> 2021年04月26日信息消化 ### 每天学点机器学习 #### Week3 Overfitting 过拟合 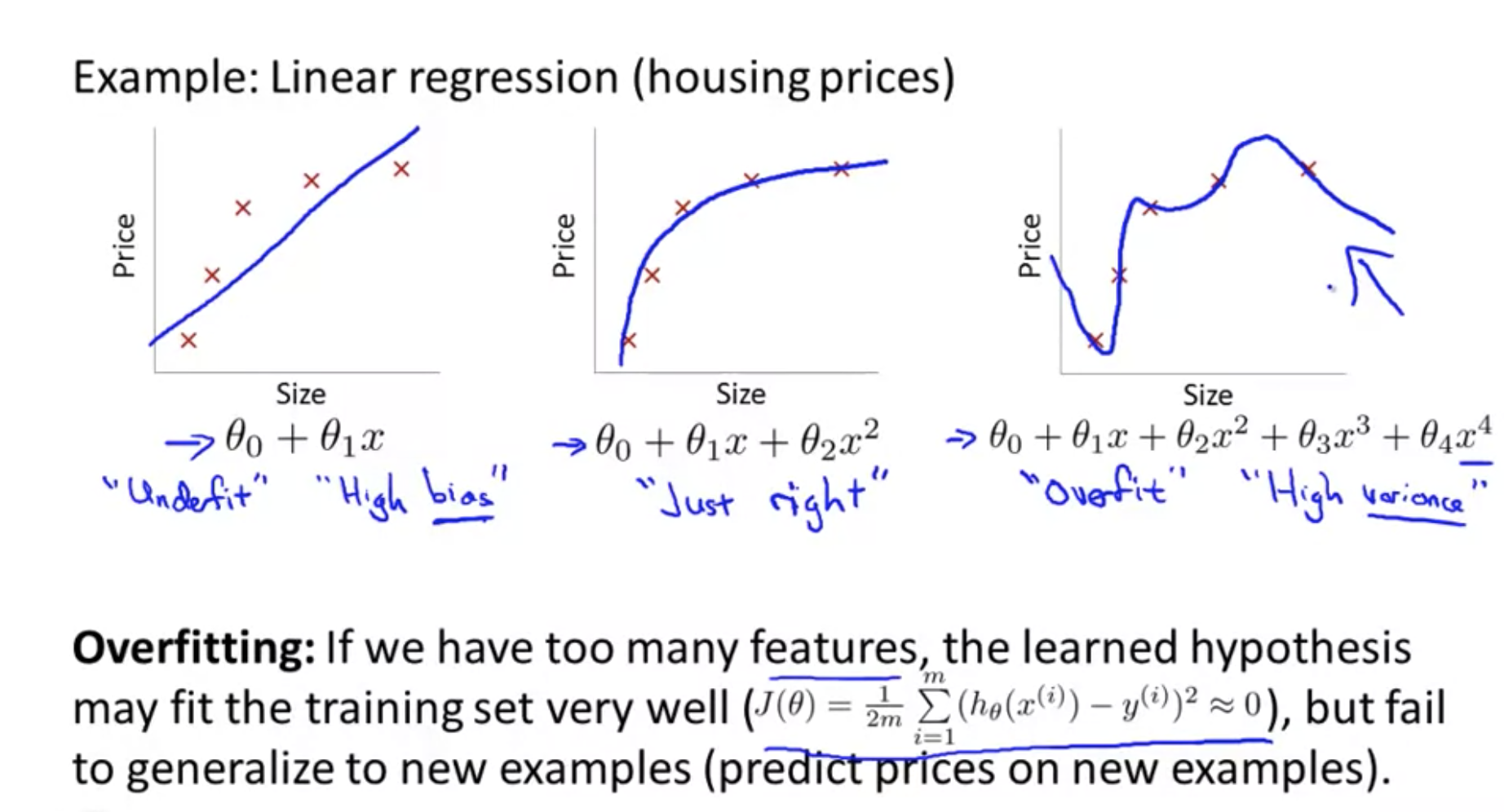 但是,如果我们有很多特征,而且,训练数据很少,那么,过度拟合就会成为一个问题。为了解决过度拟合的问题,有两个主要的选择。 But, if we have a lot of features, and, very little training data, then, over fitting can become a problem. In order to address over fitting, there are two main options for things that we can do. Options: 1. Reduce number of features - Manulaly select which features to keep. - Model selection algorithm. 2. Regularization. - Keep all the features, but reduce magnitude/values of parameters $\theta_j$. - Works well when we have a lot of features, each of which contributes a bit to predicting y. ##### Regularizartion | Cost Function ###### 随堂小测  修改成本函数:加入θ3和θ4的成本,因为目的迭代取最小值所以最终会减少$θ_3$和$θ_4$结果值。 > We've added two extra terms at the end to inflate the cost of $\theta_3$ and $\theta_4$. Now, in order for the cost function to get close to zero, we will have to reduce the values of $\theta_3$ and $\theta_4 $to near zero. 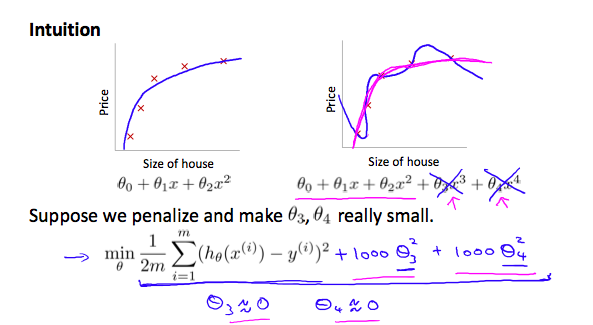 ##### Regularized linear regresion 我们也可以在一次求和中对所有的θ参数进行正则化,如:。 > We could also regularize all of our theta parameters in a single summation as: $$ min_θ\frac{1}{2m}\sum_{i=1}^{m}(h_θ(x^{(i)}-y^{(i)})^2 +λ\sum_{j=1}^nθ_j^2 $$ λ,即lambda,是正则化参数。它决定了我们的theta参数的成本被夸大了多少。 > The λ, or lambda, is the **regularization parameter**. It determines how much the costs of our theta parameters are inflated. ###### 随堂小测 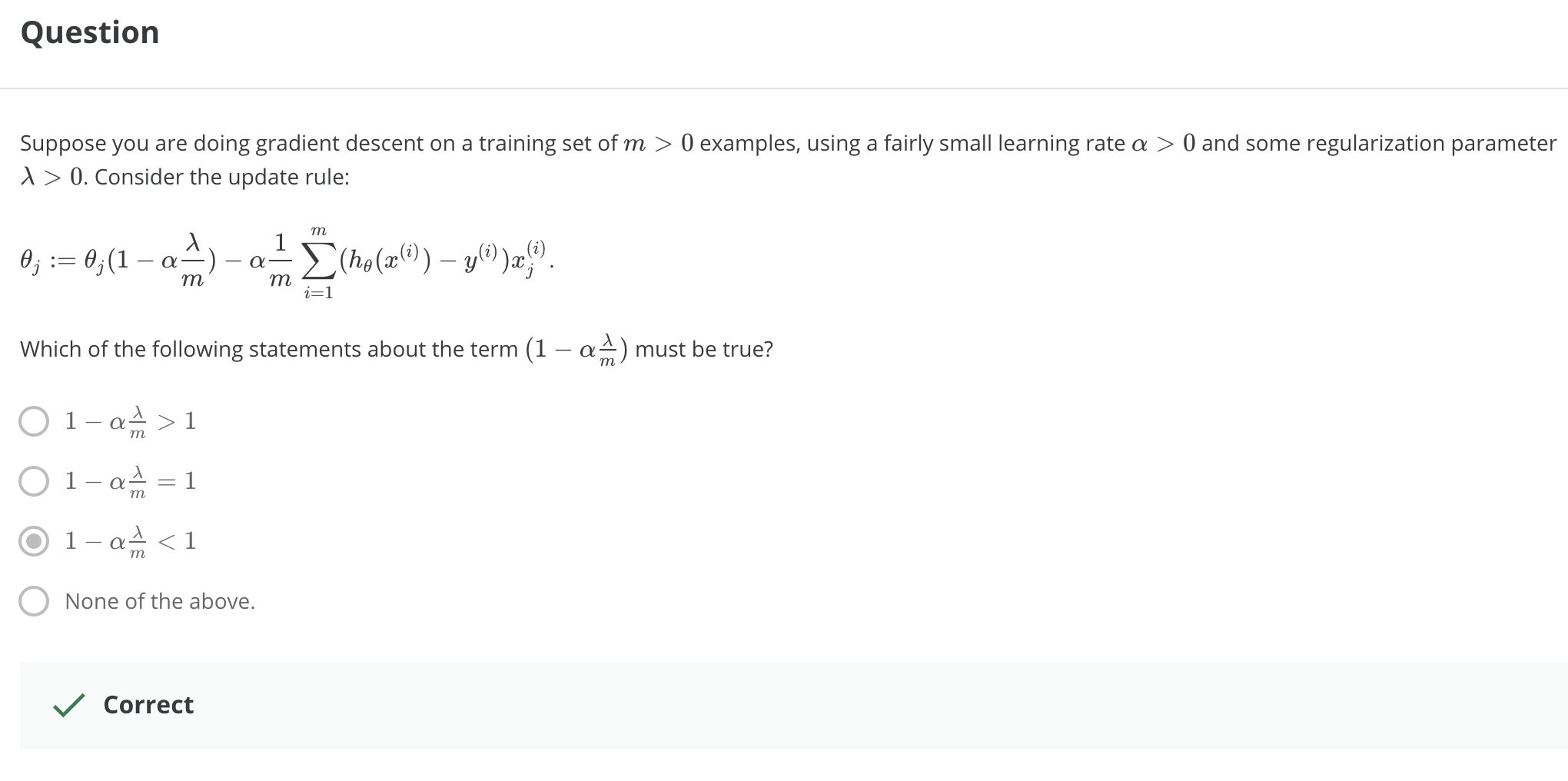 ###### Gradient Descent 我们将修改我们的梯度下降函数以分离出 $θ_0 $. We will modify our gradient descent function to separate out$θ_0 $ from the rest of the parameters because we do not want to penalize $θ_0 $.  ###### Normal Equation 现在让我们用非迭代正则方程的另一种方法来处理正则化。 为了加入正则化,该方程与我们原来的方程相同,只是我们在括号内增加了一个项: > Now let's approach regularization using the alternate method of the non-iterative normal equation. > > To add in regularization, the equation is the same as our original, except that we add another term inside the parentheses  L是一个矩阵,左上方是0,对角线上是1,其他地方都是0。它的尺寸应该是(n+1)×(n+1)。直观地说,这是一个身份矩阵,与单个实数λ相乘。 回顾一下,如果m<n,那么$X^TX$是不可逆的。然而,当我们添加term λ⋅L时,那么$X^TX + λ⋅L$成为可逆的。 > L is a matrix with 0 at the top left and 1's down the diagonal, with 0's everywhere else. It should have dimension (n+1)×(n+1). Intuitively, this is the identity matrix, multiplied with a single real number λ. > > Recall that if m < n, then $X^TX$ is non-invertible. However, when we add the term λ⋅L, then $X^TX + λ⋅L$ becomes invertible. ##### Regularized logistic regression 我们可以用类似于线性回归的方式对逻辑回归进行正则化。因此,我们可以避免过度拟合。下图显示了粉红线所显示的正则化函数如何比蓝线所代表的非正则化函数更不可能过度拟合。 > We can regularize logistic regression in a similar way that we regularize linear regression. As a result, we can avoid overfitting. The following image shows how the regularized function, displayed by the pink line, is less likely to overfit than the non-regularized function represented by the blue line: 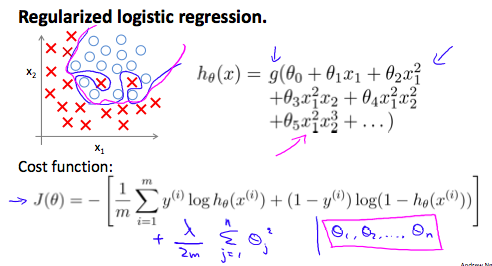 我们可以通过在末尾添加一个项来规范这个方程: > We can regularize this equation by adding a term to the end: $$ J(\theta) = -\frac{1}{m}\sum_{i=1}^{m}[y^{(i)}log(h_{\theta}(x^{(i)}))+(1-y^{(i)})log(1-h_\theta(x^{(i)}))] + \frac{λ}{2m}\sum_{j=1}^n\theta_j^2 $$ 第二个和$ \sum_{j=1}^n \theta_j^2$ 意味着明确地排除偏置项,$θ_0$ 也就是说,θ向量的索引从0到n(持有n+1个值, $\theta_0$到 $θ_n$ ),而这个和明确地跳过了$θ_0$ 。因此,在计算该方程时,我们应该连续更新以下两个方程。 The second sum, $ \sum_{j=1}^n \theta_j^2$ means to **explicitly exclude** the bias term, $\theta_0$ . I.e. the θ vector is indexed from 0 to n (holding n+1 values, $\theta_0$ through $\theta_n$ ), and this sum explicitly skips $\theta_0$ , by running from 1 to n, skipping 0. Thus, when computing the equation, we should continuously update the two following equations:  ###### 随堂小测  ### 其他值得阅读 #### 大脑可塑性和我们做梦的原因 原文:[Brain Plasticity and The Reason Why We Dream](https://medium.com/illumination/brain-plasticity-and-the-reason-why-we-dream-91e111e267ab) 雷-查尔斯、罗尼-米尔萨普、安德烈-波切利、史蒂夫-旺德。他们都失去了视力,都是了不起的音乐家--这并不是巧合。当一个人失明时,大脑中负责视觉的区域就会停止兴奋。这导致其他区域接管了曾经由枕叶皮层占据的领土。其他区域,如负责声音和气味的区域,扩大并占据了更多的空间。因此,这些感官变得更加敏锐。这一过程也发生在其他损伤上。在聋人中,听觉皮层最终被用于视觉。 > Ray Charles, Ronnie Milsap, Andrea Bocelli, Stevie Wonder. All of them lost their sight and are marvellous musicians — it’s not by coincidence. When a person becomes blind, the area of the brain responsible for the vision stops being excited. This results in other areas taking over the territory that was once occupied by the occipital cortex. Other areas such as the ones responsible for sound and smell, expand and take up more real estate. Hence these senses become sharper. This process happens for other impairments as well. In the deaf, the auditory cortex ends up being used for vision. 考虑到大脑重组的速度,有人认为梦是一种防御机制。当我们进入睡眠状态时,我们的视觉皮层发现自己处于不利地位。如果你仔细想想,它是唯一失去的感官--我们仍然能够听到、尝到、感觉到和闻到。这是不公平的。 大脑为了保护视觉皮层不被占领,在内部创造图像和视频(梦境),我们闭着眼睛看。这样一来,视觉就安全了。 > Considering how quickly the brain reorganizes, it’s suggested that dreams are a defence mechanism. When we go to sleep, our vision cortex finds itself in a disadvantage. If you think about it, it’s the only sense that is lost — we are still able to hear, taste, feel and smell. It’s unfair. > The brain, to protect the visual cortex from being taken over, creates images and videos internally (the dreams) and we see with our eyes shut. This way, vision is safe. 下面是书中的一段话: 我们认为,做梦的存在是为了保持视觉皮层不被邻近区域所占据。 > Here’s a quote from the book: We suggest that dreaming exists to keep the visual cortex from being taken over by neighboring areas. ----- #### 关于梦的一些调查 不过....盲人就不会做梦了吗。 [盲人做梦是什么样子的?](https://www.zhihu.com/question/19887068) > 梦境中只会出现平时生活中所接触的物体,场景和幻想出来的场景。 > > 会有物体的大致轮廓,形状。这些轮廓并不是视觉轮廓,是感知轮廓。也就是触觉轮廓和听觉轮廓。 > > 梦中没有视觉场景,只有听觉,触觉等感知场景。 > > ----- > > 2岁半的时候失明,只有一点光感,18岁光感基本都没有了。怎么说呢,有光感的时候做梦还是能看到东西的,就跟现实中一样的感觉,印象中就没有出现过需要用到视力而苦恼的情节。**18岁之后,光感几乎没了,颜色也看不了了,做梦基本就没有视觉的体验了**。 [盲人的梦会是什么样子的呢? InVisor学术科研](https://zhuanlan.zhihu.com/p/259555913) > 失明大体上有两种情况,1)因为视觉神经以及相关的大脑视觉皮层损伤从而导致的神经性失明,又称先天性失明;2)其他非神经性原因导致的失明(比如眼角膜,白内障或者青光眼等等)。 > > **在视觉感知和视觉想象这两种不同的认知任务中,激活的大脑区域里有三分之二是相同的**[[2\]](https://zhuanlan.zhihu.com/p/259555913#ref_2)。 > > 有的同学会很好奇那另外三分之一。视觉想象不需要大脑中早期视觉皮层的参与,而与之相反的是,视觉感知任务中,早期视觉皮层会不断地被激活,接受从视神经传递过来的神经信号。 > > 在这里不得不提一下我们看到世界的大脑运作机制。 > > 简单来说,外界环境中各种可见光波,在通过眼球和视网膜之后会激活相应的视神经,而这些视神经会把光信号转化为神经冲动,通过交叉分别传递到左右半脑的视觉皮层,而这其中最早接受到视神经传递过来信号的区域,就是**早期视觉皮层(early visual cortex)**。(同学们转转小脑袋,把高中生物知识捡起来) > > 而在这其中,通过一些手段,比如核磁共振(MRI),Knauff和他的同事证明了想象和感知在大脑皮层中一些显著的区别。在想象任务中(想象一下你上次看自家爱豆的情形),对于感知功能很重要的主要视觉皮层并没有直接被激活;相反,想象的图像是由负责空间和大脑皮层中高阶视觉网络共同协作的产物[[3\]](https://zhuanlan.zhihu.com/p/259555913#ref_3)。 > > 心理学开派祖师爷**弗洛依德**(Sigmund Freud)曾认为**梦来自于潜意识和意识之间的冲突**。我们了解到盲人们不仅可以在脑海里想象出极其生动的画面,他们甚至可能会拥有比普通人更强的感官刺激。一些研究也已经发现盲人也会做梦,而且他们的梦都包含了一些视觉图像,声音,触感以及情绪。 另外粗略搜了下[做梦的理由](https://www.healthline.com/health/why-do-we-dream)。 - Dreams as therapists - Dreams as fight-or-flight training 做梦时,大脑中最活跃的区域之一是杏仁核。杏仁核是大脑中与生存本能和战斗或逃跑反应有关的部分。 一种理论认为,由于杏仁核在睡眠期间比在清醒时更活跃,这可能是大脑让你准备好应对威胁的方式。 幸运的是,脑干在快速眼动睡眠期间发出神经信号,放松你的肌肉。这样,你就不会在睡梦中试图奔跑或打拳。 > One of the areas of the brain that’s most active during dreaming is the amygdala. The amygdala is the part of the brain associated with the survival instinct and the fight-or-flight response. > > One theory suggests that because the **amygdala** is more active during sleep than in your waking life, it may be the brain’s way of getting you ready to deal with a threat. > > Fortunately, the brainstem sends out nerve signals during REM sleep that relax your muscles. That way you don’t try to run or punch in your sleep. <img src="https://external-content.duckduckgo.com/iu/?u=https%3A%2F%2Fdz9yg0snnohlc.cloudfront.net%2Fthe-amygdala-function-and-psychology-of-fight-or-flight-1.jpg&f=1&nofb=1" alt="The Amygdala: Function & Psychology Of Fight Or Flight ..." style="zoom:33%;" /> - Dreams as your muse - Dreams as memory aides 考虑到杏仁核(amygdala)活跃的那个说法,想到自己做梦与否是跟睡姿有关,是不同的朝向压迫到杏仁核了吗.... #### 神经科学|阅读如何重塑你的大脑的过程 原文:[This Is How Reading Rewires Your Brain, According to Neuroscience](https://entrylevelrebel.medium.com/this-is-how-reading-rewires-your-brain-according-to-neuroscience-132fcc26307b) ##### The short- and long-term effects of reading on the brain. 不同的专家对一些细微的细节意见不一,但越来越多的科学文献表明,阅读基本上是一种移情锻炼。通过促使我们从与自己截然不同的人物角度出发,它提高了我们的EQ。当你阅读时,这种效果可以从你的脑电波中看到。 > Different experts disagree on some of the finer details, but a growing body of scientific literature shows that reading is basically an **empathy workout**.By nudging us to take the perspective of characters very different from ourselves, it boosts our EQ. This effect can literally be seen in your brain waves when you read. 另一项研究表明,深度阅读,即当你长时间蜷缩在一本好书中时发生的那种阅读,也能培养我们专注和掌握复杂想法的能力。研究表明,你真正的阅读越少(从手机上略读不算),这些基本能力就越枯萎。 > Another line of research shows that deep reading, the kind that happens when you curl up with a great book for an extended period of time, also builds up our ability to focus and grasp complex ideas. Studies show that the less you really read (skim reading from your phone doesn’t count), the more these essential abilities wither. 阅读不仅仅是将事实塞进你的大脑的一种方式。它是一种重新连接你的大脑工作方式的方法。它加强了你想象其他道路的能力,记住细节,描绘详细的场景,并思考复杂的问题。简而言之,阅读不仅使你更有知识,而且在功能上也更聪明。这就是为什么你所崇拜的每个人都能同意的唯一事情是你应该多读书。 > Reading isn’t just a way to cram facts into your brain. It’s a way to rewire how your brain works in general. It strengthens your ability to imagine alternative paths, remember details, picture detailed scenes, and think through complex problems. In short, reading makes you not just more knowledgeable, but also functionally smarter. Which is why the only thing that everyone you admire can agree on is that you should read more. ### 一点收获 - [v2ex 条件跨数据库了 如何分页查询](https://www.v2ex.com/t/773074#reply4) 1. PostgreSQL FDW 2. 复制到 ES 3. apache calcite - [Curated list of awesome lists](https://project-awesome.org/)