> 2021年12月08日信息消化 ### The Best Memorization Techniques: Learn Faster and Remember More origin: [The Best Memorization Techniques: Learn Faster and Remember More](https://medium.com/dare-to-be-better/the-best-memorization-techniques-learn-faster-and-remember-more-4d568a3f139e) ##### Assign meaning to things you are trying to remember New information is most strongly encoded in your brain when it’s related to something you already know. Use this fact to your advantage. The more logical connections you can make, the stronger the memory will be. ##### Learn general first and specific details later Start by remembering general information first; then, add the specifics. This technique is also very helpful when you are trying to retrieve the information. If you know that a certain piece of information belongs to a broader category, it’s easier to access and remember the specific details. ##### Review and repeat frequently [Spaced-out repetition](https://collegeinfogeek.com/spaced-repetition-memory-technique/#:~:text=Here's the solution%3A space out,to recall what you study.) is a popular technique for better memorization of complex topics. As you’ll see on “the forgetting curve” below, the longer the gap, the more likely the information will remain memorized. 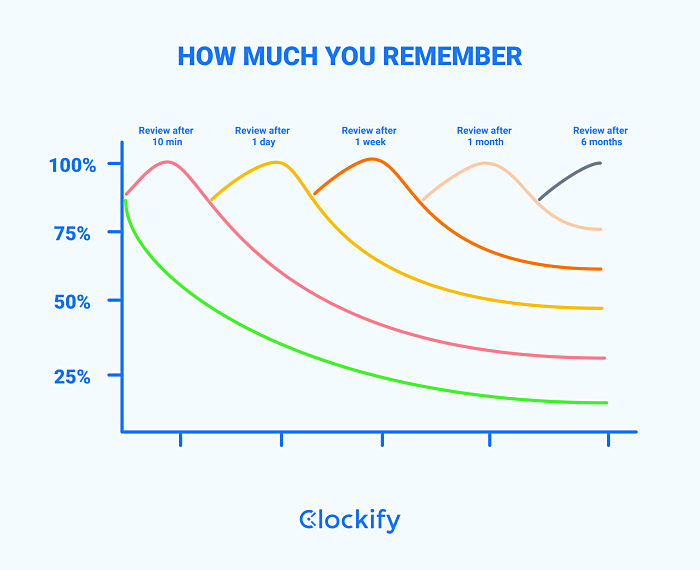 ##### Recite things out loud [Read things you would like to remember out loud](https://qz.com/1144521/you-remember-more-of-what-you-read-out-loud/#:~:text=Speaking aloud works by creating,of Waterloo in Ontario%2C Canada.). Speaking aloud works by creating a “production effect” which helps to retain information in your memory. ##### **Tell it in your own words** Try to repeat what you are trying to remember but using your own words. Keep trying until you don’t need to refer to your notes anymore. ##### Teach someone else Explaining the material to someone is else is an amazing way to learn a new subject. ##### Acrostics/Sentence mnemonics You probably used this technique at school but let’s quickly review how it works. Sentence mnemonics are great for remembering a set of information — the order of planets or the 7 levels of classification of living things. As an example, here is how you would remember the signs of the zodiac… **A**s **T**imes **G**oes, **C**owboys **L**ove **V**iewing **L**ittle **S**tars **S**o **C**ool **A**nd **P**retty. **A**ries **T**aurus **G**emini **C**ancer **L**eo **V**irgo **L**ibra **S**corpio **S**agittarius **C**apricorn **A**quarius **P**isces ##### Chunking If you need to remember a lot of information, try dividing it into smaller chunks. ##### Act it out Do you know how theatre actors can memorize pages of text? Because they are attributing emotions to every scene. Actors need to know why a specific character said what he did and try to show that emotion. Use this technique by approaching every new subject that you are trying to learn as a story. Treat the material as a plotline to a movie, and the people as characters with specific motivations and emotions. ##### **Flashcards** Good old flashcards are great if you need to remember certain facts. Shuffle cards and recite out loud. Write a question on one side, the answer on the other. Keep reviewing your cards until you get all the answers correct. For best results, combine this method with others such as a spaced-out repetition. ### How to build a Serverless API with Go and AWS Lambda origin: https://www.alexedwards.net/blog/serverless-api-with-go-and-aws-lambda 1. [Setting up the AWS CLI](https://www.alexedwards.net/blog/serverless-api-with-go-and-aws-lambda#setup-and-the-aws-cli) 2. [Creating and deploying an Lambda function](https://www.alexedwards.net/blog/serverless-api-with-go-and-aws-lambda#creating-and-deploying-an-lambda-function) 3. [Hooking it up to DynamoDB](https://www.alexedwards.net/blog/serverless-api-with-go-and-aws-lambda#hooking-it-up-to-dynamodb) 4. [Setting up the HTTPS API](https://www.alexedwards.net/blog/serverless-api-with-go-and-aws-lambda#setting-up-the-https-api) 5. [Working with events](https://www.alexedwards.net/blog/serverless-api-with-go-and-aws-lambda#working-with-events) 6. [Deploying the API](https://www.alexedwards.net/blog/serverless-api-with-go-and-aws-lambda#deploying-the-api) 7. [Supporting multiple actions](https://www.alexedwards.net/blog/serverless-api-with-go-and-aws-lambda#supporting-multiple-actions) Throughout this post we'll work towards building an API with two actions: | Method | Path | Action | | :----- | :-------------- | :---------------------------------------------------- | | GET | /books?isbn=xxx | Display information about a book with a specific ISBN | | POST | /books | Create a new book | Where a book is a basic JSON record which looks like this: ```json {"isbn":"978-1420931693","title":"The Republic","author":"Plato"} ``` I'm keeping the API deliberately simple to avoid getting bogged-down in application-specific code, but once you've grasped the basics it's fairly clear how to extend the API to support additional routes and actions. #### Setting up the AWS CLI Throughout this tutorial we'll use the AWS CLI (command line interface) to configure our lambda functions and other AWS services. Installation and basic usage instructions can be [found here](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-welcome.html), but if you’re using a Debian-based system like Ubuntu you can install the CLI with `apt` and run it using the `aws` command: ```bash $ sudo apt install awscli $ aws --version aws-cli/1.11.139 Python/3.6.3 Linux/4.13.0-37-generic botocore/1.6.6 ``` Next we need to set up an AWS IAM user with *programmatic access* permission for the CLI to use. A guide on how to do this can be [found here](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_users_create.html). For testing purposes you can attach the all-powerful `AdministratorAccess` managed policy to this user, but in practice I would recommend using a more restrictive policy. At the end of setting up the user you'll be given a access key ID and secret access key. Make a note of these — you’ll need them in the next step. Configure the CLI to use the credentials of the IAM user you've just created using the `configure` command. You’ll also need to specify the [default region](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Concepts.RegionsAndAvailabilityZones.html) and [output format](https://docs.aws.amazon.com/cli/latest/userguide/controlling-output.html) you want the CLI to use. ```bash $ aws configure AWS Access Key ID [None]: access-key-ID AWS Secret Access Key [None]: secret-access-key Default region name [None]: us-east-1 Default output format [None]: json ``` #### Creating and deploying an Lambda function Now for the exciting part: making a lambda function. If you're following along, go to your `$GOPATH/src` folder and create a `books` repository containing a `main.go` file. ```go $ cd ~/go/src $ mkdir books && cd books $ touch main.go ``` Next you'll need to install the `github.com/aws-lambda-go/lambda` package. This provides the essential libraries and types we need for creating a lambda function in Go. ```go $ go get github.com/aws/aws-lambda-go/lambda ``` Then open up the `main.go` file and add the following code: ```go package main import ( "github.com/aws/aws-lambda-go/lambda" ) type book struct { ISBN string `json:"isbn"` Title string `json:"title"` Author string `json:"author"` } func show() (*book, error) { bk := &book{ ISBN: "978-1420931693", Title: "The Republic", Author: "Plato", } return bk, nil } func main() { lambda.Start(show) } ``` In the `main()` function we call `lambda.Start()` and pass in the `show` function as the lambda *handler*. In this case the handler simply initializes and returns a new `book` object. Lamdba handlers can take a variety of different signatures and reflection is used to determine exactly which signature you're using. The full list of supported forms is… ```go func() func() error func(TIn) error func() (TOut, error) func(TIn) (TOut, error) func(context.Context) error func(context.Context, TIn) error func(context.Context) (TOut, error) func(context.Context, TIn) (TOut, error) ``` … where the `TIn` and `TOut` parameters are objects that can be marshaled (and unmarshalled) by Go's `encoding/json` package. The next step is to build an executable from the `books` package using `go build`. In the code snippet below I'm using the `-o` flag to save the executable to `/tmp/main` but you can save it to any location (and name it whatever) you wish. ```bash $ env GOOS=linux GOARCH=amd64 go build -o /tmp/main books ``` Important: as part of this command we're using `env` to temporarily set two environment variables for the duration for the command (`GOOS=linux` and `GOARCH=amd64`). These instruct the Go compiler to create an executable suitable for use with a linux OS and amd64 architecture — which is what it will be running on when we deploy it to AWS. AWS requires us to upload our lambda functions in a zip file, so let's make a `main.zip` zip file containing the executable we just made: ```bash $ zip -j /tmp/main.zip /tmp/main ``` Note that the executable must be *in the root* of the zip file — not in a folder within the zip file. To ensure this I've used the `-j` flag in the snippet above to junk directory names. The next step is a bit awkward, but critical to getting our lambda function working properly. We need to set up an IAM role which defines the permission that our *lambda function will have when it is running*. For now let's set up a `lambda-books-executor` role and attach the `AWSLambdaBasicExecutionRole` managed policy to it. This will give our lambda function the basic permissions it need to run and log to the AWS cloudwatch service. First we have to create a *trust policy* JSON file. This will essentially instruct AWS to allow lambda services to assume the `lambda-books-executor` role: ```json { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } ``` Then use the `aws iam create-role` command to create the role with this trust policy: ```bash $ aws iam create-role --role-name lambda-books-executor \ --assume-role-policy-document file:///tmp/trust-policy.json { "Role": { "Path": "/", "RoleName": "lambda-books-executor", "RoleId": "AROAIWSQS2RVEWIMIHOR2", "Arn": "arn:aws:iam::account-id:role/lambda-books-executor", "CreateDate": "2018-04-05T10:22:32.567Z", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } } } ``` Make a note of the returned ARN (Amazon Resource Name) — you'll need this in the next step. Now the `lambda-books-executor` role has been created we need to specify the permissions that the role has. The easiest way to do this it to use the `aws iam attach-role-policy` command, passing in the ARN of `AWSLambdaBasicExecutionRole` permission policy like so: ```bash $ aws lambda invoke --function-name books /tmp/output.json { "StatusCode": 200 } $ cat /tmp/output.json {"isbn":"978-1420931693","title":"The Republic","author":"Plato"} ``` If you're following along hopefully you've got the same response. Notice how the `book` object we initialized in our Go code has been automatically marshaled to JSON? #### Hooking it up to DynamoDB In this section we're going to add a persistence layer for our data which can be accessed by our lambda function. For this I'll use Amazon DynamoDB (it integrates nicely with AWS lambda and has a generous free-usage tier). If you're not familiar with DynamoDB, there's a decent run down of [the basics here](https://www.tutorialspoint.com/dynamodb/dynamodb_overview.htm). The first thing we need to do is create a `Books` table to hold the book records. DynanmoDB is schema-less, but we do need to define the partion key (a bit like a primary key) on the ISBN field. We can do this in one command like so: ```shell $ aws dynamodb create-table --table-name Books \ --attribute-definitions AttributeName=ISBN,AttributeType=S \ --key-schema AttributeName=ISBN,KeyType=HASH \ --provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5 { "TableDescription": { "AttributeDefinitions": [ { "AttributeName": "ISBN", "AttributeType": "S" } ], "TableName": "Books", "KeySchema": [ { "AttributeName": "ISBN", "KeyType": "HASH" } ], "TableStatus": "CREATING", "CreationDateTime": 1522924177.507, "ProvisionedThroughput": { "NumberOfDecreasesToday": 0, "ReadCapacityUnits": 5, "WriteCapacityUnits": 5 }, "TableSizeBytes": 0, "ItemCount": 0, "TableArn": "arn:aws:dynamodb:us-east-1:account-id:table/Books" } } ``` Then lets add a couple of items using the `put-item` command, which we'll use in the next steps. ```shell $ aws dynamodb put-item --table-name Books --item '{"ISBN": {"S": "978-1420931693"}, "Title": {"S": "The Republic"}, "Author": {"S": "Plato"}}' $ aws dynamodb put-item --table-name Books --item '{"ISBN": {"S": "978-0486298238"}, "Title": {"S": "Meditations"}, "Author": {"S": "Marcus Aurelius"}}' ``` The next thing to do is update our Go code so that our lambda handler can connect to and use the DynamoDB layer. For this you'll need to install the `github.com/aws/aws-sdk-go` package which provides libraries for working with DynamoDB (and other AWS services). ```shell $ go get github.com/aws/aws-sdk-go ``` Now for the code. To keep a bit of separation create a new `db.go` file in your `books` repository: ```shell $ touch ~/go/src/books/db.go ``` And add the following code: ```go package main import ( "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" ) // Declare a new DynamoDB instance. Note that this is safe for concurrent // use. var db = dynamodb.New(session.New(), aws.NewConfig().WithRegion("us-east-1")) func getItem(isbn string) (*book, error) { // Prepare the input for the query. input := &dynamodb.GetItemInput{ TableName: aws.String("Books"), Key: map[string]*dynamodb.AttributeValue{ "ISBN": { S: aws.String(isbn), }, }, } // Retrieve the item from DynamoDB. If no matching item is found // return nil. result, err := db.GetItem(input) if err != nil { return nil, err } if result.Item == nil { return nil, nil } // The result.Item object returned has the underlying type // map[string]*AttributeValue. We can use the UnmarshalMap helper // to parse this straight into the fields of a struct. Note: // UnmarshalListOfMaps also exists if you are working with multiple // items. bk := new(book) err = dynamodbattribute.UnmarshalMap(result.Item, bk) if err != nil { return nil, err } return bk, nil } ``` And then update the `main.go` to use this new code: ```go package main import ( "github.com/aws/aws-lambda-go/lambda" ) type book struct { ISBN string `json:"isbn"` Title string `json:"title"` Author string `json:"author"` } func show() (*book, error) { // Fetch a specific book record from the DynamoDB database. We'll // make this more dynamic in the next section. bk, err := getItem("978-0486298238") if err != nil { return nil, err } return bk, nil } func main() { lambda.Start(show) } ``` Save the files, then rebuild and zip up the lambda function so it's ready to deploy: ```shell $ env GOOS=linux GOARCH=amd64 go build -o /tmp/main books $ zip -j /tmp/main.zip /tmp/main ``` Re-deploying a lambda function is easier than creating it for the first time — we can use the `aws lambda update-function-code` command like so: ```shell $ aws lambda update-function-code --function-name books \ --zip-file fileb:///tmp/main.zip ``` Let's try executing the lambda function now: ```shell $ aws lambda invoke --function-name books /tmp/output.json { "StatusCode": 200, "FunctionError": "Unhandled" } $ cat /tmp/output.json {"errorMessage":"AccessDeniedException: User: arn:aws:sts::account-id:assumed-role/lambda-books-executor/books is not authorized to perform: dynamodb:GetItem on resource: arn:aws:dynamodb:us-east-1:account-id:table/Books\n\tstatus code: 400, request id: 2QSB5UUST6F0R3UDSVVVODTES3VV4KQNSO5AEMVJF66Q9ASUAAJG","errorType":"requestError"} ``` Ah. There's a slight problem. We can see from the output message that our lambda function (specifically, the `lambda-books-executor` role) doesn't have the necessary permissions to run `GetItem` on a DynamoDB instance. Let's fix that now. Create a privilege policy file that gives `GetItem` and `PutItem` privileges on DynamoDB like so: ```json { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "dynamodb:PutItem", "dynamodb:GetItem" ], "Resource": "*" } ] } ``` And then attach it to the `lambda-books-executor` role using the `aws iam put-role-policy` command: ```shell $ aws iam put-role-policy --role-name lambda-books-executor \ --policy-name dynamodb-item-crud-role \ --policy-document file:///tmp/privilege-policy.json ``` As a side note, AWS has some managed policies called `AWSLambdaDynamoDBExecutionRole` and `AWSLambdaInvocation-DynamoDB` which sound like they would do the trick. But neither of them actually provide `GetItem` or `PutItem` privileges. Hence the need to roll our own policy. Let's try executing the lambda function again. It should work smoothly this time and return information about the book with ISBN `978-0486298238` ```shell $ aws lambda invoke --function-name books /tmp/output.json { "StatusCode": 200 } $ cat /tmp/output.json {"isbn":"978-0486298238","title":"Meditations","author":"Marcus Aurelius"} ``` #### Setting up the HTTPS API So our lambda function is now working nicely and communicating with DynamoDB. The next thing to do is set up a way to access the lamdba function over HTTPS, which we can do using the AWS API Gateway service. But before we go any further, it's worth taking a moment to think about the structure of our project. Let's say we have grand plans for our lamdba function to be part of a bigger `bookstore` API which deals with information about books, customers, recommendations and other things. There's three basic options for structuring this using AWS Lambda: - **Microservice style** — Each lambda function is responsible for one action only. For example, there are 3 separate lambda functions for showing, creating and deleting a book. - **Service style** — Each lambda function is responsible for a group of related actions. For example, one lambda function handles all book-related actions, but customer-related actions are kept in a separate lambda function. - **Monolith style** — One lambda function manages all the bookstore actions. Each of these options is valid, and theres some good discussion of the pros and cons [here](https://serverless.com/blog/serverless-architecture-code-patterns/). For this tutorial we'll opt for a service style, and have one `books` lambda function handle the different book-related actions. This means that we'll need to implement some form of routing *within* our lambda function, which I'll cover later in the post. But for now… Go ahead and create a `bookstore` API using the `aws apigateway create-rest-api` command like so: ```shell $ aws apigateway create-rest-api --name bookstore { "id": "rest-api-id", "name": "bookstore", "createdDate": 1522926250 } ``` Note down the `rest-api-id` value that this returns, we'll be using it a lot in the next few steps. Next we need to get the id of the root API resource (`"/"`). We can retrieve this using the `aws apigateway get-resources` command like so: ```shell $ aws apigateway get-resources --rest-api-id rest-api-id { "items": [ { "id": "root-path-id", "path": "/" } ] } ``` Again, keep a note of the `root-path-id` value this returns. Now we need to create a new resource *under the root path* — specifically a resource for the URL path `/books`. We can do this by using the `aws apigateway create-resource` command with the `--path-part` parameter like so: ```shell $ aws apigateway create-resource --rest-api-id rest-api-id \ --parent-id root-path-id --path-part books { "id": "resource-id", "parentId": "root-path-id", "pathPart": "books", "path": "/books" } ``` Again, note the `resource-id` this returns, we'll need it in the next step. Note that it's possible to include placeholders within your path by wrapping part of the path in curly braces. For example, a `--path-part` parameter of `books/{id}` would match requests to `/books/foo` and `/books/bar`, and the value of `id` would be made available to your lambda function via an events object (which we'll cover later in the post). You can also make a placeholder greedy by postfixing it with a `+`. A common idiom is to use the parameter `--path-part {proxy+}` if you want to match all requests regardless of their path. But we're not doing either of those things. Let's get back to our `/books` resource and use the `aws apigateway put-method` command to register the HTTP method of `ANY`. This will mean that our `/books` resource will respond to all requests regardless of their HTTP method. ```shell $ aws apigateway put-method --rest-api-id rest-api-id \ --resource-id resource-id --http-method ANY \ --authorization-type NONE { "httpMethod": "ANY", "authorizationType": "NONE", "apiKeyRequired": false } ``` Now we're all set to integrate the resource with our lambda function, which we can do using the `aws apigateway put-integration` command. This command has a few parameters that need a quick explanation: - The `--type` parameter should be `AWS_PROXY`. When this is used the AWS API Gateway will send information about the HTTP request as an 'event' to the lambda function. It will also automatically transform the output from the lambda function to a HTTP response. - The `--integration-http-method` parameter must be `POST`. Don't confuse this with what HTTP methods your API resource responds to. - The `--uri` parameter needs to take the format: ```shell arn:aws:apigateway:us-east-1:lambda:path/2015-03-31/functions/your-lambda-function-arn/invocations ``` With those things in mind, your command should look a bit like this: ```shell $ aws apigateway put-integration --rest-api-id rest-api-id \ --resource-id resource-id --http-method ANY --type AWS_PROXY \ --integration-http-method POST \ --uri arn:aws:apigateway:us-east-1:lambda:path/2015-03-31/functions/arn:aws:lambda:us-east-1:account-id:function:books/invocations { "type": "AWS_PROXY", "httpMethod": "POST", "uri": "arn:aws:apigateway:us-east-1:lambda:path/2015-03-31/functions/arn:aws:lambda:us-east-1:account-id:function:books/invocations", "passthroughBehavior": "WHEN_NO_MATCH", "cacheNamespace": "qtdn5h", "cacheKeyParameters": [] } ``` Alright, let's give this a whirl. We can send a test request to the resource we just made using the `aws apigateway test-invoke-method` command like so: ```shell $ aws lambda add-permission --function-name books --statement-id a-GUID \ --action lambda:InvokeFunction --principal apigateway.amazonaws.com \ --source-arn arn:aws:execute-api:us-east-1:account-id:rest-api-id/*/*/* { "Statement": "{\"Sid\":\"6d658ce7-3899-4de2-bfd4-fefb939f731\",\"Effect\":\"Allow\",\"Principal\":{\"Service\":\"apigateway.amazonaws.com\"},\"Action\":\"lambda:InvokeFunction\",\"Resource\":\"arn:aws:lambda:us-east-1:account-id:function:books\",\"Condition\":{\"ArnLike\":{\"AWS:SourceArn\":\"arn:aws:execute-api:us-east-1:account-id:rest-api-id/*/*/*\"}}}" } $ aws apigateway test-invoke-method --rest-api-id rest-api-id --resource-id resource-id --http-method "GET" { "status": 500, "body": "{\"message\": \"Internal server error\"}", "headers": {}, "log": "Execution log for request test-request\nThu Apr 05 11:07:54 UTC 2018 : Starting execution for request: test-invoke-request\nThu Apr 05 11:07:54 UTC 2018 : HTTP Method: GET, Resource Path: /books\nThu Apr 05 11:07:54 UTC 2018 : Method request path: {}[TRUNCATED]Thu Apr 05 11:07:54 UTC 2018 : Sending request to https://lambda.us-east-1.amazonaws.com/2015-03-31/functions/arn:aws:lambda:us-east-1:account-id:function:books/invocations\nThu Apr 05 11:07:54 UTC 2018 : Execution failed due to configuration error: Invalid permissions on Lambda function\nThu Apr 05 11:07:54 UTC 2018 : Method completed with status: 500\n", "latency": 39 } ``` ### Misc - v2ex | [挖矿的意义在哪?](https://www.v2ex.com/t/820628) - 共识的力量是强大的,它甚至可以让一克拉的碳卖出六万块··· - v2ex | [邪恶的算法,有多少责任在程序员?](https://www.v2ex.com/t/820521) - 这叫社会原子化。就是那句名言:雪崩中,没有一片雪花觉得自己有责任 现在执行死刑也用这个原理,整个过程分几个步骤,每个步骤分不同人去执行,关键步骤同时让几个人去执行 高度分工之后,能让人的罪恶感大大降低,每一个人都能安慰自己说不是自己杀的人 - [How to make your VSCode ????????????????????????](https://www.youtube.com/watch?v=PWCkrHHyvjE) : Setting > Editor > Cursor