> 2021年12月13日信息消化 ### Go Context Tutorial origin: [Go Context Tutorial](https://tutorialedge.net/golang/go-context-tutorial/) #### Contexts Overview I like to imagine contexts almost like **a parcel of information** that is sent **between the various layers** of your application. Your parcel is created at the edge of your application - typically when a new API request comes in. This parcel will then be delivered to your service layer and onto your storage layer. This parcel starts off containing a few important pieces of functionality at first which are: - **The ability to store additional information** that can be passed down the chain. - **The ability to control cancellation** - you can create parcels that act as ticking time bombs that can stop the execution of your code if they exceed either a specific deadline or timeout value. #### Context With Value ```go package main import ( "context" "fmt" ) func enrichContext(ctx context.Context) context.Context { return context.WithValue(ctx, "api-key", "my-super-secret-api-key") } func doSomethingCool(ctx context.Context) { apiKey := ctx.Value("api-key") fmt.Println(apiKey) } func main() { fmt.Println("Go Context Tutorial") ctx := context.Background() ctx = enrichContext(ctx) doSomethingCool(ctx) } ``` In this example, we’ve started off by creating a new `ctx` object using the `context` package and the `.Background` function that returns a non-nil, empty Context. Adding Values to Our Context: `context.WithValue(ctx, "api-key", "my-super-secret-api-key")` > *Note* - It’s important to note that the `WithValue` function returns a ***copy*** of the existing context and doesn’t modify the original context. Reading Values from our Context: `apiKey := ctx.Value("api-key")` If you are retrieving values from your `ctx`, it’s good to note that when you try and access a key/value pair from the ctx object that doesn’t exist, it will simply return `nil`. If you need a value from a context, you may want to check, for example, `if apiKey != nil` and then return with an error if the key you need is not set. ##### Bad Practices - Using Contexts For Everything It should be noted that whilst you can certainly use contexts to pass information between the layers of your application, you absolutely need to use this only for things that truly need to be propagated through. You shouldn’t use contexts as a bucket for all of your information. It’s a supplementary object that you can store things like `request IDs` for example or `trace IDs` which can then be used for logging and tracing purposes. ##### Context Deadlines using WithTimeout In some high-performance systems, you may need to return a response within a deadline. In a previous company I’ve worked at, we had roughly 2 seconds to return a response within our system or the action taking place would fail. The `context.Context` struct contains some of the functionality that we need in order to control how our system behaves when our system exceeds a deadline. ```go package main import ( "context" "fmt" "time" ) func doSomethingCool(ctx context.Context) { for { select { case <-ctx.Done(): fmt.Println("timed out") err := ctx.Err() fmt.Println(err) return default: fmt.Println("doing something cool") } time.Sleep(500 * time.Millisecond) } } func main() { fmt.Println("Go Context Tutorial") ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second) defer cancel() go doSomethingCool(ctx) select { case <-ctx.Done(): fmt.Println("oh no, I've exceeded the deadline") } time.Sleep(2 * time.Second) } ``` > *Go Playground Link* - https://go.dev/play/p/tB2CRK-lvcW Creating a Context WithTimeout: `ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)` We’ve then gone to start a goroutine that we want to stop if it exceeds the 2 second timeout period that we’ve imposed. We have then deferred the call to `cancel()` and kicked off the goroutine that we want to timeout if our deadline is exceeded. Within the `doSomethingCool` function, you’ll notice we have a `for` loop that is simulating a long running process. Within this, we are constantly checking to see if the Done channel within the parent context object has been closed due to timeout, and if it hasn’t we continue to print `doing something cool` every half-second before the timeout is exceeded. The `context` object also features `Err()` which can be useful for when you need to return the error that caused your fucntion to halt. Whenever you call this `Err()` function, it’s going to return `nil` if Done is not yet closed. If Done is closed, then Err is going to return the error explaining why it was closed. ### [What software engineers should know about search (2017)](https://scribe.rip/p/what-every-software-engineer-should-know-about-search-27d1df99f80d) > MEMO > Algoria / ElasticSearch ##### Want to build or improve a search experience? Start here. Ask a software engineer: “[How would you add search functionality to your product?](https://stackoverflow.com/questions/34314/how-do-i-implement-search-functionality-in-a-website)” or “[How do I build a search engine?](https://www.quora.com/How-to-build-a-search-engine-from-scratch)” You’ll probably immediately hear back something like: “Oh, we’d just launch an ElasticSearch cluster. Search is easy these days.” But is it? Numerous current products [still](https://github.com/isaacs/github/issues/908) [have](https://www.reddit.com/r/Windows10/comments/4jbxgo/can_we_talk_about_how_bad_windows_10_search_sucks/d365mce/) [suboptimal](https://www.reddit.com/r/spotify/comments/2apwpd/the_search_function_sucks_let_me_explain/) [search](https://medium.com/@RohitPaulK/github-issues-suck-723a5b80a1a3#.yp8ui3g9i) [experiences](https://thenextweb.com/opinion/2016/01/11/netflix-search-sucks-flixed-fixes-it/). Any true search expert will tell you that few engineers have a very deep understanding of how search engines work, knowledge that’s often needed to improve search quality. Even though many open source software packages exist, and the research is vast, the knowledge around building solid search experiences is limited to a select few. Ironically, [searching online](https://www.google.com/search?q=building+a+search+engine) for search-related expertise doesn’t yield any recent, thoughtful overviews. ##### Why read this? I’ll point at some of the most popular approaches, algorithms, techniques, and tools, based on my work on general purpose and niche search experiences of varying sizes at Google, Airbnb and several startups. ❗️Not appreciating or understanding the scope and complexity of search problems can lead to bad user experiences, wasted engineering effort, and product failure. If you’re impatient or already know a lot of this, you might find it useful to jump ahead to the **tools and services** sections. ##### Some philosophy This is a long read. But most of what we cover has four underlying principles: ###### ???? Search is an inherently messy problem: - Queries are highly variable. The search problems are **highly variable** based on product needs. - Think about how different Facebook search (searching a graph of people). - YouTube search (searching individual videos). - Or how different both of those are are from Kayak ([air travel planning is a really hairy problem](http://www.demarcken.org/carl/papers/ITA-software-travel-complexity/ITA-software-travel-complexity.pdf)). - Google Maps (making sense of geo-spacial data). - Pinterest (pictures of a brunch you might cook one day). ###### Quality, metrics, and processes matter a lot: - There is no magic bullet (like PageRank) nor a magic ranking formula that makes for a good approach. Processes are always evolving collection of techniques and processes that solve aspects of the problem and improve overall experience, usually **gradually** and **continuously**. - ❗️In other words, search is not just just about building software that does **ranking** or **retrieval** (which we will discuss below) for a specific domain. Search systems are usually an evolving pipeline of components that are tuned and evolve over time and that build up to a cohesive experience. - In particular, the key to success in search is building processes for evaluation and tuning into the product and development cycles. A search system architect should **think about processes and metrics, not just technologies.** ###### Use existing technologies first: - As in most engineering problems, don’t reinvent the wheel yourself. When possible, use existing services or open source tools. If an existing SaaS (such as [Algolia](https://www.algolia.com/) or managed Elasticsearch) fits your constraints and you can afford to pay for it, use it. This solution will likely will be the best choice for your product at first, even if down the road you need to customize, enhance, or replace it. - **❗️Even if you buy, know the details:** - Even if you are using an existing open source or commercial solution, you should have some sense of the complexity of the search problem and where there are likely to be pitfalls. ##### Theory: the search problem Search is different for every product, and choices depend on many technical details of the requirements. It helps to identify the key parameters of your search problem: 1. **Size:** How big is the corpus (a complete set of documents that need to be searched)? Is it thousands or billions of documents? 2. **Media:** Are you searching through text, images, graphical relationships, or geospatial data? 3. ???? C**orpus control and quality:** Are the sources for the documents under your control, or coming from a (potentially adversarial) third party? Are all the documents ready to be indexed or need to be cleaned up and selected? 4. **Indexing speed:** Do you need real-time indexing, or is building indices in batch is fine? 5. **Query language:** Are the queries structured, or you need to support unstructured ones? 6. **Query structure**: Are your queries textual, images, sounds? Street addresses, record ids, people’s faces? 7. **Context-dependence**: Do the results depend on who the user is, what is their history with the product, their geographical location, time of the day etc? 8. **Suggest support**: Do you need to support incomplete queries? 9. **Latency:** What are the serving latency requirements? 100 milliseconds or 100 seconds? 10. **Access control:** Is it entirely public or should users only see a restricted subset of the documents? 11. **Compliance:** Are there compliance or organizational limitations? 12. **Internationalization:** Do you need to support documents with multilingual character sets or Unicode? (Hint: Always use **UTF-8** unless you really know what you’re doing.) Do you need to support a multilingual corpus? Multilingual queries? ##### Theory: the search pipeline Now let’s go through a list of search sub-problems. These are usually solved by separate subsystems that form a pipeline. What that means is that a given subsystem consumes the output of previous subsystems, and produces input for the following subsystems. ##### ???? So… How do I PRACTICALLY build it? This blogpost is not meant as a tutorial, but here is a brief outline of how I’d approach building a search experience right now: 1. As was said above, if you can afford it — just buy the existing SaaS (some good ones are listed below). An existing service fits if: - Your experience is a “connected” one (your service or app has internet connection). - Does it support all the functionality you need out of box? This post gives a pretty good idea of what functions would you want. To name a few, I’d at least consider: support for the media you are searching; real-time indexing support; query flexibility, including context-dependent queries. - Given the size of the corpus and the expected [QpS](https://en.wikipedia.org/wiki/Queries_per_second), can you afford to pay for it for the next 12 months? - Can the service support your expected traffic within the required latency limits? In case when you are querying the service from an app, make sure that the given service is accessible quickly enough from where your users are. 2. If a hosted solution does not fit your needs or resources, you probably want to use one of the open source libraries or tools. In case of connected apps or websites, I’d choose ElasticSearch right now. For embedded experiences, there are multiple tools below. 3. You most likely want to do index selection and clean up your documents (say extract relevant text from HTML pages) before uploading them to the search index. This will decrease the index size and make getting to good results easier. If your corpus fits on a single machine, just write a script (or several) to do that. If not, I’d use [Spark](https://spark.apache.org/). ##### ☁️ SaaS ☁️ ????**[Algolia ](https://www.algolia.com/)**— a proprietary SaaS that indexes a client’s website and provides an API to search the website’s pages. They also have an API to submit your own documents, support context dependent searches and serve results really fast. If I were building a web search experience right now and could afford it, I’d probably use Algolia first — and buy myself time to build a comparable search experience. - Various ElasticSearch providers: AWS (☁️ **[ElasticSearch Cloud](https://aws.amazon.com/elasticsearch-service/)**[)](https://aws.amazon.com/elasticsearch-service/), ☁️**[elastic.co](https://www.elastic.co/)** and from ☁️ **[Qbox](https://qbox.io/)**. - ☁️**[ Azure Search](https://azure.microsoft.com/en-us/services/search/)** — a SaaS solution from Microsoft. Accessible through a REST API, it can scale to billions of documents. Has a Lucene query interface to simplify migrations from Lucene-based solutions. - ☁️[ ](https://swiftype.com/)**[Swiftype](https://swiftype.com/)** — an enterprise SaaS that indexes your company’s internal services, like Salesforce, G Suite, Dropbox and the intranet site. ##### Tools and libraries ????☕???? **[Lucene](https://lucene.apache.org/)** is the most popular IR library. Implements query analysis, index retrieval and ranking. Either of the components can be replaced by an alternative implementation. There is also a C port — ????Luc[y.](https://lucy.apache.org/) - ????☕???? **[Solr](http://lucene.apache.org/solr/)** is a complete search server, based on Lucene. It’s a part of the [Hadoop](http://hadoop.apache.org/) ecosystem of tools. - **????☕????** **[Hadoop](http://hadoop.apache.org/)** is the most widely used open source MapReduce system, originally designed as a indexing pipeline framework for Solr. It has been gradually loosing ground to ????**[Spark](http://spark.apache.org/)** as the batch data processing framework used for indexing. ☁️EMR is a proprietary implementation of MapReduce on AWS. - ????☕???? **[ElasticSearch](https://www.elastic.co/products/elasticsearch)** is also based on Lucene ([feature comparison with Solr).](http://solr-vs-elasticsearch.com/) It has been getting more attention lately, so much that a lot of people think of ES when they hear “search”, and for good reasons: it’s well supported, has [extensive API, ](https://www.elastic.co/guide/en/elasticsearch/reference/current/docs.html)[integrates with Hadoop a](https://github.com/elastic/elasticsearch-hadoop)nd [scales well. ](https://www.elastic.co/guide/en/elasticsearch/guide/current/distributed-cluster.html)There are open source and [Enterprise v](https://www.elastic.co/cloud/enterprise)ersions. ES is also available as a SaaS on Can scale to billions of documents, but scaling to that point can be very challenging, so typical scenario would involve orders of magnitude smaller corpus. - ???????? **[Xapian —](https://xapian.org/)** a C++-based IR library. Relatively compact, so good for embedding into desktop or mobile applications. - ???????? **[Sphinx —](http://sphinxsearch.com/)** an full-text search server. Has a SQL-like query language. Can also act as a st[orage engine for MySQL o](https://mariadb.com/kb/en/mariadb/sphinx-storage-engine/)r used as a library. - ????☕ **[Nutch ](https://nutch.apache.org/)**— a web crawler. Can be used in conjunction with Solr. It’s also the tool behind ????[Common Crawl.](http://commoncrawl.org/) - ???????? **[Lunr —](https://lunrjs.com/)** a compact embedded search library for web apps on the client-side. - ???????? **[searchkit —](https://github.com/searchkit/searchkit)** a library of web UI components to use with ElasticSearch. - ???????? **[Norch —](https://github.com/fergiemcdowall/norch)** a [LevelDB](https://github.com/google/leveldb)-based search engine library for Node.js. - ???????? **[Whoosh —](https://bitbucket.org/mchaput/whoosh/wiki/Home)** a fast, full-featured search library implemented in pure Python. - OpenStreetMaps has it’s own ????[deck of search software.](http://wiki.openstreetmap.org/wiki/Search_engines) ##### Datasets A few fun or useful data sets to try building a search engine or evaluating search engine quality: - ???????? **[Commoncrawl —](http://commoncrawl.org/)** a regularly-updated open web crawl data. There is a [mirror on AWS, ](https://aws.amazon.com/public-datasets/common-crawl/)accessible for free within the service. - ???????? **[Openstreetmap data dump](http://wiki.openstreetmap.org/wiki/Downloading_data)** is a very rich source of data for someone building a geospacial search engine. - ???? **[Google Books N-grams ](http://commondatastorage.googleapis.com/books/syntactic-ngrams/index.html)**can be very useful for building language models. - ???? **[Wikipedia dumps ](https://dumps.wikimedia.org/)**are a classic source to build, among other things, an entity graph out of. There is a [wide range of helper tools ](https://www.mediawiki.org/wiki/Alternative_parsers)available. - **[IMDb dumps](http://www.imdb.com/interfaces)** are a fun dataset to build a small toy search engine for. ### Defensive CSS origin: [Defensive CSS](https://ishadeed.com/article/defensive-css/) > MEMO > > 感谢,瞬间解决了flex下sticky的问题....`align-self: start; position: sticky;` ```css /* Prevent An Image From Being Stretched Or Compressed*/ .image { object-fit: cover; } /* Lock Scroll Chaining*/ .modal__content { overscroll-behavior-y: contain; overflow-y: auto; } /* CSS Variable Fallback: var(--name) -> var(--name, default) */ .message__bubble { max-width: calc(100% - var(--actions-width, 70px)); } /* Using Justify-Content: Space-Between */ .wrapper { display: flex; flex-wrap: wrap; justify-content: space-between; } /* Scrollbar Gutter */ /* when the content gets longer, adding a scrollbar will cause a layout shift: Reserve the scrollbar space */ .element { scrollbar-gutter: stable; } ``` ```css .wrapper { display: grid; grid-template-columns: repeat(auto-fit, minmax(250px, 1fr)); grid-gap: 1rem; } ``` 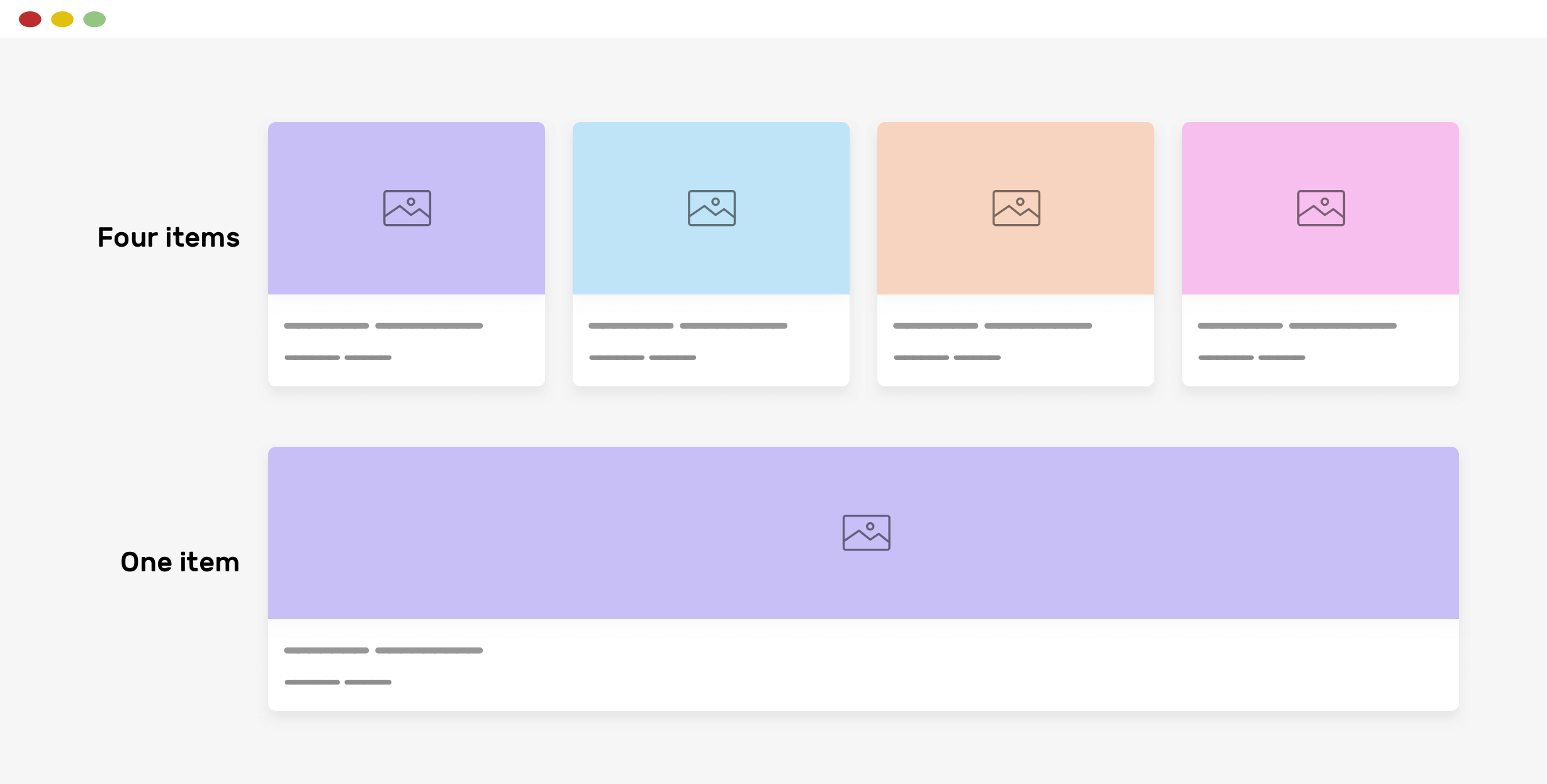 ```css .wrapper { display: grid; grid-template-columns: repeat(auto-fill, minmax(250px, 1fr)); grid-gap: 1rem; } ``` 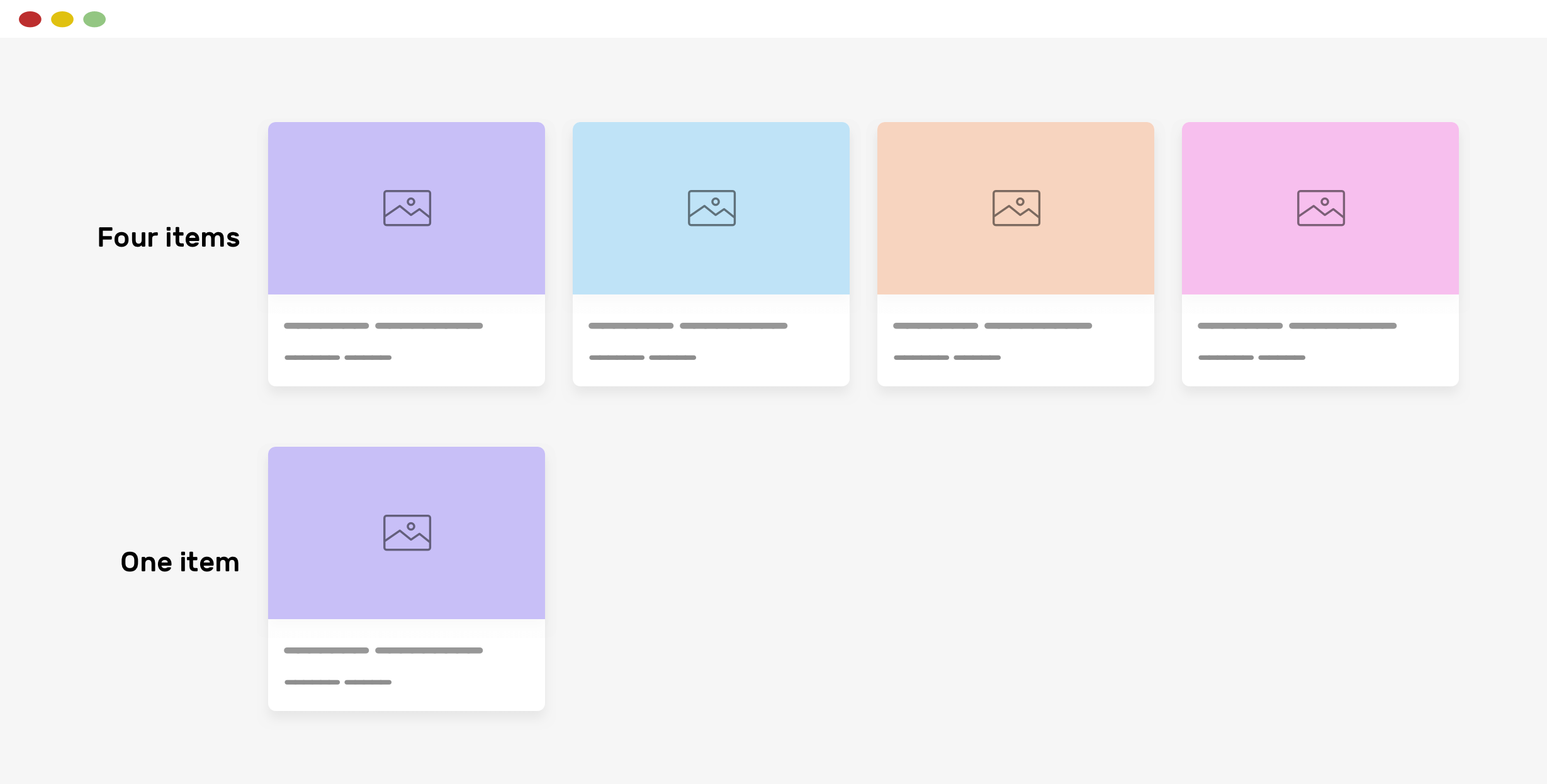 **Flex Sticky** ```css aside { align-self: start; position: sticky; top: 1rem; } ```  ##### Grouping Selectors It’s not recommended to group selectors that are meant to work with different browsers. For example, styling an input’s placeholder needs multiple selectors per the browser. If we group the selectors, the entire rule will be invalid, according to w3c. ```css /* Don't do this, please */ input::-webkit-input-placeholder, input:-moz-placeholder { color: #222; } /*Instead, do this.*/ input::-webkit-input-placeholder { color: #222; } input:-moz-placeholder { color: #222; } ``` ### Misc - [How To Create Your First Game - JavaScript](https://www.youtube.com/watch?v=47eXVRJKdkU) - Kyle is god. - [$1B+ Market Map: The World’s 936 Unicorn Companies In One Infographic](https://www.cbinsights.com/research/unicorn-startup-market-map)  - [v2ex | 问一个协程方面的问题](https://www.v2ex.com/t/821871) - concurrent 并发 - 多线程 - callback: callback hell - Promise / Future: java, scala, js - event loop ( c/c++ libev libuv + python gevent) - coroutine 协程: 对 event loop 的抽象 - 线程和协程核心的区别就是处理 IO 阻塞时的不同。 - 总的来说多线程就是你交给 CPU 很多个各式各样的任务,CPU 为了保证这些任务都能正常执行,不得不给每个任务分出一个时间片间隔执行,保证所有任务都在运行。多协程是你把多个任务的 DAG 图都画好了交给 CPU ,CPU 只需要按照你的图按部就班地线性的执行即可。