> 2021年07月26日信息消化 ### Introduction to open source private LTE and 5G networks origin: [Introduction to open source private LTE and 5G networks](https://ubuntu.com/blog/introduction-to-open-source-private-lte-and-5g-networks) You might be scared of high upfront costs required to start building an LTE or 5G network. Fortunately, it’s not that bad. The minimum starting toolkit would be `LimeSDR mini` and a `Raspberry Pi 4`. Total cost of this is below 300$ (assuming that you already have a mobile phone…)! If you want to play with more advanced features like Carrier Aggregation, achieve top speed and connect hundreds of IoT devices, you would need to spend around 10k$ for `Ettus x310` and some decent X86 server for compute. As a software stack I can recommend Ubuntu + srsRAN https://github.com/srsran/srsRAN. ##### How to build an enterprise grade private mobile network Basic schematics of a private LTE or 5G network would look like this:  - User equipment – this is anything from a mobile phone, to IoT devices, drones or self driving vehicles. - Radio Access Network – this is a part containing the base station, antennas and L1/L2 processing. - Evolved packet core – a framework for providing converged voice and data on LTE - Micro cloud – a new class of infrastructure for on-demand [computing at the edge](https://ubuntu.com/blog/what-is-mec-the-telco-edge) A working open source implementation of such a network would be: 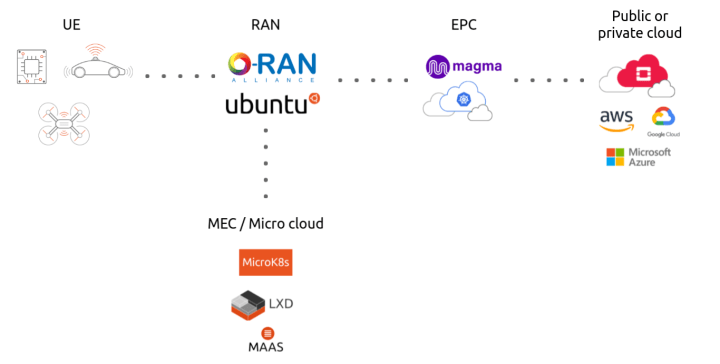 - OpenRAN for disaggregated, and open radio access network, running RIC, RU, CU and DU on Ubuntu operating system - Magma core providing state of the art EPC, with Federation Gateway and Access Gateway (since 1.15 migrated to Ubuntu) - [Charmed Kubernetes](https://ubuntu.com/kubernetes) to provide container infrastructure for RAN and EPC - [Charmed OpenStack](https://ubuntu.com/openstack), providing easy to operate, telco grade private cloud - Combination of [MAAS](https://maas.io/), [LXD](https://linuxcontainers.org/lxd/introduction/) and [MicroK8s](https://microk8s.io/) which build state of the art micro cloud allowing you to run your edge applications as VMs, containers, bare metal and providing all EPA features like DPDK, SR-IOV or NVIDIA GPU acceleration ### Typewriter Animation That Handles Anything You Throw at It origin: [Typewriter Animation That Handles Anything You Throw at It](https://css-tricks.com/typewriter-animation-that-handles-anything-you-throw-at-it/?ref=sidebar) <iframe height="300" style="width: 100%;" scrolling="no" title="Typing Animation with infinite looping" src="https://codepen.io/seekertruth/embed/PopVBOm?default-tab=result" frameborder="no" loading="lazy" allowtransparency="true" allowfullscreen="true"> See the Pen <a href="https://codepen.io/seekertruth/pen/PopVBOm"> Typing Animation with infinite looping</a> by Murtuza (<a href="https://codepen.io/seekertruth">@seekertruth</a>) on <a href="https://codepen.io">CodePen</a>. </iframe> ```html <div class="container"> <div class="text_hide"></div> <div class="text">Typing Animation</div> <div class="text_cursor"></div> </div> ``` We could use `::before` and `::after` pseudo-elements here, but they aren’t great for JavaScript. Pseudo-elements are not part of the DOM, but instead are used as extra hooks for styling an element in CSS. It’d be better to work with real elements. ```css .text_hide { position: absolute; top: 0; bottom: 0; left: 0; right: 0; background-color: white; } .text_cursor{ position: absolute; top: 0; bottom: 0; left: 0; right: 0; background-color: transparent; border-left: 3px solid black; } ``` ```js function typing_animation() { let text_element = document.querySelector(".text"); let text_array = text_element.innerHTML.split(""); let text_array_slice = text_element.innerHTML.split(" "); let text_len = text_array.length; const word_len = text_array_slice.map((word) => { return word.length; }) console.log(word_len); let timings = { easing: `steps(${Number(word_len[0] + 1)}, end)`, delay: 2000, duration: 2000, fill: 'forwards' } let cursor_timings = { duration: 700, iterations: Infinity, easing: 'cubic-bezier(0,.26,.44,.93)' } document.querySelector(".text_cursor").animate([ { opacity: 0 }, { opacity: 0, offset: 0.7 }, { opacity: 1 } ], cursor_timings); if (text_array_slice.length == 1) { timings.easing = `steps(${Number(word_len[0])}, end)`; let reveal_animation = document.querySelector(".text_hide").animate([ { left: '0%' }, { left: `${(100 / text_len) * (word_len[0])}%` } ], timings); document.querySelector(".text_cursor").animate([ { left: '0%' }, { left: `${(100 / text_len) * (word_len[0])}%` } ], timings); reveal_animation.onfinish = () => { setTimeout(() => { document.querySelector('.text_hide').animate([ {left: '0%'} ], { duration: 2000, easing: 'cubic-bezier(.73,0,.38,.88)' }); document.querySelector('.text_cursor').animate([ {left: '0%'} ], { duration: 2000, easing: 'cubic-bezier(.73,0,.38,.88)' }); typing_animation(); }, 1000); } } else { document.querySelector(".text_hide").animate([ { left: '0%' }, { left: `${(100 / text_len) * (word_len[0] + 1)}%` } ], timings); document.querySelector(".text_cursor").animate([ { left: '0%' }, { left: `${(100 / text_len) * (word_len[0] + 1)}%` } ], timings); } for (let i = 1; i < text_array_slice.length; i++) { console.log(word_len); console.log(text_array_slice.length); const single_word_len = word_len[i]; console.log(single_word_len); if (i == 1) { var left_instance = (100 / text_len) * (word_len[i - 1] + 1); console.log(left_instance); } let timings_2 = { easing: `steps(${Number(single_word_len + 1)}, end)`, delay: (2 * (i + 1) + (2 * i)) * (1000), // delay: ((i*2)-1)*1000, duration: 2000, fill: 'forwards' } if (i == (text_array_slice.length - 1)) { timings_2.easing = `steps(${Number(single_word_len)}, end)`; let reveal_animation = document.querySelector(".text_hide").animate([ { left: `${left_instance}%` }, { left: `${left_instance + ((100 / text_len) * (word_len[i]))}%` } ], timings_2); document.querySelector(".text_cursor").animate([ { left: `${left_instance}%` }, { left: `${left_instance + ((100 / text_len) * (word_len[i]))}%` } ], timings_2); reveal_animation.onfinish = () => { setTimeout(() => { document.querySelector('.text_hide').animate([ {left: '0%'} ], { duration: 2000, easing: 'cubic-bezier(.73,0,.38,.88)' }); document.querySelector('.text_cursor').animate([ {left: '0%'} ], { duration: 2000, easing: 'cubic-bezier(.73,0,.38,.88)' }); typing_animation(); }, 1000); } } else { document.querySelector(".text_hide").animate([ { left: `${left_instance}%` }, { left: `${left_instance + ((100 / text_len) * (word_len[i] + 1))}%` } ], timings_2); document.querySelector(".text_cursor").animate([ { left: `${left_instance}%` }, { left: `${left_instance + ((100 / text_len) * (word_len[i] + 1))}%` } ], timings_2); } left_instance = left_instance + ((100 / text_len) * (word_len[i] + 1)); } } typing_animation(); ``` ### 0152 – Letter To A Young Songwriter origin: [0152 – Letter To A Young Songwriter](http://visakanv.com/1000/0152-letter-to-a-young-songwriter/) ##### Write the worst song you can. Just write a song. Make it as stupid and silly as you can. Finish it. Allow it to be a little strange, weird and rough around the edges. In fact, go especially out of your way to try and write the worst song ever. Then try and top that with something even worse, if possible. It’s hard to find good ideas when you’re looking for good ideas, but you can sometimes find them just next door when you’re looking for bad ideas. When you’ve written a hundred songs, you’ll look back and realize that you’ve learnt things that you couldn’t possibly have anticipated when you were starting out. I haven’t written a hundred songs, but this is my experience with writing blogposts, and I imagine songs are no different. Quantity has a quality all of its own. ##### Avoid trying to be original; learn other people’s songs instead. Trying to be original is exhausting, and it is impossible. Give up the pursuit altogether. There’s no such thing as original, everything is derivative. [Everything is a remix.](https://www.youtube.com/watch?v=coGpmA4saEk) The artists who are held up as ‘original’ are simply much better at remixing than everybody else. They make familiar remixes with elements people don’t quite expect, or they make unfamiliar mixes with familiar elements. All great artists start out producing derivative work. There’s no other way to learn! You learned walking and talking through imitation, and you’ll learn to write by doing the same. ‘Originality’ or ‘personal style’ are things that emerge not from you trying to be creative or original, but from you trying to make things as well as you possibly can. ##### Smartness is overrated, think less and write more. When I look back on my life and my work, I find that I greatly overvalued ‘smartness’. On hindsight, I would happily trade quite a chunk of ‘intelligence’ for ‘more data points’. Both Bill Gates and Steve Jobs have interesting things to say about this. Let me quickly paraphrase both of them: Gates: Intelligence is the ability to enter a new field and to ask thoughtful questions- [Well, what about this?](http://beginnersinvest.about.com/od/billgates/l/blbillgatesint.htm) What about that? What if we reversed it? To get good at this, you just need to turn things around and over in your head as much as you can. Take things apart, put them back together. Over time you’ll notice that things aren’t as opaque as they seem. Really, everything is made up of other things, and it’s not too difficult to start seeing patterns in the way they work. Jobs: [Creativity is just connecting things](http://archive.wired.com/wired/archive/4.02/jobs_pr.html), and to connect things you need two things- a bunch of dots to connect, and the habit of attempting connections. You won’t get them right all the time right from the beginning. Nobody does, and there’s reason to believe that you’ll never quite improve your batting average. You can only just step up to the plate more often. So collect as many dots as you can, and mess around with connections as much as you can. Tinker. Make a mess. Clean it up and start over. ##### A quick recap/rewrite of this post: 1. **Aim to be prolific**, rather than “to be great” or “to have fun”. We can have much more interesting conversations once you have a body of work. 2. **Screw ‘best’.** Avoid trying to write the best possible song. Your definition of ‘best’ will be a moving target. 3. **Write badly.** Deliberately try to write bad songs, rough songs, strange and awkward songs. They’ll teach you more than you’ll learn from writing what you think is “okay”. 4. **Screw originality.** Forsake the quest for originality, it’s a mirage. Learn other people’s songs as much as you can. Learn songs from genres you don’t really care for. 5. **Think less, write more.** Don’t try to be smarter by thinking harder. Be smarter by processing more, recursively. Write new songs. Learn songs you didn’t know. Learn new chord progressions. Take long walks through unfamiliar territories. 6. **Play scales.** It’s like learning to play with the underlying code of music itself. It’ll improve your appreciation of music that you listen to, and it’ll improve your ability to navigate the music you play. 7. **Play slow.** Don’t rush after music. Immerse yourself in it. Imagine really bad sex, and then imagine really good sex. What’s the difference? Good music is like good sex. 8. **Always Be Creating (Or Listening).** If you’re not doing one of the two, you’re probably procrastinating. Ask yourself which of the two states you’re closer to, and dive into that. ### A Brief History of Neural Nets and Deep Learning Origin: [A Brief History of Neural Nets and Deep Learning](https://www.skynettoday.com/overviews/neural-net-history) ##### Prologue: The Deep Learning Tsunami > “Deep Learning waves have lapped at the shores of computational linguistics for several years now, but 2015 seems like the year when the full force of the tsunami hit the major Natural Language Processing (NLP) conferences.” -[Dr. Christopher D. Manning, Dec 2015](http://www.mitpressjournals.org/doi/pdf/10.1162/COLI_a_00239) This may sound hyperbolic - to say the established methods of an entire field of research are quickly being superseded by a new discovery, as if hit by a research ‘tsunami’. But, this catastrophic language is appropriate for describing the meteoric rise of Deep Learning over the last several years - a rise characterized by drastic improvements over reigning approaches towards the hardest problems in AI, massive investments from industry giants such as Google, and exponential growth in research publications (and Machine Learning graduate students). Having taken several classes on Machine Learning, and even used it in undergraduate research, I could not help but wonder if this new ‘Deep Learning’ was anything fancy or just a scaled up version of the ‘artificial neural nets’ that were already developed by the late 80s. And let me tell you, the answer is quite a the story - the story of not just neural nets, not just of a sequence of research breakthroughs that make Deep Learning somewhat more interesting than ‘big neural nets’ (that I will attempt to explain in a way that just about anyone can understand), but most of all of how several unyielding researchers made it through dark decades of banishment to finally redeem neural nets and achieve the dream of Deep Learning. 这听起来很夸张--说整个研究领域的既定方法很快就被新的发现所取代,就像被一场研究 "海啸 "击中一样。但是,这种灾难性的语言适合用来描述深度学习在过去几年中的飞速发展--这种发展的特点是对人工智能中最难的问题的统治性方法进行了大幅改进,来自谷歌等行业巨头的大量投资,以及研究出版物(和机器学习研究生)的指数式增长。我上过几堂关于机器学习的课,甚至在本科生研究中使用过它,我不禁想知道这个新的 "深度学习 "是什么花哨的东西,还是只是80年代末已经开发的 "人工神经网络 "的放大版。让我告诉你,答案是一个相当的故事--这个故事不仅仅是神经网络的故事,不仅仅是一连串的研究突破使深度学习比'大神经网络'更有趣的故事(我将试图以一种几乎任何人都能理解的方式来解释),最重要的是几个不屈不挠的研究人员如何通过黑暗的几十年的放逐,最终赎回神经网络,实现深度学习的梦想。 #### Part 1: The Beginnings (1950s-1980s) ##### The Centuries Old Machine Learning Algorithm This generalization principle is so important that there is almost always a test set of data (more examples of inputs and outputs) that is not part of the a training set. The separate set can be used to evaluate the effectiveness of machine learning technique by seeing how many of the examples the method correctly computes outputs for given the inputs. The nemesis of generalization is overfitting - learning a function that works really well for the a training set but badly on the test set. Since machine learning researchers needed means to compare the effectiveness of their methods, over time there appeared standard datasets of a training and testing sets that could be used to evaluate machine learning algorithms. 这个泛化原则非常重要,几乎总是有一个不属于训练集的测试数据集(更多的输入和输出的例子)。这个独立的数据集可以用来评估机器学习技术的有效性,看该方法在给定的输入中,有多少例子能正确计算出输出。泛化的克星是过度拟合--学习一个对训练集非常有效的函数,但在测试集上却很糟糕。由于机器学习研究人员需要比较其方法的有效性,随着时间的推移,出现了训练集和测试集的标准数据集,可用于评估机器学习算法。 ##### The Folly of False Promises Why have all this prologue with linear regression, since the topic here is ostensibly neural nets? Well, in fact linear regression bears some resemblance to the first idea conceived specifically as a method to make machines learn: Frank Rosenblatt’s Perceptron A psychologist, Rosenblatt conceived of the Percetron as a simplified mathematical model of how the neurons in our brains operate: it takes a set of binary inputs (nearby neurons), multiplies each input by a continuous valued weight (the synapse strength to each nearby neuron), and thresholds the sum of these weighted inputs to output a 1 if the sum is big enough and otherwise a 0 (in the same way neurons either fire or do not). Most of the inputs to a Perceptron are either some data or the output of another Perceptron, but an extra detail is that Perceptrons also have one special ‘bias’ input, which just has a value of 1 and basically ensures that more functions are computable with the same input by being able to offset the summed value. This model of the neuron built on the work of Warren McCulloch and Walter Pitts Mcculoch-Pitts 3, who showed that a neuron model that sums binary inputs and outputs a 1 if the sum exceeds a certain threshold value, and otherwise outputs a 0, can model the basic OR/AND/NOT functions. This, in the early days of AI, was a big deal - the predominant thought at the time was that making computers able to perform formal logical reasoning would essentially solve AI. 作为一名心理学家,罗森布拉特将Percetron设想为我们大脑中的神经元如何运作的简化数学模型:它接受一组二进制输入(附近的神经元),将每个输入乘以一个连续值的权重(对每个附近神经元的突触强度),并对这些加权输入的总和进行阈值处理,如果总和足够大则输出1,否则输出0(与神经元发射或不发射的方式相同)。一个感知器的大部分输入要么是一些数据,要么是另一个感知器的输出,但一个额外的细节是感知器也有一个特殊的 "偏置 "输入,它的值是1,基本上可以确保更多的函数可以用相同的输入进行计算,因为它能够抵消加起来的值。这种神经元模型建立在沃伦-麦库洛赫(Warren McCulloch)和沃尔特-皮茨(Walter Pitts Mcculoch-Pitts)3的工作之上,他们表明,一个对二进制输入进行求和的神经元模型,如果求和值超过某个阈值,就输出1,否则就输出0,可以模拟基本的OR/AND/NOT函数。在人工智能的早期,这是件大事--当时的主流思想是,让计算机能够进行正式的逻辑推理,基本上就能解决人工智能。 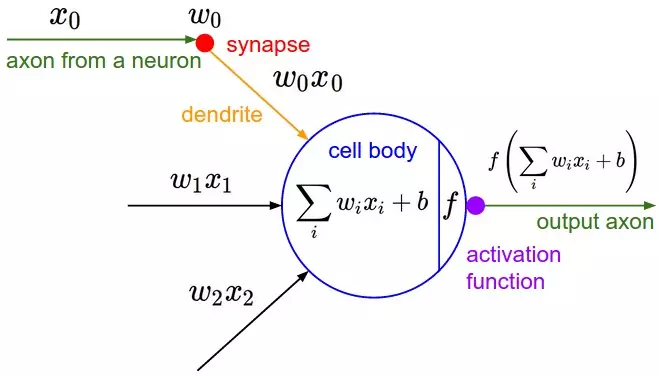 Another diagram, showing the biological inspiration. The activation function is what people now call the non-linear function applied to the weighted input sum to produce the output of the artificial neuron - in the case of Rosenblatt's Perceptron, the function just a thresholding operation. (Source) #### Part 2: Neural Nets Blossom (1980s-2000s) With the secret to training multilayer neural nets uncovered, the topic was once again ember-hot and the lofty ambitions of Rosenblatt seemed to perhaps be in reach. It took only until 1989 for another key finding now universally cited in textbooks and lectures to be [published](http://www.sciencedirect.com/science/article/pii/0893608089900208) : “Multilayer feedforward networks are universal approximators”. Essentially, it mathematically proved that multiple layers allow neural nets to theoretically implement any function, and certainly XOR. 随着训练多层神经网络的秘密被揭开,这个话题再次变得炙手可热,罗森布拉特的崇高雄心似乎也可以实现了。直到1989年,另一个现在被教科书和讲座普遍引用的关键发现才被发表。"多层前馈网络是通用的近似器"。从本质上讲,它从数学上证明了多层神经网络在理论上可以实现任何功能,当然还有XOR。 But, this is mathematics, where you could imagine having endless memory and computation power should it be needed - did backpropagation allow neural nets to be used for anything in the real world? Oh yes. Also in 1989, Yann LeCun et al. at the AT&T Bell Labs demonstrated a very significant real-world application of backpropagation in ["”Backpropagation Applied to Handwritten Zip Code Recognition”](http://yann.lecun.com/exdb/publis/pdf/lecun-89e.pdf) . You may think it fairly unimpressive for a computer to be able to correctly understand handwritten digits, and these days it is indeed quite quaint, but prior to the publication the messy and inconsistent scrawls of us humans proved a major challenge to the much more tidy minds of computers. The publication, working with a large dataset from the US Postal Service, showed neural nets were entirely capable of this task. And much more importantly, it was first to highlight the practical need for a key modifications of neural nets beyond plain backpropagation toward modern deep learning: 但是,这是数学,你可以想象有无尽的内存和计算能力,如果需要的话--反向传播允许神经网络在现实世界中用于任何东西吗?哦,是的。同样在1989年,AT&T贝尔实验室的Yann LeCun等人在 "Backpropagation Applied to Handwritten Zip Code Recognition "中展示了Backpropagation的一个非常重要的现实世界应用。你可能认为计算机能够正确地理解手写数字是相当不令人印象深刻的,而且现在它确实是相当古怪的,但在该出版物发表之前,我们人类的凌乱和不一致的笔迹被证明是对计算机更整洁的头脑的重大挑战。该出版物使用了美国邮政局的一个大型数据集,表明神经网络完全有能力完成这项任务。更重要的是,它首次强调了对神经网络进行关键修改的实际需要,即超越普通的反向传播,走向现代深度学习。 #### Part 3: Deep Learning (2000s-2010s) #### The Funding of More Layers With the ascent of Support Vector Machines and the failure of backpropagation, the early 2000s were a dark time for neural net research. LeCun and Hinton variously mention how in this period their papers or the papers of their students were routinely rejected from being published due to their subject being Neural Nets. Certainly research in Machine Learning and AI was still very active, and other people were also still working with neural nets, but citation counts from the time make it clear that the excitement had leveled off, even if it did not completely evaporate. Still, Hinton, Bengio, and Lecun in particular persevered in their belief neural nets merit research. And they found a strong ally outside the research realm: The Canadian government. Funding from the Canadian Institute for Advanced Research (CIFAR), which encourages basic research without direct application, was what motivated Hinton to move to Canada in 1987, and funded his work afterward. But, the funding was ended in the mid 90s just as sentiment towards neural nets was becoming negative again. Rather than relenting and switching his focus, Hinton fought to continue work on neural nets, and managed to secure more funding from CIFAR as told well in this exemplary piece45: The funding was modest, but sufficient to enable a small group of researchers to keep working on the topic. As Hinton tells it, they hatched a conspiracy: “rebrand” the frowned-upon field of neural nets with the moniker “deep learning” [45](https://www.skynettoday.com/overviews/neural-net-history#fn:part4_1). Then, what every researcher must dream of actually happened: Hinton, Simon Osindero, and Yee-Whye Teh published a paper in 2006 that was seen as a breakthrough, a breakthrough significant enough to rekindle interest in neural nets: [**A fast learning algorithm for deep belief nets**](https://www.cs.toronto.edu/~hinton/absps/fastnc.pdf) . Though, as we’ll see, the approaches used in the paper have been superceded by newer work, the movement that is ‘deep learning’ can be said to have started precisely with this paper. But, more important than the name was the idea - that neural networks with many layers really could be trained well, if the weights are initialized in a clever way rather than randomly. Hinton [once expressed](https://youtu.be/vShMxxqtDDs?t=6m59s) the need for such an advance at the time: 这笔资金不多,但足以让一小群研究人员继续研究这个课题。正如辛顿所说,他们策划了一个阴谋:用 "深度学习 "这一名称 "重塑 "被人诟病的神经网络领域45。然后,每个研究人员必须梦想的事情真的发生了。Hinton、Simon Osindero和Yee-Whye Teh在2006年发表了一篇被视为突破的论文,这一突破的重要性足以重新点燃人们对神经网络的兴趣。深度信仰网的快速学习算法。尽管正如我们所看到的,论文中使用的方法已经被新的工作所取代,但 "深度学习 "这一运动可以说正是从这篇论文开始的。但是,比这个名字更重要的是这个想法--如果权重以一种巧妙的方式而不是随机地初始化,那么具有许多层的神经网络真的可以被很好地训练。辛顿曾经表示,当时需要这样的进步。 1. Train an RBM on the training data using contrastive-divergence. This is the first layer of the belief net. 2. Generate the hidden values of the trained RBM for the data, and train another RBM using those hidden values. This is the second layer - ‘stack’ it on top of the first and keep weights in just one direction to form a belief net. 3. Keep doing step 2 for as many layers as are desired for the belief net. 4. If classification is desired, add a small set of hidden units that correspond to the classification labels and do a variation on the wake-sleep algorithm to ‘fine-tune’ the weights. Such combinations of unsupervised and supervised learning are often called **semi-supervised** learning. 1. 在训练数据上使用对比-分歧法训练RBM。这是信念网的第一层。 2. 2.为数据生成训练过的RBM的隐藏值,并使用这些隐藏值训练另一个RBM。这是第二层--将其 "堆叠 "在第一层之上,并在一个方向上保持权重,以形成一个信念网。 3. 3.继续做第2步,为信仰网做尽可能多的层。 4. 4. 如果需要分类,添加一小部分隐藏单元,与分类标签相对应,做一个唤醒-睡眠算法的变体来 "微调 "权重。这种无监督和有监督的学习组合通常被称为**半监督**学习。 They also present reasons for why the addition of unsupervised pre-training works, and conclude that this not only initializes the weights in a more optimal way, but perhaps more importantly leads to more useful learned representations of the data. In fact, using RBMs is not that important - unsupervised pre-training of normal neural net layers using backpropagation with plain Autoencoders layers proved to also work well. Likewise, at the same time another approach called Sparse Coding also showed that unsupervised feature learning was a powerful approach for improving supervised learning performance. So, the key really was having many layers of computing units so that good high-level representation of data could be learned - in complete disagreement with the traditional approach of hand-designing some nice feature extraction steps and only then doing learning using those features. Hinton and Bengio’s work had empirically demonstrated that fact, but more importantly, showed the premise that deep neural nets could not be trained well to be false. This, LeCun had already demonstrated with CNNs throughout the 90s, but neural nets still went out of favor. Bengio, in collaboration with Yann LeCun, reiterated this on [“Scaling Algorithms Towards AI”](http://yann.lecun.com/exdb/publis/pdf/bengio-lecun-07.pdf) 他们还提出了增加无监督预训练的原因,并得出结论,这不仅以更优化的方式初始化了权重,而且也许更重要的是导致了更有用的数据学习表示。事实上,使用RBM并不那么重要--事实证明,使用反向传播和普通自动编码器层的普通神经网层的无监督预训练也很有效。同样,在同一时间,另一种叫做稀疏编码的方法也表明,无监督的特征学习是一种改善监督学习性能的强大方法。 因此,真正的关键是拥有许多层的计算单元,这样就可以学习到好的数据高层表征--与传统的手工设计一些漂亮的特征提取步骤,然后才使用这些特征进行学习的方法完全不同。Hinton和Bengio的工作从经验上证明了这一事实,但更重要的是,表明深度神经网络不能被很好地训练这一前提是错误的。这一点,LeCun在整个90年代已经用CNN证明了,但神经网络仍然不受青睐。Bengio与Yann LeCun合作,在 "Scaling Algorithms Towards AI "上重申了这点。 ##### Epilogue: The Decade of Deep Learning If this were a movie, the 2012 ImageNet competition would likely have been the climax, and now we would have a progression of text describing ‘where are they now’. Yann LeCun - Facebook. Geoffrey Hinton - Google. Andrew Ng - Coursera, Google, Baidu, and more. Bengio, Schmidhuber, and Li actually still in academia but with their own industry affiliations too, and presumably with many more citations and/or grad students 如果这是一部电影,2012年的ImageNet比赛很可能是一个高潮,现在我们会有一个描述 "他们现在在哪里 "的文字进展。Yann LeCun - Facebook。Geoffrey Hinton - 谷歌。Andrew Ng - Coursera, Google, Baidu, and more. Bengio、Schmidhuber和Li实际上仍在学术界,但也有他们自己的行业关系,而且估计有更多的引用和/或研究生。 (and, the many more who contributed to the emergence of Deep Learning . Though the ideas and achievements of deep learning are definitely exciting, while writing this I was inevitably also moved that these people, who worked in this field for decades (even as most abandoned it), are now rich, successful, and most of all better situated to do research than ever. All these peoples’ ideas are still very much out in the open, and in fact basically all these companies are open sourcing their deep learning frameworks, like some sort of utopian vision of industry-led research. What a story. (而且,还有很多对深度学习的出现有贡献的人。虽然深度学习的想法和成就肯定是令人兴奋的,但在写这篇文章的时候,我也不可避免地被感动了,这些人在这个领域工作了几十年(甚至在大多数人放弃这个领域的时候),现在很富有,很成功,最重要的是比以前更有条件做研究。所有这些人的想法仍然非常开放,事实上,基本上所有这些公司都在开放他们的深度学习框架,就像某种乌托邦式的产业主导型研究的愿景。真是个好故事。 Since 2012, it’s fair to say Deep Learning has revolutionized much of AI as a field. As we read at the start of all this, “2015 seems like the year when the full force of the tsunami hit the major Natural Language Processing (NLP) conferences.” And so it was with Computer Vision, Robotics, Audio Processing, AI for Medicine, and so much more. To summarize all the ground breaking developments in this period would take its own lengthy sub-history, and has already been done nicely in the blog post [“The Decade of Deep Learning”](https://bmk.sh/2019/12/31/The-Decade-of-Deep-Learning/). Suffice it today, progress since 2012 was swift and ongoing, and has seen all the applications of neural nets we have seen so far (to reinforcement learning, language modeling, image classification, and much more) extended to leverage Deep Learning resulting in ground breaking accomplishments. 自2012年以来,可以说深度学习已经彻底改变了人工智能这个领域的大部分。正如我们在这篇文章的开头所写的,"2015年似乎是海啸的全部力量冲击主要自然语言处理(NLP)会议的一年。" 计算机视觉、机器人、音频处理、人工智能用于医学,以及其他更多的领域也是如此。总结这一时期的所有突破性发展需要很长的次历史,在博文["深度学习的十年"](https://bmk.sh/2019/12/31/The-Decade-of-Deep-Learning/)中已经做得很好。今天我们只需知道,自2012年以来的进展是迅速而持续的,并且看到了我们迄今为止看到的所有神经网络的应用(强化学习、语言建模、图像分类等等)都扩展到了利用深度学习,从而取得了突破性的成就。 And now here were at 2020. AI as a field is huge and still moving fast, but many of the low-hanging fruit with respect to tackling AI problems with Deep Learning have been plucked, and we are increasingly in a time expanding outwards in terms of varied applications of neural nets and Deep Learning 64. And for good reason: Deep Learning still works best only when there is a huge dataset of input-output examples to learn from, which is not true for many problems in AI, and has other major limitations (interpretability, verifiability, and more). Although this is where this brief history, the history of neural nets is very much still being written, and shall be for some time. Let us hope this powerful technology continues to blossom, and is used primarily to further human well-being and progress well into the future. 现在,我们来到了2020年。人工智能作为一个领域是巨大的,而且仍在快速发展,但在用深度学习解决人工智能问题方面,许多低垂的果实已经被摘下,而且我们正日益处于一个向外扩展的时代,在神经网络和深度学习64的各种应用方面。这是有原因的。深度学习仍然只有在有巨大的输入输出实例数据集可供学习时才能发挥最佳效果,这对人工智能中的许多问题来说都是不真实的,而且还有其他主要的限制(可解释性、可验证性等等)。虽然这就是这段简短的历史,但神经网络的历史在很大程度上仍在书写之中,而且将在一段时间内。让我们希望这项强大的技术继续开花结果,并在未来很长时间内主要用于促进人类的福祉和进步。 ### 一点收获 - Sell the vision first -- **Ed Gandia** - Why → How → What - The biggest most successful and best run organizations I've worked for have not worried about hosting their software. They're concerned with delivering value to customers and doing it quickly. -- [HN Comment](https://news.ycombinator.com/item?id=27939039) - "Finishing projects is part of what it means to deliver high quality work. It's not high quality if your perfectionism prevents you from finishing." -- 3-2-1: How to find opportunities, and what it takes to improve - As a multi-passionate, how do you build a successful business without feeling confused or overwhelmed? -- [racket.com](https://racket.com/volleys/81895)