [icmp6 sum ok] ICMP6, neighbor advertisement, length 32, tgt is 2a02:168:91d5:1:b6fb:e4ff:fe8a:fade, Flags [router, solicited, override] destination link-address option (2), length 8 (1): b4:fb:e4:8a:fa:de 0x0000: b4fb e48a fade ``` The first message (Neighbor Solicitation) asks the link-address of the interface having IPv6 address `2a02:168:91d5:1:b6fb:e4ff:fe8a:fade` (sending its link layer address in option 1), and a host replies with its link layer address `b4:fb:e4:8a:fa:de` in option 2. 第一条消息(Neighbor Solicitation)询问具有 IPv6 地址的接口的链路地址 2a02:168:91d5:1:b6fb:e4ff:fe8a:fade(在选项 1 中发送其链路层地址),主机回复其选项 2 中的链路层地址 b4:fb:e4:8a:fa:de。 As in ARP, neighbors are cached in IPv6 as well. You can see the contents of this cache and add/delete entries or flush all the cache: ```bash $ ip -6 neigh show dev enp1s0 fe80::b6fb:e4ff:fe8a:fade lladdr b4:fb:e4:8a:fa:de router STALE 2a02:168:91d5:1:b6fb:e4ff:fe8a:fade lladdr b4:fb:e4:8a:fa:de router STALE $ sudo ip -6 neigh flush dev enp1s0 ``` ##### Address configuration: from DHCPv4 to DHCPv6, RA, PD and SLAAC If you do not configure statically (manually), DHCP (DHCPv4) is the only and probably the most popular way to dynamically configure IPv4 addresses. An IPv6 address can also be configured manually or by using DHCPv6, when the exact address is important for some reason (e.g. you may want to have a DNS record for it). In addition to these methods, it is possible to configure IPv6 addresses automatically and in a stateless fashion. This is probably much more common because we usually do not care about the exact addresses of the hosts (think about your laptop, tv, mobile phone at home). This mechanism is called StateLess Address AutoConfiguration (SLAAC). It is stateless because nothing keeps track of IP addresses (like a stateful DHCP server assigning IP addresses), but they are generated by the hosts theirselves. SLAAC works together with Prefix Delegation (PD), and PD is possible both with Router Advertisement (RA) and DHCPv6. If DHCPv6 is used only for PD, and not for assigning complete IPv6 addresses, then it is called stateless DHCPv6 or DHCPv6-PD. A summary might be helpful, here are the options: - static: You can configure the address manually. - stateful DHCPv6: DHCPv6 can configure (assign) the address and provide other configurations (DNS etc.). - stateless DHCPv6: DHCPv6 does not configure the address, only provides PD and other configurations. Hosts use SLAAC to autoconfigure IPv6 addresses. - RA only: There is no DHCPv6. RA provides prefix and hosts use SLAAC to autoconfigure IPv6 addresses. Some of the other configurations can also be distributed by RA such as DNS. So basically when you want maximum control on address configuration, you do static or stateful DHCPv6, which enables you to know the exact address, but if you do not want or do not need that much control and prefer an easy configuration, you do RA only or stateless DHCPv6, or a combination of them if needed. ... ### Misc - [What the heck is the event loop anyway? | Philip Roberts | JSConf EU](https://www.youtube.com/watch?v=8aGhZQkoFbQ) - Evet Loop: Wait call stack to be clear. - [CNCF Cloud Native Interactive Landscape](https://landscape.cncf.io/) - cloud真是go的天下 - [中国製をバカにした大きな代償。米国をあっさり抜いてAI・5G・半導体ほか最先端6分野で中国が世界首位へ=高島康司](https://www.mag2.com/p/money/1138508/2) - タイム誌の特集「ビヨンド2000」は、当時の常識を反映して、次のように自信たっぷりに断言した。「21世紀、中国は巨大な工業国になることはできない。一人当たりの所得がガイアナやフィリピンと同程度の中国では、先端技術製品はおろか、それを購入するお金もない。開発するための資源が必要だ」 - だが、この認識は2010年ころから次第に変化してきたという。「しかし、2010年になると、この図式は変わり始めた。中国は多国籍企業の低コスト製造拠点として成長し、大衆向け製品の世界的な製造工場になろうとしていたのだ」 - [CSS Open Props](https://css-tricks.com/open-props-and-custom-properties-as-a-system/?ref=sidebar) - ```html <h1 class="color-primary size-large">Header<h1> ``` …is a similar value proposition as this: ```css html { --color-primary: green; --size-large: 3rem; /* ... and a whole set of tokens */ } h1 { color: var(--color-primary); font-size: var(--size-large); } ``` - 图灵完备 | [Zhihu](https://www.zhihu.com/question/20115374) | [r u even turing complete?](https://www.youtube.com/watch?v=UwrZkg6JOOU) - 在[可计算性理论](https://link.zhihu.com/?target=https%3A//zh.wikipedia.org/wiki/%E5%8F%AF%E8%AE%A1%E7%AE%97%E6%80%A7%E7%90%86%E8%AE%BA),如果一系列操作数据的规则(如[指令集](https://link.zhihu.com/?target=https%3A//zh.wikipedia.org/wiki/%E6%8C%87%E4%BB%A4%E9%9B%86)、[编程语言](https://link.zhihu.com/?target=https%3A//zh.wikipedia.org/wiki/%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8%80)、[细胞自动机](https://link.zhihu.com/?target=https%3A//zh.wikipedia.org/wiki/%E7%B4%B0%E8%83%9E%E8%87%AA%E5%8B%95%E6%A9%9F))可以用来模拟任何[图灵机](https://link.zhihu.com/?target=https%3A//zh.wikipedia.org/wiki/%E5%9B%BE%E7%81%B5%E6%9C%BA),那么它是**图灵完备**的。 - 图灵不完备的语言常见原因有循环或递归受限(无法写不终止的程序,如 while(true){}; ), 无法实现类似数组或列表这样的数据结构(不能模拟纸带). 这会使能写的程序有限