> 2021年08月02日信息消化 ### Natural Language Processing: From one-hot vectors to billion parameter models origin: [Natural Language Processing: From one-hot vectors to billion parameter models](https://towardsdatascience.com/natural-language-processing-from-one-hot-vectors-to-billion-parameter-models-302c7d9058c6) Human language is ambiguous. Speaking (or writing), we convey the individual words, tone, humour, metaphors, and many more linguistic characteristics. For computers, such properties are hard to detect in the first place and even more challenging to understand in the second place. Several tasks have emerged to address these challenges: - Classification: This task aims to classify text into one or more of several predefined categories - Speech recognition and speech-to-text: These tasks deal with detecting speech in audio signals and transcribing it into textual form - Sentiment analysis: In this task, the sentiment of the text is determined - Natural language generation: This task deals with the generation of natural (that is, human) language This list is by no means exhaustive; one could include Part-of-Speech tagging, (Named) Entity Recognition, and other tasks as well. However, the Natural Language Generation (NLG) field has received the most attention lately from all the listed items. ##### Modelling text To use any textual data as input to neural networks requires a numeric representation. A simple way is to use a Bag of Words (BoW) representation. Following this approach, one only considers the words and their frequency, but not the order: just a bag of words. As an example, take the sentence “The quick brown fox jumps over the fence.” The corresponding BoW is [“The:2”, “quick:1”, “brown:1”, “fox:1”, “jumps:1”, “over:1”, “fence:1”]. The term “the” is translated to 2, which is the count of “the” in the example. ##### Representing words Traditionally, words were regarded as discrete symbols. If we have a total of 20 unique words, each word is represented by a vector of length 20. Only a single index is set to one; all others are left at zero. This representation is called a *one-hot vector*. Using this technique, the words from our example sentence become 传统上,单词被认为是离散的符号。如果我们总共有20个独特的词,每个词就用一个长度为20的向量表示。只有一个索引被设置为1,其他的都留为0。这种表示法被称为单热向量。使用这种技术,我们的例句中的词变成了 [1, 0, 0, 0, 0, …] for “the” [0, 1, 0, 0, 0, …] for “quick” As a sidenote, summing up these vectors, one gets the BoW representation. Two problems arise quickly: Given a considerably large vocabulary, the vectors become very long and very sparse. In fact, only a single index is active. The second problem pertains to the similarity between words. For example, the pair “cat” and “dog” is more similar than “cat” and “eagle.” Relationships like this are not reflected in the one-hot representation. Usually, one uses similarity metrics (or inverse distance metrics) to calculate the similarity between two vectors. A common similarity is [*cosine similarity*](https://en.wikipedia.org/wiki/Cosine_similarity). Coming back to our example pair “cat” and “dog,” we might have the (arbitrary) vectors 有两个问题很快就出现了。考虑到相当大的词汇量,向量变得非常长,而且非常稀疏。事实上,只有一个索引是活跃的。第二个问题涉及到单词之间的相似性。例如,"猫 "和 "狗 "这一对比 "猫 "和 "鹰 "更相似。像这样的关系并没有反映在单枪匹马的表述中。通常,人们使用相似度量(或反距离度量)来计算两个向量之间的相似度。一个常见的相似度是[*cosine相似度*](https://en.wikipedia.org/wiki/Cosine_similarity)。回到我们的例子 "猫 "和 "狗 "这一对,我们可能有(任意的)矢量 [0, 0, 0, 0, 0, 1, 0, 0, 0] for cat [0, 1, 0, 0, 0, 0, 0, 0, 0] for dog The cosine similarity between these vectors is zero. For the pair “cat” and “eagle,” it is zero, too. Consequently, the two results do not reflect the higher similarity of the first pair. To solve this problem, we use embeddings. ##### Embeddings **The core idea behind embeddings:** A word’s meaning is created by the words that regularly appear nearby. To derive the meaning, one uses the word’s context, the set of words that occur within a range around. Averaged over many such contexts, one gets a reasonably accurate representation of the word. Take our example 嵌入背后的核心理念。一个词的含义是由附近经常出现的词创造的。为了推导出这个词的含义,我们使用这个词的上下文,即在周围一定范围内出现的词的集合。对许多这样的语境进行平均,我们就能得到一个合理准确的词的代表。以我们的例子为例 “The quick brown fox jumps over the fence.” For a context window of size one, “fox” has the context words (nearby words) “brown” and “jumps.” For windows of size two, “quick” and “over” will be added. In our short sentence, we will quickly run out of context words and have only one appearance of “fox.” It becomes evident that a large amount of text is needed to create a meaningful representation of entities. We generally want as much context information as possible, which is naturally the case for larger corpora. 对于大小为1的语境窗口,"狐狸 "有语境词(附近的词)"棕色 "和 "跳跃"。对于大小为2的窗口,"快 "和 "过 "将被添加。在我们的短句中,我们将很快用完语境词,只有一个 "狐狸 "的出现。显而易见,需要大量的文本来创建一个有意义的实体表示。我们一般希望有尽可能多的上下文信息,这对于较大的语料库来说自然是如此。 Assuming that we have enough text data, how do we create an embedding? **First, an embedding is a dense vector of size *d***. **Second, words close in meaning have similar embedding vectors, which solves the problem of informative similarity measures introduced above.** Third, there are a couple of algorithms that create word embeddings; [Word2Vec](https://code.google.com/archive/p/word2vec/) is one of them. 假设我们有足够的文本数据,我们如何创建一个嵌入?首先,一个嵌入是一个大小为d的密集向量。第二,意义相近的词有相似的嵌入向量,这就解决了上面介绍的信息相似度的问题。第三,有几个算法可以创建单词嵌入;Word2Vec就是其中之一。 The general idea of all embedding-calculating algorithms is to create valuable embedding vectors for a token. The word2vec algorithm uses words as basic units and focuses on local relationships. To create an embedding vector, we can — with this framework — either concentrate on predicting the centre word from the context or the context from the centre word. The first approach is known as Continuous Bag of Words (CBOW), the second as skip-gram. I will briefly go over the skip-gram approach in the following section: 所有嵌入计算算法的总体思路是为一个标记创建有价值的嵌入向量。word2vec算法将词作为基本单位,并专注于局部关系。为了创建一个嵌入向量,我们可以--在这个框架下--专注于从上下文中预测中心词或从中心词中预测上下文。第一种方法被称为连续词袋(CBOW),第二种方法被称为skip-gram。我将在下一节中简要介绍一下跳格法。 To obtain the embedding vector for any word, we use a neural network. The following figure, taken from [1], shows a schematic representation of the process: 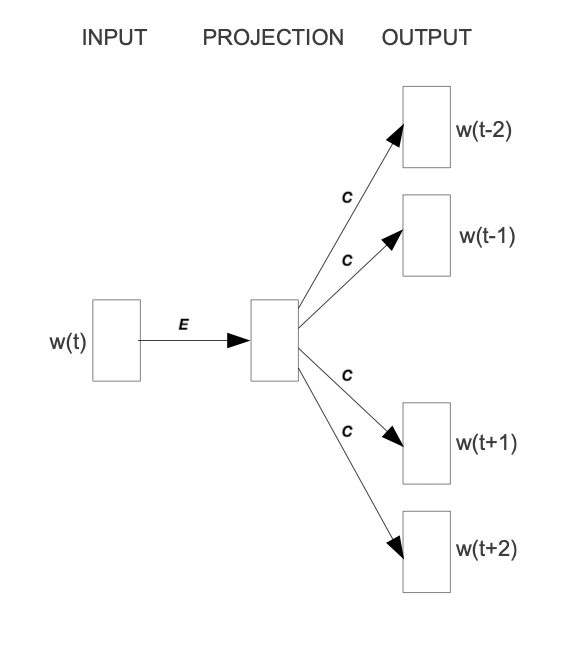 To obtain an embedding for an arbitrary word, we use its one-hot representation. This vector is the input to the network, depicted on the left. In the next step, the vector is projected into its embedding representation, shown in the middle. As usual, this happens by multiplying it with a matrix, marked as *E* in the figure. In other words, this a forward pass in a network. The resulting (hidden) representation is optimized to predict the context words shown on the right side. 为了获得一个任意词的嵌入,我们使用它的单热表示。这个向量是网络的输入,在左边显示。在下一步,该向量被投射到它的嵌入表示中,显示在中间。像往常一样,这是通过与一个矩阵相乘来实现的,图中标记为*E*。换句话说,这是一个网络中的前向通道。由此产生的(隐藏)表示被优化,以预测右侧所示的上下文词。 The output of the network is thus not the embedding but the context words. To predict them, we use another weight, *C*. When we multiply our hidden internal representation with *C*, we get a vector of length *d*, where *d* is our vocabulary size. This resulting vector can be interpreted as the unnormalized probability for each word to appear in the context. Thus, in training our network, we maximize the probability of actual context words and minimize the probability of non-context words. To recap, the vector flow is: 因此,网络的输出不是嵌入,而是上下文词。为了预测它们,我们使用另一个权重,C。当我们把隐藏的内部表示与C相乘时,我们得到一个长度为d的向量,其中d是我们的词汇量大小。这个产生的向量可以解释为每个词在上下文中出现的非标准化概率。因此,在训练我们的网络时,我们最大限度地提高实际语境词的概率,最小化非语境词的概率。简而言之,向量流是。 W_input × E = e | for the multiplication of the one-hot with E out = e × C | for the multiplication of the internal representation with C - d: vocabulary size - E: matrix - C: weight To assess the usefulness of embeddings, head over to TensorFlow’s [Projector tool](https://projector.tensorflow.org/). It lets you explore different embeddings; in our case, the “Word2Vec 10k” dataset is suitable. Click on the “A” to enable labels. You can now visually see the similarity between related words. In the following example, I have searched for the word *machine*. The nearest neighbours are highlighted: 为了评估嵌入的有用性,请前往TensorFlow的投影仪工具。它让你探索不同的嵌入;在我们的例子中,"Word2Vec 10k "数据集是合适的。点击 "A "来启用标签。现在你可以直观地看到相关词之间的相似性。在下面的例子中,我搜索了机器这个词。最近的邻居被突出显示。 First, it captures local relationships. Secondly, it treats words as basic units. Other algorithms take other choices. For example, the [GloVe](https://www.aclweb.org/anthology/D14-1162.pdf) algorithm, short for **Glo**bal **Ve**ctors, creates embeddings based on global relationships and uses words as basic units. A third algorithm is [FastText](https://fasttext.cc/) (see paper references [here](https://fasttext.cc/docs/en/references.html)), which uses sub-word information as basic units (e.g. “this” -> “th” and “is”). 首先,它抓住了局部关系。其次,它将词作为基本单位。其他算法则采取其他选择。例如,[GloVe](https://www.aclweb.org/anthology/D14-1162.pdf)算法是**全球***载体的简称,它基于全球关系创建嵌入,并使用词作为基本单位。第三种算法是[FastText](https://fasttext.cc/)(见论文参考文献[here](https://fasttext.cc/docs/en/references.html)),它使用子词信息作为基本单位(例如,"this"->"th "和 "is")。 A few challenges exist, regardless of algorithm choice: How to handle punctuation? How to handle plural words? Different word forms? Such modifications are part of the pre-processing, which often includes stemming and lemmatization. Stemming reduces a word to its stem. This technique is efficient but can create artificial word stems. Lemmatization tries to reduce a word to its base form, which is often achieved with large databases. 无论选择何种算法,都存在一些挑战:如何处理标点符号?如何处理复数词?不同的单词形式?这些修改是预处理的一部分,预处理通常包括词干化和词缀化。词干化将一个词还原为它的词干。这种技术很有效,但会产生人为的词干。词根化试图将一个词减少到它的基本形式,这通常是在大型数据库中实现的。 With the advance of modern end-to-end approaches, the importance of pre-processing has slightly become less. Only tokenization remains relevant, such as Byte-Pair encodings. Before we get there, we have to take a look at n-grams. 随着现代端到端方法的进步,预处理的重要性已经略微降低。只有标记化仍然相关,如字节对编码。在这之前,我们必须先看一下n-grams。 ##### (Modern) n-gramns To begin incorporating word order, we can use a so-called n-gram approach. Previously, when creating the BoW representation, we split the sentence into single words. Instead, we could also divide it into segments of two successive words, three successive words, and so on. The number of words in a row is the n in n-gram. If n is one, the parsing model is called unigram; if n is two, it is called bigram. As an example, let’s parse “The quick brown fox jumps over the fence” with a bigram model: [“The quick”, “quick brown”, “brown fox”, “fox jumps”, …] The representation is static. If the n parameter changes, the dataset has to be pre-processed again. Depending on the size, this can take a while. However, we can incorporate the n-gram algorithm into neural networks and let them do the “pre-processing.” This approach can be seen as modern n-grams.From the embedding step, we use the obtained dense and informative representation vectors for every single word. To incorporate word order, we have to alter the network input slightly. Given a sentence of length l and embeddings of size e, the input is now a matrix with shape: 该表示法是静态的。如果n参数发生变化,数据集必须再次进行预处理。根据其大小,这可能需要一段时间。然而,我们可以将n-gram算法纳入神经网络,让它们做 "预处理"。这种方法可以被看作是现代n-grams。从嵌入步骤开始,我们使用获得的密集和信息量大的表示向量来表示每一个单词。为了纳入词序,我们必须稍微改变网络输入。给定一个长度为l的句子和大小为e的嵌入,现在的输入是一个有形状的矩阵。 From the embedding step, we use the obtained dense and informative representation vectors for every single word. To incorporate word order, we have to alter the network input slightly. Given a sentence of length *l* and embeddings of size *e*, the input is now a matrix with shape: l x e This matrix can be interpreted as a strange image. In image-related tasks, convolutional neural networks are highly effective, but they are not restricted to this domain. A convolution operation going over the input text-matrix can be interpreted as creating *n*-grams. When the kernel size is set to 2 and the stride to 1, this essentially creates a bi-gram representation. Keeping the stride but increasing the kernel’s size to 3, we obtain a tri-gram model. The drawback of *n*-grams is that they only capture relationships over a limited range. For example, N-grams can not express the connection between the first and last word of a sentence. Setting the parameter *n* to the length of a sentence would work but would require a separate *n* for each differently-sized sentence. There is a better approach to handle relationships over a large span, the attention mechanism. This technique was introduced for machine translation tasks. N*格的缺点是,它们只能捕捉到有限范围内的关系。例如,N-grams不能表达一个句子的第一个和最后一个单词之间的联系。将参数*n*设置为一个句子的长度是可行的,但需要为每个不同大小的句子设置单独的*n*。有一种更好的方法来处理大跨度的关系,即注意力机制。这种技术是为机器翻译任务引入的。 ##### Machine Translation The Machine Translation (MT) task deals with translating text from a source to a target language. For example, “Est-ce que les poissons boivent de l’eau?” (French) would be translated to “Do fishes trink water?” From the 1990s on, statistical MT became the focus. The core idea is to learn a probabilistic model. With an emphasis on translational tasks, this means the following: Given a sentence in a source language, we need to find the most proper sentence in the target language — i.e., the best translation. Mathematically, this is expressed by y* = argmax_y P(y|x). The y* denotes the translation with the highest probability. The advance of deep neural networks also influenced the task of machine translation. Recurrent Neural Networks, RNNs, are a good choice since both the input and output are sequences. The input is the sentence to be translated; the output is the translation. Two problems emerge with a single RNN: First, the source and target sentence lengths can be different. This fact is evident in the initial example translation. The input contains eight tokens, and the output only five (depending on how you count punctuation, but the problem stays the same). Secondly, the word order can change, rendering a single one-in, one-out RNN unusable. The solution to both problems is using two recurrent networks in a so-called Sequence-to-Sequence (Seq2Seq) layout [2,3]. The first network, named encoder, takes the input and yields an internal representation. The second network, called decoder, uses this internal representation to generate the target sequence, e.g., the translation. 深度神经网络的进步也影响了机器翻译的任务。循环神经网络,RNNs,是一个很好的选择,因为输入和输出都是序列。输入是要翻译的句子;输出是翻译。单一的RNN出现了两个问题。首先,源句和目标句的长度可能不同。这一事实在最初的翻译例子中很明显。输入包含八个标记,而输出只有五个(取决于你如何计算标点符号,但问题是不变的)。其次,词序可以改变,使单一的一进一出RNN无法使用。 解决这两个问题的方法是在所谓的序列到序列(Seq2Seq)布局中使用两个递归网络[2,3]。第一个网络,名为编码器,接受输入并产生一个内部表示。第二个网络,称为解码器,使用这个内部表示来产生目标序列,例如,翻译。 ##### Attention In the vanilla sequence-to-sequence layout, the encoder compresses all information about the input sentence into a single vector. This vector is fittingly called the bottleneck layer, as it causes an information bottleneck. Despite the ability to parse endless sequences, the information from earlier steps will slowly fade as new information gets added. 在vanilla Seq2seq的布局中,编码器将有关输入句子的所有信息压缩到一个单一的向量。这个向量被恰当地称为瓶颈层,因为它造成了信息瓶颈。尽管有能力解析无尽的序列,但随着新信息的加入,来自早期步骤的信息会慢慢消退。 The solution to this bottleneck is making all hidden encoder states accessible. In the vanilla setting, the encoder only delivers its last state, which becomes the bottleneck. This approach can be modified to save all intermediate states after the network parsed a new token. As a result, the encoder can store the per-step information and no longer compresses all knowledge into a single vector. 解决这个瓶颈的方法是使所有隐藏的编码器状态都能被访问。在vanilla设置中,编码器只提供其最后的状态,这成为瓶颈。这种方法可以被修改为在网络解析了一个新标记后保存所有的中间状态。因此,编码器可以存储每一步的信息,不再将所有知识压缩到一个单一的向量中。 The encoder saves all hidden states (the vectors after it parsed a new token). We then take the encoder’s current state and compute the dot-product between it and the hidden states. This operation returns a scalar number for each hidden state, which we can represent as a new vector: 编码器保存了所有的隐藏状态(它解析了一个新标记后的向量)。然后,我们取编码器的当前状态,并计算它与隐藏状态之间的点乘。这个操作为每个隐藏状态返回一个标量数字,我们可以将其表示为一个新的向量。 [a, b, c, d, e], where the characters represent the result of the dot product with the corresponding hidden state (e.g., a is the result of the dot product with the first hidden state). The softmax operation is then applied to this vector, yielding the attention weights. These weights express the importance of each hidden state, represented by a probability. In the last step, we multiply the hidden states with their attention score and sum the vectors up. This gives us the context vector for the current state, which is passed to the encoder (not completely right, but fine for this purpose). This process is repeated after each encoder step. 其中的字符代表与相应的隐藏状态的点积结果(例如,a是与第一个隐藏状态的点积结果)。然后对这个向量进行softmax运算,产生注意力权重。这些权重表示每个隐藏状态的重要性,用概率表示。在最后一步,我们将隐藏状态与它们的注意力分数相乘,并将这些向量相加。这样我们就得到了当前状态的上下文向量,并将其传递给编码器(不完全正确,但对这一目的来说很好)。这个过程在每个编码器步骤之后都会重复。 The process can be seen in this animation, taken from [Google’s seq2seq repository](https://github.com/google/seq2seq): 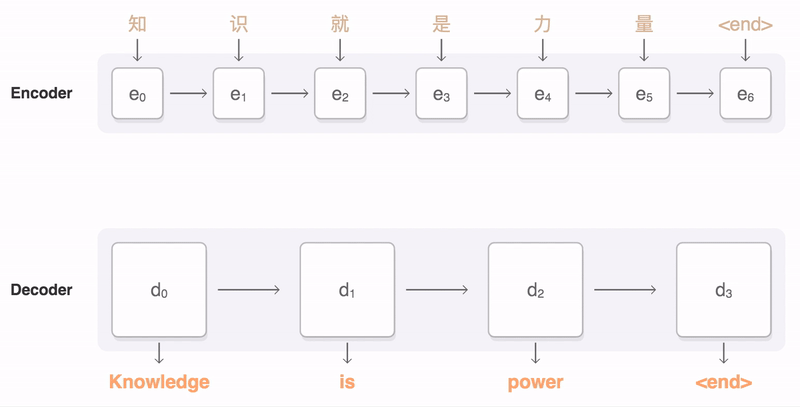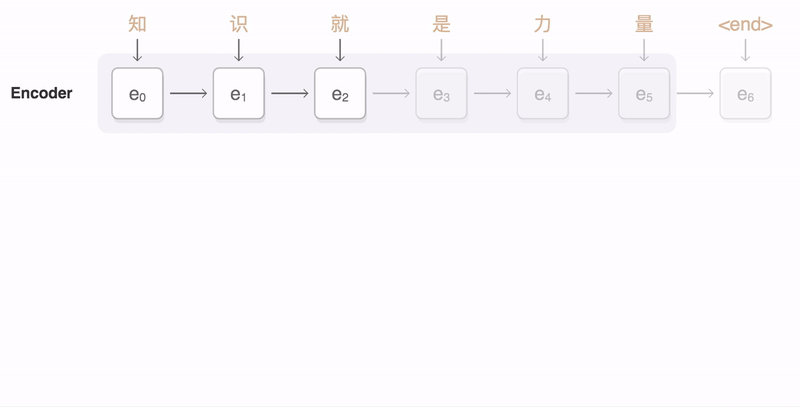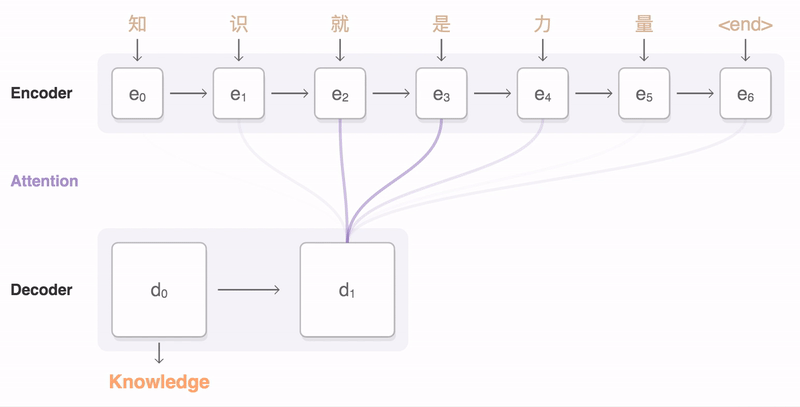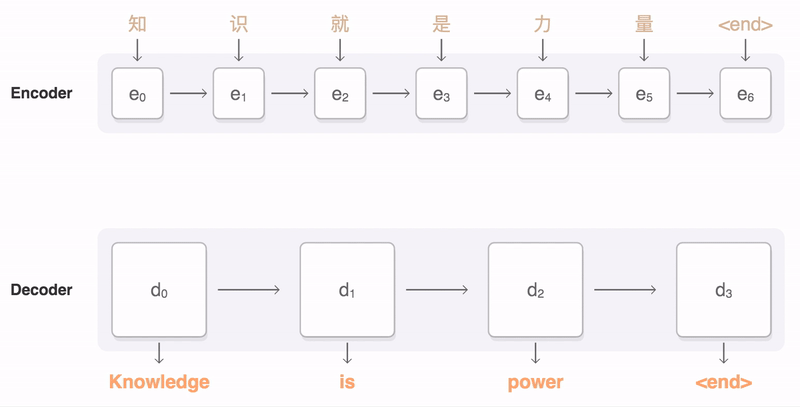 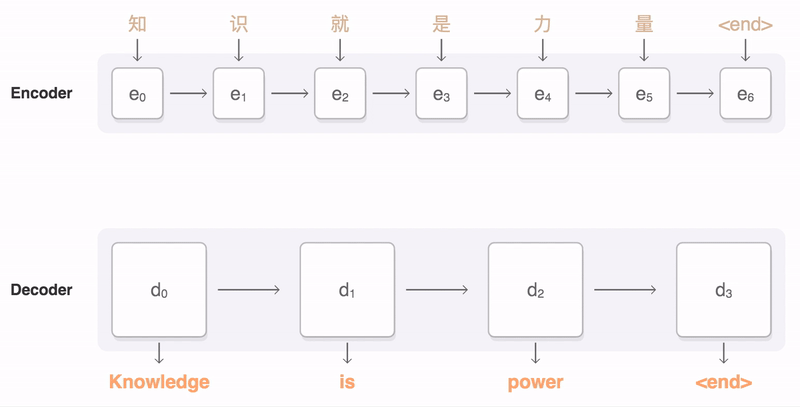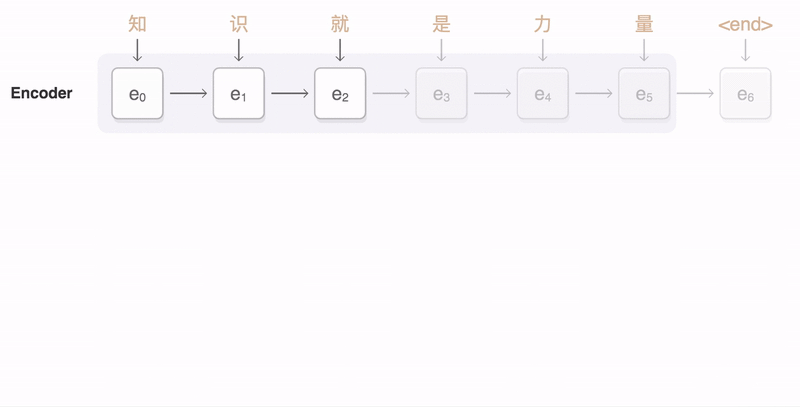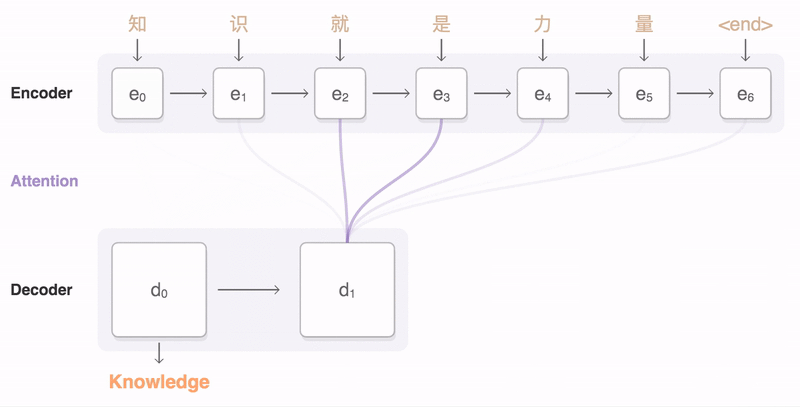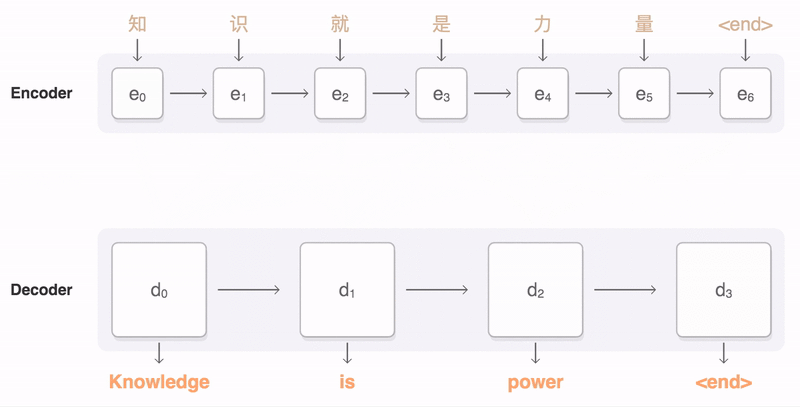 The attention process enables the encoder to store the per-step information and lets the decoder decide which hidden states to pay attention to. These modifications have greatly improved the quality of text translation, as shown in [4]. 注意过程使编码器存储每步信息,并让解码器决定注意哪些隐藏状态。如[4]所示,这些修改大大改善了文本翻译的质量。 A general drawback of recurrent networks in general, and the sequence-to-sequence approach in particular, is the low parallelizability. Recall that the output of step *k+1* depends on step *k*; we thus have to parse all previous steps first. Therefore, we cannot run much in parallel here — except if we change the underlying network architectures. This idea leads us to Transformers. 一般来说,递归网络的一个普遍缺点,特别是序列到序列的方法,是可并行性低。回顾一下,步骤*k+1*的输出取决于步骤*k*;因此我们必须先解析所有先前的步骤。因此,我们不能在这里并行运行很多东西--除非我们改变底层的网络架构。这个想法把我们引向了变压器。 ##### Transformers The Transformer [5] is a neural network architecture that utilizes the attention mechanism. Under the hood, it still uses an encoder-decoder structure but replaces the recurrent networks. Instead, the encoder is modelled by n identical layers with self-attention and regular feed-forward networks. An encoder block uses the same structure and adds another attention layer that takes the encoder’s output. The following figure, taken from [5], shows the described setup: Transformer[5]是一个利用注意力机制的神经网络架构。在引擎盖下,它仍然使用一个编码器-解码器结构,但取代了递归网络。取而代之的是,编码器由n个相同的层来模拟,具有自我注意和常规前馈网络。编码器块使用相同的结构,并增加了另一个注意力层,以获取编码器的输出。下图取自[5],显示了所述的设置: 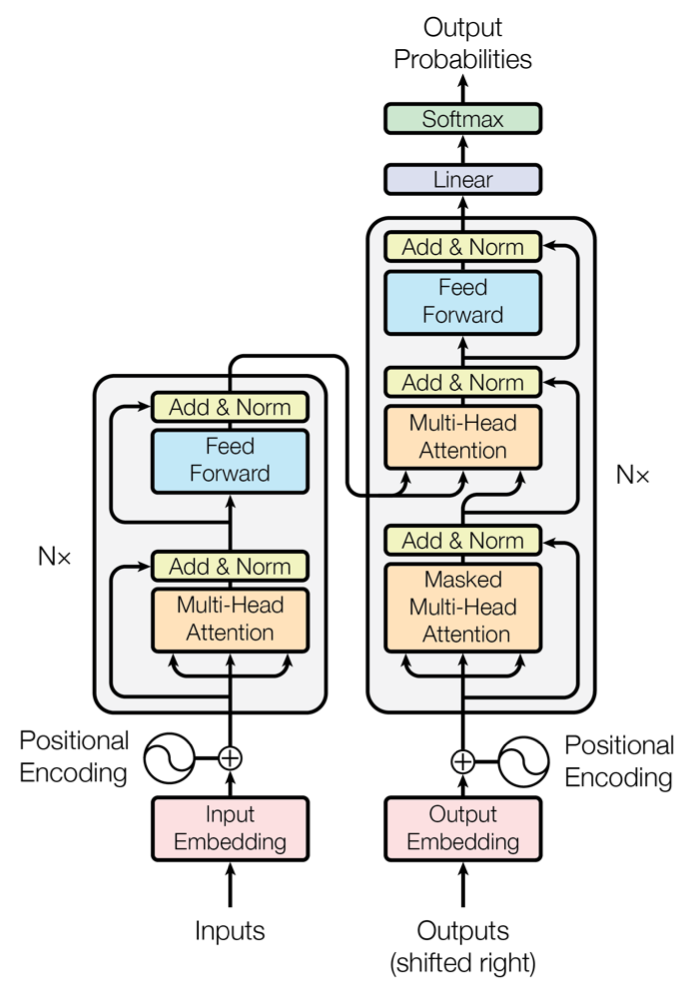 A second improvement is the modification of the attention procedure. In the vanilla sequence-to-sequence approach, the hidden state of the decoder calculates the dot-product with all encoder hidden states. In the improved mechanism, called Multi-Head Self-Attention, these operations are modelled as matrix multiplications. 第二个改进是注意程序的修改。在虚构的序列到序列的方法中,解码器的隐藏状态与所有编码器的隐藏状态进行点乘计算。在改进的机制中,称为多头自我注意,这些操作被模拟为矩阵乘法。 The self-attention transforms the input to an internal representation, a weighted sum of its own timesteps. This approach can capture long-term dependencies within the sequence. The input is converted into three different representations, the *Key*, the *Query*, and the *Value*, to model these relationships. These representations are obtained by multiplying the input with three weights: *Wₖ* (for the Key), *Wᵥ* (Value), and *Wq* (Query). The computation flow is shown in the following figure [5] 自我注意将输入转化为内部表征,即其自身时间步长的加权和。这种方法可以捕捉到序列内的长期依赖性。输入被转换为三种不同的表示,即关键、查询和价值,以模拟这些关系。这些表征是通过将输入与三个权重相乘得到的。Wₖ(关键),Wᵥ(价值)和Wq(查询)。计算流程如下图所示[5] 。 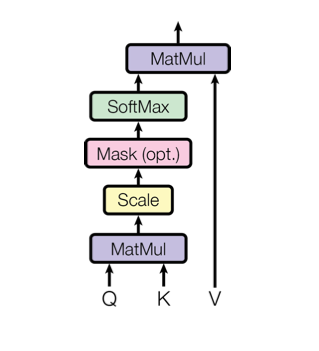 Q and K are matrix-multiplied, scaled, optionally masked, and then softmax-ed. Finally, the result is matrix-multiplied with V. This can mathematically be expressed in the following equation: 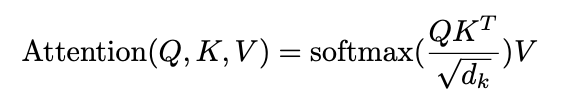 Finally, there are multiple such “flows,” dubbed attention heads. Each head uses a different set of attention weights Wₖ, Wᵥ, and Wq. These weights yield multiple internal representations for the same input. The result of the individual attention heads are then concatenated. ### The Most Useful Writing Advice I’ve Ever Been Given origin: [The Most Useful Writing Advice I’ve Ever Been Given](https://medium.com/creators-hub/the-most-useful-writing-advice-ive-ever-been-given-85ee6ee1c1c7) > No, it’s not ‘show, don’t tell’ ##### **Here are some things that teachers I was lucky enough to have taught me:** **“Just because it happened to you doesn’t make it interesting.”** I often repeat this line to students. From a writer who writes a lot of thinly veiled fiction based on her real life, this piece of advice is key for anyone writing nonfiction to understand. The personal is only interesting if it reaches into the universal. "仅仅因为它发生在你身上并不使它变得有趣。" 我经常向学生重复这句话。作为一个根据自己的真实生活写了很多薄薄的小说的作家,这条建议对任何写非虚构作品的人来说都是关键的。个人的东西只有在涉及到普遍性的时候才是有趣的。 **“Research, research, research (for inspiration as much as anything else).**” I’d always thought of research as an academic, or even scientific, endeavor rather than a creative one. Boy, was I wrong. Fiction writers, poets, and, of course, nonfiction writers can benefit immensely from research. And research can be traveling, walking through your setting to take in the sensory details, or it can be reading old folk tales. I’d always thought, “Okay yeah, you research to make your work more realistic — but you do it to make it more *real*?” You do it because your work deserves that kind of investment on your part, but you also do it for inspiration. The details in Hans Christian Andersen (the codfish as paper in “The Snow Queen”!), the actual turns of phrase an old fisherman uses, the smell of the desert in spring — these are the goldmines of good writing. And you won’t find them unless you look. **If you are bored, it’s not because you wrote it, it’s because it’s boring.** Margot Livesey actually said, “If you are bored, it’s not because you’ve read that section so many times, it’s because it’s boring.” And it’s really true, and countless times it’s saved me from being boring. **“Take out one dull line and add one stunning detail on every page.”** This is from my exquisite writing mentor, Melanie Rae Thon, and is one of the many gems she has given me over the years. It is exquisite advice, and shows the dedication and diligence Thon gives to her own work. It is a really concrete action writers can take to drastically improve their writing. When I take this practice to my own work, it reminds me of adding a coat of oil to dull wood. It just immediately shines it up. It’s also wonderful to ask others to give their writing that kind of attention, and makes writers feel more proud of their work. "在每一页上去掉一个沉闷的线条,增加一个令人惊叹的细节。" 这句话来自我精致的写作导师Melanie Rae Thon,是她多年来给我的众多宝藏之一。这是一个精致的建议,显示了桑对她自己工作的奉献和勤奋。这是一个真正具体的行动,作家可以采取它来大幅改善他们的写作。当我在自己的作品中采用这种做法时,它让我想起了在暗淡的木头上涂抹一层油。它马上就能让它变得更亮。要求别人对自己的写作给予这样的关注也很好,让作家们对自己的作品感到更加自豪。 **“Draw Antonio, draw Antonio, draw and do not waste time.”** In her book, *The Writing Life*, Annie Dillard writes that these are Michelangelo’s words to his apprentice and it’s such an eloquent, history-laden phrase — such a perfect balance between poetry and timelessness — that I’ve tended to use it as a mantra over the years. Whispering it to myself when I’m tired and frustrated. I feel it connects me with artists over time and it reminds me: "画安东尼奥,画安东尼奥,画,不要浪费时间。" 安妮-迪拉德在她的《写作生涯》一书中写道,这是米开朗基罗对他的学徒说的话,这是一个如此雄辩、充满历史感的短语--在诗意和永恒之间的完美平衡--以至于这些年来我倾向于把它作为一个口头禅。在我疲惫和沮丧的时候,我对自己轻声说。我觉得它把我和艺术家们在时间上联系起来,它提醒我。 ## Extracting objects recursively with jq origin: [Extracting objects recursively with jq](https://til.simonwillison.net/jq/extracting-objects-recursively) The Algolia-powered Hacker News API returns nested comment threads that look like this: https://hn.algolia.com/api/v1/items/27941108 ```json { "id": 27941108, "created_at": "2021-07-24T14:15:05.000Z", "type": "story", "author": "edward", "title": "Fun with Unix domain sockets", "url": "https://simonwillison.net/2021/Jul/13/unix-domain-sockets/", "children": [ { "id": 27942287, "created_at": "2021-07-24T16:31:18.000Z", "type": "comment", "author": "DesiLurker", "text": "<p>one lesser known...", "children": [] }, { "id": 27944615, "created_at": "2021-07-24T21:26:33.000Z", "type": "comment", "author": "galaxyLogic", "text": "<p>I read this from Wikipedia...", "children": [ { "id": 27944746, "created_at": "2021-07-24T21:49:07.000Z", "type": "comment", "author": "hughrr", "text": "<p>Yes although I ...", "children": [] } ] } ] } ``` I wanted to flatten this into an array of items so I could send it to sqlite-utils insert. This recipe worked: ```bash curl 'https://hn.algolia.com/api/v1/items/27941108' \ | jq '[recurse(.children[]) | del(.children)]' \ | sqlite-utils insert hn.db items - --pk id ``` The jq recipe here is: [recurse(.children[]) | del(.children)] The first recurse(.children[]) recurses through a list of everything in a .children array. The | del(.children) then deletes that array from the returned objects. Wrapping it all in [ ] ensures the overall result will be an array. Applied against the above example, this returns: ```json [ { "id": 27941108, "created_at": "2021-07-24T14:15:05.000Z", "type": "story", "author": "edward", "title": "Fun with Unix domain sockets", "url": "https://simonwillison.net/2021/Jul/13/unix-domain-sockets/" }, { "id": 27942287, "created_at": "2021-07-24T16:31:18.000Z", "type": "comment", "author": "DesiLurker", "text": "<p>one lesser known..." }, { "id": 27944615, "created_at": "2021-07-24T21:26:33.000Z", "type": "comment", "author": "galaxyLogic", "text": "<p>I read this from Wikipedia..." }, { "id": 27944746, "created_at": "2021-07-24T21:49:07.000Z", "type": "comment", "author": "hughrr", "text": "<p>Yes although I ..." } ] ``` ### 一点收获 - Delegating to your team -- Ed Gandia - First, I’ve started to ask myself: “If I only had two hours a day to do my work, what tasks would I absolutely keep for myself?” - Second, when I come across a task I wish I could delegate, I ask myself the following: Is this something I could delegate: 1. a. Right now? 2. b. In a few weeks, if I found and trained the right person? 3. c. In 90 days or more, if I could figure it all out? In categorizing tasks, I’m not automatically writing them off as hopeless. - Creative Code Management | [tutorial](https://www.bit-101.com/blog/2021/08/creative-code-management/) - Creative coding is a type of computer programming in which the goal is to create something expressive instead of something functional. ```bash git add . git commit -m $1 git tag $1 git push git push --tags ``` - 可以用lastpass-cli储存infra secret.... `lpass ls`