> 2022年01月06日信息消化 ### What Is a File System? Types of Computer File Systems and How they Work > MEMO > 分区:基于BIOS的MBR分区与UEFI的GPT分区,格式:win:FAT32, NTFS, and exFAT | Apple:HFS+, APFS, exFAT | Linux: ext1.., ext4 > 最通用:exFAT Origin: [What Is a File System? Types of Computer File Systems and How they Work – Explained with Examples](https://www.freecodecamp.org/news/file-systems-architecture-explained/) A **file system** defines how files are **named**, **stored**, and **retrieved** from a storage device. #### Everything begins with partitioning For example, a basic Linux installation has three partitions: one partition dedicated to the operating system, one for the users' files, and an optional swap partition. A swap partition works as the RAM extension when RAM runs out of space. File systems on Windows and Mac have a similar layout, but they don't use a dedicated swap partition; Instead, they manage to swap within the partition on which you've installed your operating system. On a computer with multiple partitions, you can install several operating systems, and every time choose a different operating system to boot up your system with. For instance, to boot up a MacBook in recovery mode, you need to hold `Command + R` as soon as you restart (or turn on) your MacBook. By doing so, you instruct the system's firmware to boot up with a partition that contains the recovery program. Some operating systems, like Windows, assign a drive letter (A, B, C, or D) to the partitions. For instance, the *primary partition* on Windows (on which Windows is installed) is known as **C**:, or **drive C**. In Unix-like operating systems, however, partitions appear as ordinary directories under the root directory. #### Partitioning schemes, system firmware, and booting When partitioning a storage device, we have two partitioning methods (or schemes ????) to choose from: - **Master boot record (MBR) Scheme** - **GUID Partition Table (GPT) Scheme** A firmware is a low-level software embedded into electronic devices to operate the device, or bootstrap another program to do it. Firmware exists in computers, peripherals (keyboards, mice, and printers), or even electronic home appliances. However, on simpler systems like a printer, the firmware is the operating system. The menu you use on your printer is the interface of its firmware. Hardware manufacturers make firmware based on two specifications: - **Basic Input/Output (BIOS)** - **Unified Extensible Firmware Interface (UEFI)** Firmwares - BIOS-based or UEFI-based - reside on a *non-volatile memory*, like a flash ROM attached to the motherboard. 固件——基于 BIOS 或基于 UEFI——驻留在非易失性存储器上,例如连接到主板的闪存 ROM。 A firmware also runs pre-OS environments (with network support), like recovery or diagnostic tools, or even a shell to run text-based commands. The first few screens you see before your Windows logo appears are the output of your computer's firmware, verifying the health of hardware components and the memory. The initial check is confirmed with a beep (usually on PCs), indicating everything is good to go. #### MBR partitioning and BIOS-based firmware MBR partitioning scheme is a part of the BIOS specifications and is used by BIOS-based firmware. On MBR-partitioned disks, the first sector on the storage device contains essential data to boot up the system. This sector is called MBR. MBR contains the following information: - The boot loader, which is a **simple program** (in machine code) to initiate the first stage of the booting process - A **partition table**, which contains information about your partitions. #### GPT partitioning and UEFI-based firmware The **GPT** partitioning scheme is more sophisticated than MBR and doesn't have the limitations of MBR. For instance, you can have as many partitions as your operating system allows. And every partition can be the size of the biggest storage device available in the market - actually a lot more. GPT is gradually replacing MBR, although MBR is still widely supported across old PCs and new ones. As mentioned earlier, GPT is a part of the UEFI specification, which is replacing the good old BIOS. That means that UEFI-based firmware uses a GPT-partitioned storage device to handle the booting process. Many hardware and operating systems now support UEFI and use the GPT scheme to partition storage devices. #### Formatting partitions When partitioning is done, the partitions should be **formatted**. Most operating systems allow you to format a partition based on a set of file systems. For instance, if you are formatting a partition on Windows, you can choose between **FAT32**, **NTFS**, and **exFAT** file systems. Formatting involves the creation of various **data structures** and metadata used to manage files within a partition. Let's take the NTFS file system as an example. When you format a partition to NTFS, the formatting process places the key NTFS data structures and the **Master file table (MFT)** on the partition. #### How it started, how it's going In the early days, Microsoft used **FAT** (FAT12, FAT16, and FAT32) in the **MS-DOS** and **Windows 9x** family. Starting from Windows **NT 3.1**, Microsoft developed **New Technology File System (NTFS)**, which had many advantages over FAT32, such as supporting bigger files, allowing longer filenames, data encryption, access management, journaling, and a lot more. For instance, you can **only read** the content of an NTFS-formatted storage device (like flash memory) on a Mac OS, but you won’t be able to write anything to it - unless you [install an NTFS driver with write support](https://www.howtogeek.com/236055/how-to-write-to-ntfs-drives-on-a-mac/). Or you can just use the **exFat** file system. **Extended File Allocation Table (exFAT)** is a lighter version of NTFS created by Microsoft in 2006. exFAT was designed for high-capacity removable devices, such as external hard disks, USB drives, and memory cards. exFAT is the default file system used by **SDXC** **cards**. Unlike NTFS, exFAT has **read and write** support on Non-Windows environments as well, including Mac OS — making it the best cross-platform file system for high-capacity removable storage devices. Apple has also developed and used various file systems over the years, including **Hierarchical File System (HFS)**, **HFS+**, and recently **Apple File System (APFS)**. **The Extended File System (ext)** family of file systems was created for the Linux kernel - the core of the Linux operating system. The first version of **ext** was released in 1991, but soon after, it was replaced by the **second extended file system** (**ext2)** in 1993. In the 2000s, the **third extended filesystem** (**ext3)** and **fourth extended filesystem (ext4)** were developed for Linux with journaling capability. **ext4** is now the default file system in many distributions of Linux, including [Debian](https://en.wikipedia.org/wiki/Debian) and [Ubuntu](https://en.wikipedia.org/wiki/Ubuntu). You can use the `findmnt` command on Linux to list your ext4-formatted partitions: ``` findmnt -lo source,target,fstype,used -t ext4 ``` The output would be something like: ``` SOURCE TARGET FSTYPE USED /dev/vda1 / ext4 3.6G ``` #### Architecture of file systems A file system installed on an operating system consists of three layers: - **Physical file system** - **Virtual file system** **VFS** - **Logical file system** A VFS defines a *contract* that all physical file systems must implement to be supported by that operating system. However, this compliance isn't built into the file system core, meaning the source code of a file system doesn't include support for every operating system's VFS. Instead, it uses a **file system driver** to adhere to the VFS rules of every file system. A driver is a program that enables software to communicate with another software or hardware. VFS 定义了一个合约,所有物理文件系统都必须实现该合约才能得到该操作系统的支持。 但是,这种合规性并未内置到文件系统核心中,这意味着文件系统的源代码不包括对每个操作系统的 VFS 的支持。 相反,它使用文件系统驱动程序来遵守每个文件系统的 VFS 规则。驱动程序是使软件能够与其他软件或硬件进行通信的程序 The logical file system is the user-facing part of a file system, which provides an API to enable user programs to perform various file operations, such as `OPEN`, `READ`, and `WRITE`, without having to deal with any storage hardware. 逻辑文件系统是文件系统中面向用户的部分,它提供 API 使用户程序能够执行各种文件操作,例如 OPEN、READ 和 WRITE,而无需处理任何存储硬件。 #### What does it mean to mount a file system? On Unix-like systems, the VFS assigns a **device ID** (for instance, `dev/disk1s1`) to each partition or removable storage device. Then, it creates a **virtual directory tree** and puts the content of each device under that directory tree as separate directories. The act of assigning a directory to a storage device (under the root directory tree) is called **mounting**, and the assigned directory is called a **mount point**. That said, on a Unix-like operating system, all partitions and removable storage devices appear as if they are directories under the root directory. For instance, on Linux, the mounting points for a removable device (such as a memory card), are usually under the `/media` directory. That said, once a flash memory is attached to the system, and consequently, *auto mounted* at the default mounting point (`/media` in this case), its content would be available under the `/media` directory. On Linux, it’s done like so: ``` mount /dev/disk1s1 /media/usb ``` In the above command, the first parameter is the device ID (`/dev/disk1s1`), and the second parameter (`/media/usb`) is the mount point. Please note that the mount point should already exist as a directory. If the mount-point directory already contains files, those files will be hidden for as long as the device is mounted. #### Files metadata File metadata is a data structure that contains **data about a file**, such as: - File size - Timestamps, like creation date, last accessed date, and modification date - The file's owner - The file's mode (who can do what with the file) - What blocks on the partition are allocated to the file - and a lot more Metadata isn’t stored with the file content, though. Instead, it’s stored in a different place on the disk - but associated with the file. In Unix-like systems, the metadata is in the form of data structures, called **inode**. Inodes are identified by a unique number called the *inode number.* Inodes are associated with files in a table called *inode tables*. Each file on the storage device has an inode, which contains information about it such as the time it was created, modified, etc. The inode also includes the address of the blocks allocated to the file; On the other hand, where exactly it's located on the storage device In an ext4 inode, the address of the allocated blocks is stored as a set of data structures called **extents** (within the inode). Each extent contains the address of the *first data block* allocated to the file and the number of the *continuous blocks* that the file has occupied. Whenever you open a file on Linux, its name is first resolved to an inode number. Once the inode is fetched, the file system starts to compose the file from the data blocks registered in the inode. You can use the `df` command with the `-i` parameter on Linux to see the inodes (total, used, and free) in your partitions: ``` df -i ``` The output would look like this: ``` udev 4116100 378 4115722 1% /dev tmpfs 4118422 528 4117894 1% /run /dev/vda1 6451200 175101 6276099 3% / ``` As you can see, the partition `/dev/vda1` has a total number of 6,451,200 inodes, of which 3% have been used (175,101 inodes). It's unlikely that a personal Linux OS would run out of inodes. However, enterprise services that deal with a large number of files (like mail servers) have to manage their inode quota smartly. On NTFS, the metadata is stored differently, though. NTFS keeps file information in a data structure called the [**Master File Table (MFT)**](https://docs.microsoft.com/en-us/windows/win32/fileio/master-file-table). Every file has at least one entry in MFT, which contains everything about it, including its location on the storage device - similar to the inodes table. #### Space Management Storage devices are divided into fixed-sized blocks called **sectors**. A sector is the **minimum storage unit** on a storage device and is between 512 bytes and 4096 bytes (Advanced Format). However, file systems use a high-level concept as the storage unit, called **blocks.** Blocks are an abstraction over physical sectors; Each block usually consists of multiple sectors. Depending on the file size, the file system allocates one or more blocks to each file. Speaking of space management, the file system is aware of every *used* and *unused* block on the partitions, so it’ll be able to allocate space to new files or fetch the existing ones when requested. The most basic storage unit in ext4-formatted partitions is the block. However, the contiguous blocks are grouped into **block groups** for easier management.  Each block group has its own data structures and data blocks. Here are the data structures a block group can contain: - **Super Block:** a metadata repository, which contains metadata about the entire file system, such as the total number of blocks in the file system, total blocks in block groups, inodes, and more. Not all block groups contain the superblock, though. A certain number of block groups store a copy of the super as a backup. - **Group Descriptors:** Group descriptors also contain bookkeeping information for each block group - **Inode Bitmap:** Each block group has its own inode quota for storing files. A block bitmap is a data structure used to identify *used* and *unused* inodes within the block group. `1` denotes used and `0` denotes unused inode objects. - **Block Bitmap:** a data structure used to identify used & unused data blocks within the block group. `1` denotes used and `0` denotes unused data blocks - **Inode Table:** a data structure that defines the relation of files and their inodes. The number of inodes stored in this area is related to the block size used by the file system. - **Data Blocks:** This is the zone within the block group where file contents are stored. Ext4 file system even takes one step further (comparing to ext3), and organizes block groups into a bigger group called *flex block groups*. When a file is being written to a disk, it is written to one or more blocks within a block group. Managing files at the block group level improves the performance of the file system significantly, as opposed to organizing files as one unit. #### What is disk fragmentation? Over time, new files are written to the disk, existing files get bigger, shrunk, or deleted. These frequent changes in the storage medium leave many small gaps (empty spaces) between files. These gaps are due to the same reason file size and file size on disk are different. Some files won't fill up the full block, and lots of space will be wasted. And over time there' won't be enough consequent blocks to store new files. **File Fragmentation** occurs when a file is stored as fragments on the storage device because the file system cannot find enough contiguous blocks to store the whole file in a row. 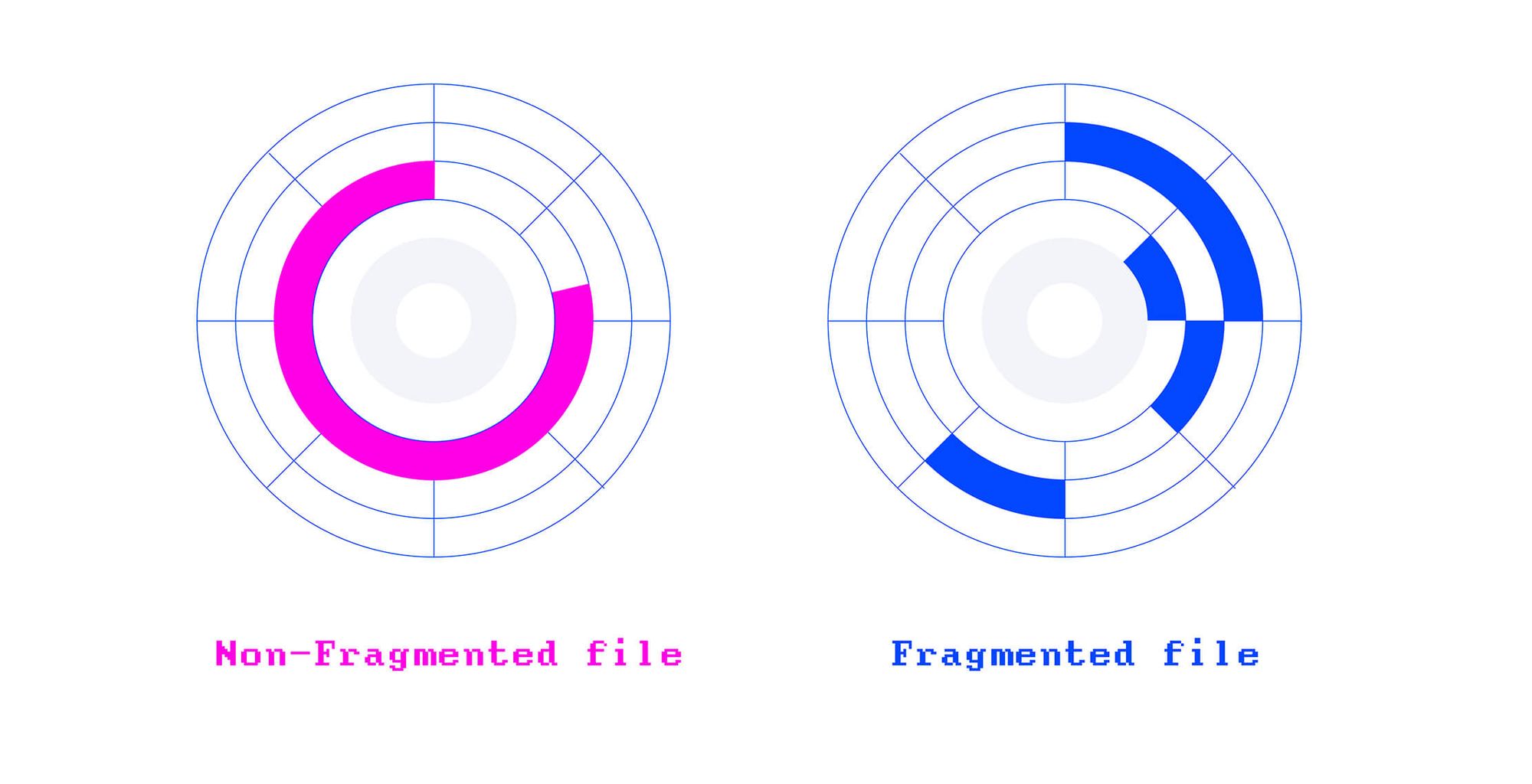 Let's make it more clear with an example. Imagine you have a Word document named `myfile.docx`. `myfile.docx` is initially stored in a few contiguous blocks on the disk; Let's say this is how the blocks are named: `LBA250`, `LBA251`, and `LBA252`. Now, if you add more content to `myfile.docx` and save it, it will need to occupy more blocks on the storage medium. Since `myfile.docx` is currently stored on `LBA250`, `LBA251`, and `LBA252`, the new content should preferably sit within `LBA253` and so forth - depending on how many more blocks are needed to accommodate the new changes. Now, imagine `LBA253` is already taken by another file (maybe it’s the first block of another file). In that case, the new content of `myfile.docx` has to be stored on different blocks somewhere else on the disks, for instance, `LBA312` and `LBA313`. `myfile.docx` got fragmented ????. File fragmentation puts a burden on the file system because every time a fragmented file is requested by a user program, the file system needs to collect every piece of the file from various locations on a disk. This overhead applies to saving the file back to the disk as well. Fragmentation is one of the reasons some operating systems get slow as the file system ages. #### Should We Care About Fragmentation these days? The short answer is: not anymore! Modern file systems use smart algorithms to avoid (or early-detect) fragmentation as much as possible. Ext4 also does some sort of **preallocation,** which involves reserving blocks for a file before they are actually needed - making sure the file won't get fragmented if it gets bigger over time. #### Directories A Directory (Folder in Windows) is a special file used as a **logical container** to group files and directories within a file system. On NTFS and Ext4, directories and files are treated the same way. That said, directories are just files that have their own inode (on Ext4) or MFT entry (on NTFS). The inode or MFT entry of a directory contains information about that directory, as well as a collection of entries pointing to the files "under" that directory. The files aren't literally contained within the directory, but they are associated with the directory in a way that they appear as directory's children at a higher level, such as in a file explorer program. These entries are called **directory entries.** Directory entries contain file names mapped to their inode/MFT entry. In addition to the directory entries, there are two more entries. The `.` entry, which points to the directory itself, and `..`, which points to the parent directory of this directory. #### Rules for naming files Some file systems enforce limitations on filenames. The limitation can be in the **length of the filename** or **filename case sensitivity**. For instance, in NTFS (Windows) and APFS (Mac) file systems, `MyFile` and `myfile` refer to the same file, while on ext4 (Linux), they point to different files. #### Rules for file size An old file system like **FAT32** (used by MS-DOS +7.1, Windows 9x family, and flash memories) can’t store files more than 4 GB, while its successor, **NTFS** allows file sizes to be up to **16 EB** (1000 TB). Like NTFS, exFAT allows a file size of 16 EB too. This makes exFAT an ideal option for storing massive data objects, such as video files. Practically, there’s no limitation on the file size in the exFAT and NTFS file systems. Linux’s ext4 and Apple’s APFS support files up to **16 TiB** and **8 EiB** respectively. ### Cognitive Load Theory and its App ### lications for Learning > MEMO > Alleviate cognitive load > 减轻学习高难度主题的认知负担:投资更多的基础技能练习。 > Practice should start with access to examples so students can emulate the pattern. > 新手从实际示例开始学习,专家从直接解决问题入手。 origin: [Cognitive Load Theory and its Applications for Learning](https://www.scotthyoung.com/blog/2022/01/04/cognitive-load-theory/) Why is learning effortful? Why do we struggle to learn calculus but easily learn our mother tongue? How can we make hard skills easier to learn? [Cognitive load theory](https://en.wikipedia.org/wiki/Cognitive_load_theory) is a powerful framework from psychology for making sense of these questions. Cognitive load theory, developed in the 1980s by psychologist [John Sweller](https://en.wikipedia.org/wiki/John_Sweller), has become a dominant paradigm for the design of teaching materials. In this essay, I explain the theory, some of its key predictions, and potential applications for your learning. #### Why is Most Learning Hard? The central concept in cognitive load theory is that **we have limited mental bandwidth** for dealing with **new information**, but no such limitations when dealing with previously mastered material. This phenomenon explains why we can struggle with challenging classes. Suppose we are missing foundational patterns in long-term memory. In that case, instruction may require us to juggle too many new pieces of information simultaneously. These will slip out of working memory, and we’ll fail to learn. #### Three Types of Cognitive Load 1. **Intrinsic load.** The combined attention that’s necessary to learn the pattern that will be put into long-term memory. 2. **Extraneous load.** Unnecessary load distracts from learning the pattern. Obvious distractions that eat up working memory, such as television in the background, make learning harder. But extraneous load also includes mental work needed to learn a subject that isn’t necessary. Poorly organized study materials can increase cognitive load. Examples of this include having to flip between pages to understand a diagram, or making students figure out a pattern that could be taught explicitly. 3. **Germane load.** Efforts that improve learning outcomes but are not strictly necessary to learn the pattern. Some forms of germane load include self-explanations and retrieval practice, both of which are effortful but increase the ability to recall a pattern later.[3](https://www.scotthyoung.com/blog/2022/01/04/cognitive-load-theory/#easy-footnote-bottom-3-13804)[4](https://www.scotthyoung.com/blog/2022/01/04/cognitive-load-theory/#easy-footnote-bottom-4-13804) Consider variable practice, the idea of practicing a skill with an increased range of problems and in different contexts. It’s harder than practice which occurs in only a narrow range of problems. Yet, there’s evidence that variable practice leads to better learning and transfer.[5](https://www.scotthyoung.com/blog/2022/01/04/cognitive-load-theory/#easy-footnote-bottom-5-13804) However, the learning benefit of variable practice *only* occurs when cognitive load isn’t overwhelmed. If it is, then simpler forms of practice become preferable.[6](https://www.scotthyoung.com/blog/2022/01/04/cognitive-load-theory/#easy-footnote-bottom-6-13804) 1. #### The Worked-Example Effect Traditionally, math education has focused on having students solve problems to get good at math. Sweller and Cooper pushed back against this idea, showing that studying **worked examples** (problems, along with detailed solutions) is often more efficient.[7](https://www.scotthyoung.com/blog/2022/01/04/cognitive-load-theory/#easy-footnote-bottom-7-13804) Sweller and Cooper, of course, agree that practice is helpful. But they argue in favor of presenting lots of examples first. In their model, **practice should start with access to examples so students can emulate the pattern.** Finally, practice without the solutions available becomes helpful when the material is learned well enough that retrieval efforts are germane load rather than just too much. 2. #### The Goal-Free Effect One reason problem solving is difficult is that it requires you to keep in mind the goal you’re trying to reach, how far you are from the goal, and potential operations to move forward. This creates a lot of cognitive load that makes it harder to identify the solution procedure. Removing an explicit goal can also reduce cognitive load. For example, a classic trigonometry problem might ask a student to find a particular angle. A “goal-free” way to present this would be to ask students to find as many angles as possible. 3. #### The Split-Attention Effect Consider these two flashcards for learning Chinese characters. The first creates extra cognitive load since the pairing between sound and character requires more spatial manipulation. **Learning is enhanced when instructional materials are organized** so that information doesn’t require any manipulation to be understood. 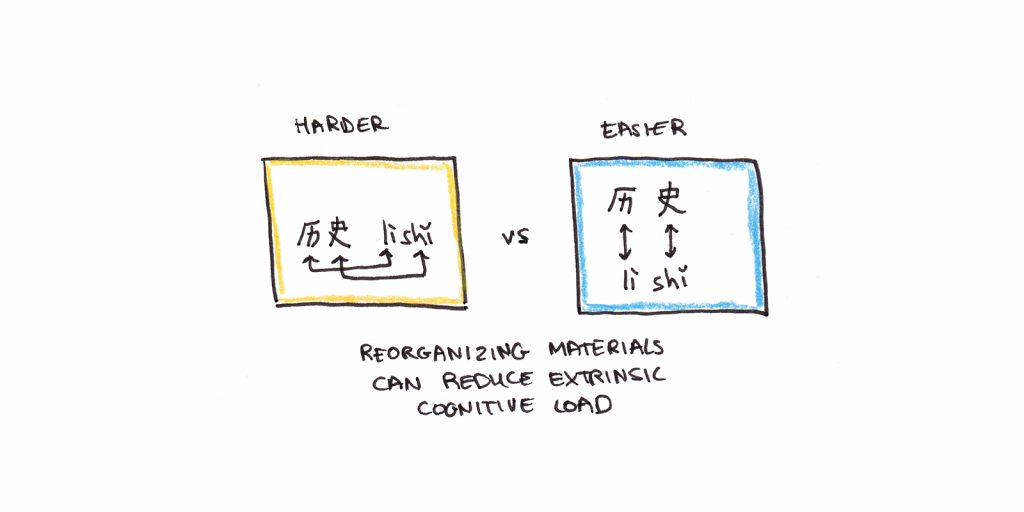 4. #### The Expertise-Reversal Effect Cognitive load theory predicts that for novices exposed to information for the first time, worked examples are better than problem solving. But, interestingly, this effect reverses as you gain more experience.[10](https://www.scotthyoung.com/blog/2022/01/04/cognitive-load-theory/#easy-footnote-bottom-10-13804) One explanation for this is in terms of redundancy. If the solution pattern is already stored in your long-term memory, making sense of a worked example doesn’t help much. In this case, it is better to retrieve the answer directly from memory without distracting yourself with the example. Another explanation is that if the problems are reasonably easy to solve, worked examples may not provoke deep enough processing. Solving a problem yourself is a kind of germane load akin to retrieval practice. #### Build your prerequisite knowledge and procedural fluency. Cognitive load theory is most important in domains where there is great element interactivity. This means that many different pieces of information all need to be in place before you can understand the problem. In contrast, a subject might have extensive difficulty. In this case, there may be a large body of information to learn, but you rarely need all of it at once. **Math and science tend to have high element interactivity, which is why mastery of them is seen as a sign of intelligence.** Working memory is associated with intelligence, and those with slightly more working memory can handle slightly greater element interactivity. While this creates only a modest advantage in the short term, greater ease in learning basic concepts can accumulate into [a considerable advantage in the long run](https://www.scotthyoung.com/blog/2019/05/13/do-you-need-to-be-smart-to-learn-certain-subjects/). **If you’re struggling in a subject with high element interactivity, the key is to go back and invest in more practice in the underlying skills.** Doing this will make you more fluent in the component knowledge, which frees up more working memory for handling the new topics. ### Misc - [Trends that shaped the Modern Data Stack in 2021](https://www.siffletdata.com/blog/trends-that-shaped-the-modern-data-stack-in-2021) > In DevOps, the notion of Observability is centered around three main pillars: **traces**, **logs**, and **metrics** that represent the [Golden Triangle](https://devops.com/metrics-logs-and-traces-the-golden-triangle-of-observability-in-monitoring/) of any infrastructure and application monitoring framework. Solutions like Datadog, NewRelic, Splunk, and others have paved the way for what has become standard practice in software development; it only makes sense that some of their best practices would translate into Data Engineering, a subset of Software Engineering. - [Binary Explained in 01100100 Seconds](https://www.youtube.com/watch?v=zDNaUi2cjv4) > Going from transistors and building all the logic gates, then registers and arithmetic–logic units to end up with a CPU was the most fun course I had in school :D - Twitter | [这个神经网络教程的演示绝了](https://twitter.com/laixintao/status/1479061840215052294) - [The Dark Side of Open Source // What really happened to Faker.js?](https://www.youtube.com/watch?v=d15DP5zqnYE) - Yesterday, one of my favorite open-source packages, Faker.js, was abruptly taken down from GitHub. Its readme simply said “**What really happened to Aaron Swartz?**”. Let’s take a look at why Open Source Software can be a bad deal for many independent developers. -